سیستم های تشخیص گفتار به همراه کد
مقدمه
گفتار برای بشر طبیعی ترین و کارآمدترین ابزار مبادله اطلاعات است.
کنترل محیط و ارتباط با ماشین بوسیله گفتار از آرزوهای او بوده است.
طراحی و تولید سیستم های تشخیص گفتار هدف تحقیقاتی مراکز بسیاری در نیم قرن اخیر بوده است.
یکی از اهداف انسانها در تولید چنین سیستم هایی مسلماً توجه به این نکته بوده است که ورود اطلاعات به صورت صوتی، اجرای دستورات علاوه بر صرفه جویی در وقت و هزینه ،به طرق مختلف کیفیت زندگی ما را افزایش می دهند.
امروزه دامنه ای از نرم افزارها (که تحت عنوان سیستم های تشخیص گفتار[1] معرفی می شوند) وجود دارند که این امکان را برای ماا فراهم کرده اند.
با استفاده از این تکنولوژی می توانیم امیدوار باشیم که چالش های ارتباطی خود را با محیط پیرامون به حداقل برسانیم.
یکی از کاربردهای اصلی اینگونه نرم افزارها بعنوان واسط بین انسان و رایانه است از آنجائیکه خیلی از کارهای بوسیله ارتباطات بصری بهتر حل می شود، گفتار هم دارای این توانایی است که یک نوع رابطه بهتر از صفحه کلید باشد مخصوصاً برای کارهایی که بصورت ارتباط زبان طبیعی هستند و یا بجای آن دسته از صفحه کلیدهایی که مناسب یک کار خاص نیستند بسیار مفید است کاربرد سیستم تشخیص گفتار شامل آن دسته از اعمال که در آنها چشم و دست مشغول هستند نیز می شود مانند مکانهایی که کاربر مجبوراست با دست عملی را انجام دهد یا تجهیزاتی را کنترل نماید (مانند کنترل پرواز برای خلبان یک هواپیما یا هنگام عمل جراحی یک پزشک متخصص).
ناحیه کاربردی دیگر که هم اکنون ازسیستم تشخیص گفتار استفاده می شود در تلفن است بعنوان مثال برای وارد کردن اعداد، تشخیص کلمه « الو» برای پذیرش تماس و .. سرانجام سیستم تشخیص گفتار در دیکته عملی شد که عبارتست از سخنرانی طولانی یک شخص ویژه.
این کاربرد هم در مکانهایی مثل دادگاهها و مکانهایی که نیاز به ثبت گفتگوهای طولانی دارند عملی شد و کاربرد بسیار مهم دیگر آن فناوری تشخیص هویت شخص گوینده و کنترل امنیتی برای ورود به قلمروهای اطلاعاتی محرمانه و دسترسی از راه دور به کامپیوترهای می باشد.
این فنآوری امکان تشخیص هویت شخص گوینده و در نتیجه امکان کنترل دسترسی او در هنگام استفاده از خدماتی همانند شمارهگیری صوتی، بانکداری تلفنی، خرید تلفنی، خدمات دسترسی به پایگاه دادهها، خدمات اطلاعاتی، پست الکترونیکی صوتی، کنترل امنیتی برای ورود به قلمروهای اطلاعاتی محرمانه و دسترسی از راه دور به کامپیوترها را فراهم میآورد.
علاوه بر موارد فوق که عموماً با کامپیوتر و کاربران آن سروکار دارند این فنآوری در مسائل قضایی نیز کاربردهای خاص خود را دارد.
تکنولوژی تشخیص گفتار یکی از پیچیده ترین تکنولوژیهاست که با وجود تلاش بسیاری از دانشمندان در سالهای گذشت هنوز کمی و کاستی هایی دارد.
هوش مصنوعی که یکی از گرایشات مهندسی کامپیوتر است بر روی اعمال مهم و خارق العاده و در عین حال ساده موجودات زنده متمرکز شده است و با الهام گرفتن از آنها سعی در حل مسائل بشر می کند با توجه به کاربردهای سیستم تشخیص گفتار که در بالا ذکر شد حتماً متوجه اهمیت موضوع شده اید ولی ایجاد چنین سیستمی احتیاج به سطح علمی و فکری بسیار بالایی دارد و با مباحث مهمی مانند پردازش سیگنال دیجیتال، پردازش صوت، آشنایی با قواعد زبانی و شکل شناسی، شبکه های عصبی، قواعد احتمالاتی، پردازش زبان طبیعی و … در ارتباط می باشد.
اهمیت موضوع یاد شده از یک سو و تازگی آن از سوی دیگر ما را بر آن داشت تا با راهنمایی استاد محترم جناب آقای مهندس یزدانجو موضوع پروژهی پایانی خود را مطالعه بر روی این گونه سیستمها و طراحی یک نمونه کوچک سیستم تشخیص گفتار وابسته به متن به عنوان نتیجهی عملی و این نوشتار به عنوان فراهم آورندهی پیشزمینههای علمی و توصیفکنندهی نحوهی عملکرد آن میباشد.
نکته اساسی:
قبل از پرداختن به به سیستم های تشخیص گفتار لازم است که فناوری تولید گفتار و تشخیص گفتار با تعریفی ساده از هم متمایز شوند:
● فناوری تولید گفتار[2]: تبدیل اطلاعاتی مثل متن یا سایر کدهای رایانه ای به گفتاراست.
مثل ماشین های متن خوان برای نابینایان، سیستم های پیغام رسانی عمومی. سیستم های تولید گفتار به خاطر سادگی ساختارشان زودتر ابداع شدند.
این نوع از فناوری پردازش گفتار موضوع مورد بحث در این پروژه نیستند.
● فناوری تشخیص گفتار[3]: نوعی فناوری است که به یک کامپیوتر این امکان را می دهد که گفتارو کلمات گوینده ای را که از طریق میکروفن یا پشت گوشی تلفن صحبت می کند، بازشناسی نماید.
به عبارت دیگر در این فناوری هدف خلق ماشینی است که گفتار را به عنوان ورودی دریافت کند و آنرا به اطلاعات مورد نیاز (مثل متن) تبدیل کند.
فصل اول: تعاریف– ضرورت ها – کاربردها
-
- تاریخچه فناوری تشخیص گفتار
اولین سیستم های مبتنی بر فناوری تشخیص گفتار در سال 1952 در”آزمایشگاههای بل” طراحی شد.
این سیستم به شیوه گفتار گسسته و به صورت وابسته به گوینده و با تعداد لغت محدود 10 لغت عمل می کرد.
در اوایل دهه 80 میلادی برای اولین بار الگوریتم مدلهای مخفی مارکوف[4] ارائه شد.اینن الگوریتم گامی مهم در طراحی سیستم های مبتنی بر گفتار پیوسته به حساب می آمد.
همچنین در طراحی این سیستم از مدل شبکه عصبی و نهایتاًً ازهوش مصنوعی نیز استفاده می شود.
در ابتدا شرکتهای تجاری این فناوری را برای کاربردهای خاصی طراحی کردند.
به عنوان مثال شرکت کورزویل[5] درر زمینه پزشکی و مخصوصاً برای کمک به معلولان و نابینایان و شرکت دراگون[6] در زمینه خودکارسازی سیستمهای اداری محصولات اولیه وارد بازارکردند.. توانجویان در واقع اولین گروهی بودند که از این دسته محصولات به عنوان یک فناوری انطباقی و یاریگر، عمدتاً برای دو عملکرد کنترل محیط و واژه پردازیی استفاده کردند.
جیمز بیکر[7] یکی از محققان شرکت IBM که در اواخر دهه 1970 در مورد این فناوری مقالات زیادی نوشت، یکی از پیشگامان این طرح بود.
او و همکارانش یک شرکت خصوصی به نام سیستم های دراگون[8] تاسیس کردند.
این شرکت ابتدا در دهه 1990 نرم افزاری به نام دراگون دیکتیت[9] تولید کرد که یکک سیستم مبتنی بر گفتار گسسته بود.
در سال 1997 این شرکت محصولی را تولید کرد که به جای استفاده از گفتارگسسته ،مبتنی بر گفتار پیوسته بود.
در واقع این شرکت با ارائه نرم افزار (DNS)[10] اولین سیستم تشخیص گفتار پیوسته را ارائه نمود.
این سیستم توانایی تشخیص گفتار با سرعت 160 کلمه درر دقیقه را داشت.
همچنین شرکت تجاری IBM هم در این زمینه برای سالهای متمادی فعالیت می کرد که با طراحی بسته نرم افزاری Via Voice به ارائهه سیستم های تشخیص گفتار پرداخت که در حال حاضر اسکن سافت[11] محصولات IBM Via Voice راتوزیع و پشتیبانی می کند.
شرکت مایکروسافت نیزز فعالیتهایی درجهت تولید و کاربرد این فناوری داشته است، و بیل گیتس[12] در کتابها و سخنرانی هایش به کرات در مورد آینده درخشان استفاده ازز سیستم های تشخیص گفتار تاکید کرده است.
البته عملاً تا قبل از ارائه نرم افزار آفیس XP [13] و ورد 2002[14] این تکنولوژی در محصولات این شرکتت بکاربرده نشد.
گرچه در ابتدا عمده موارد استفاده این تکنولوژی ،برای افراد توانجو پیش بینی شده بود اما بعدها پذیرش استفاده از آن گسترده تر شد وو گروههای بسیاری در مدارس و دانشگاهها علاقه مند به استفاده ازاین فناوری شدند.
بطوریکه دانشگاه استون هال[15] نیز برای تشویق دانشجویان بهه آشنایی با این سیستم به دانجشویان جدید الورود نرم افزار IBM Via Voicee را اهدا می کرد.
1-2- کاربردهای سیستم های تشخیص گفتار
ارزش ایجاد فنآوریهای تشخیص گفتار بسیار زیاد است.
صحبت سریعترین و کاراترین روش ارتباط انسانهاست.
ورود اطلاعات به صورت صوتی، اجرای دستورات علاوه برصرفه جویی در وقت و هزینه، به طرق مختلف کیفیت زندگی ما را افزایش می دهند.
و می تواند پتانسیل جایگزینی مناسبی برای نوشتن، تایپ، ورود صفحهکلید و کنترل الکترونیکی و اجرای دستورات توسط کلیدها و دکمهها اعمال میشود را داراست و امروزه دامنه ای از این نرم افزارها تحت عنوان سیستم های تشخیص گفتار[16] وجود دارند که این امکان را برای ما فراهم کرده اند.
با استفاده از این تکنولوژی می توانیم امیدوارر باشیم که چالش های ارتباطی خود را با محیط پیرامون به حداقل برسانیم.
و همانگونه که مشخص است توانايي سيستم در شناسايي گفتار و انواع آنن مي تواند کاربردهاي بسيار و در عين حال جالبي داشته باشد.
تشخیص صحبت فقط نیاز به آن دارد که کمی برای پذیرش توسط بازار تجاری بهتر کار کند. از جمله اين کاربردها مي توان به موارد زیر اشاره کرد:
1-2-1- استفاده از این تکنولوژی برای دیکته کردن و ایجاد مدرک:
از آنجایی که تایپ کامپیوتری از کارهای متداول و وقت گیربرای کاربرهای عادی و پیشرفته می باشد بنابراین اولین موارد استفاده از این تکنولوژی، تایپ کامپیوتری بوده است که باعث افزایش سهولت و سرعت تایپ می شده است مثل کاربرد این سیستم برای روزنامه نگاران و حقوقدانان.
رونویسی سخنرانی طولانی یک شخص ویژه (مکان دادگاهها و مکان هایی که نیاز به ثبت گفتگوهای طولانی عملی شد.) این امر به ویژه زمانی که افراد ملزم به تایپ مکرر هستند اهمیت پیدا می کند زیرا بیماری سندرم کانال مچی[17] که یکی از انواع آسیب های ناشی از تکرار می باشد در اثر استفاده تکرارر شونده از کیبورد برای تایپ پدید می آید.
با استفاده از سیستم های تشخیص صدا و تایپ با کیبورد به طور همزمان می توان از بروز اینگونه آسیب هاا جلوگیری کرد.

شکل1-1
همچنین افراد توانجو یا کسانی که به هر نحو قادر به تایپ کردن نمی باشند، می توانند خود را با این سیستم ها تطبیق دهند و از آنها بطور موثری استفاده کنند(به عنوان مثال افرادی که قادر به استفاده از دستان خود نیستند،یا از لحاظ بینایی دچار مشکل هستند).
حتی گزارش شده است که استفاده از یک نرم افزار تشخیص صدا به یک مرد مبتلا به بیماری “زبان پریشی” کمک کرده است که بتواند عقایدش را در قالب زبان نوشتاری بیان کند و با اطرافیان خود ارتباط برقرار کند.
1-2-2- استفاده از این نرم افزار برای ترجمه زبانها:
یکی از آژانس های پروژه های تحقیقاتی پیشرفته دفاعی آمریکا دارای سه تیم از محققانی است که بر روی GALE [18] که برنامه ای که اطلاعات روزنامه ها و اخبار پخش شده در زبانهای خارجی را ترجمه می کند،کار می کنند.
این پروژه امیدوار است که بتواند نرم افزاری ایجاد کند که بتواند دو زبان را باا حداقل 90 درصد دقت به یکدیگر ترجمه کند.
این آژانس همچنین بر روی یک پروژه تحقیقی و توسعه به نام TRANSTAC سرمایه گذاری کرده است که سربازان ایالات متحده امریکا را قادر می کند به شکل موثرتری با جمعیت غیر نظامی کشورهای غیر انگلیسی زبان به تعامل بپردازند.
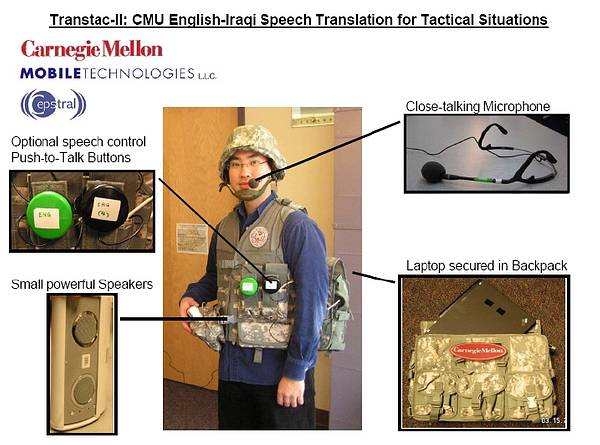
شکل1-2
1-2-3- فناوری تشخیص گفتار در راهبری سیستم های اطلاعاتی مالی و امنیتی
این فناوری به لحاظ ویژگی نهفته در آن یعنی اطلاعات یکتای موجود در موج صوتی صحبت هر فرد که احتمال مشابهت در افراد به صفر یا عددی نزدیک به آن است. مهمترین اساس برای طراحی سیستم های امنیتی وابسته به فرد خاص مورد استفاده قرار گرفته است.
 شکل1-3
شکل1-3
این فنآوری امکان تشخیص هویت شخص گوینده و در نتیجه امکان کنترل دسترسی او در هنگام استفاده از خدماتی همانند شمارهگیری صوتی، بانکداری تلفنی، خرید تلفنی، خدمات دسترسی به پایگاه دادهها، خدمات اطلاعاتی، پست الکترونیکی صوتی، کنترل امنیتی برای ورود به قلمروهای اطلاعاتی محرمانه و دسترسی از راه دور به کامپیوترها را فراهم میآورد.
1-2-4- استفاده در مکتوب کردن مستندات صوتي
به استفاده در نگارش اخبار و صورت جلسه ها ،استفاده در مکتوب کردن مستندات صوتي، ارسال فرامين صوتي، کاهش حجم داده ها و در نتيجه افزايش پهناي باند در مخابره گفتار و همچنين تنظيم متون و نامه هاي متني به کمک گفتار نام برد.
آنچه که مشخص است انسان تمايل دارد مستقيما گفتار را بصورت مکتوب تبديل نمايد و از وارد کردن نوشتار اجتناب نمايد.
از خصوصيات اینگونه سيستم می توان به توانايي شناسايي گفتار از دو منبع متفاوت، به صورت بلادرنگ از ميکروفن و يا تبديل فايل صوتي به متن، قابليت استفاده در محيطهاي متفاوت، امکان آموزش با گفتار کاربر، قابليت شناسايي تمام واژگان مصطلح در زبان فارسي (اعم از کلمات بيگانه) نام برد. انجام پروژه متلب
1-2-5- استفاده از فناوری تشخیص گفتار برای جایی که کاربر می تواند با ادا کردن دستورات آنها را انجام دهد:
تقریباً اولین گروهی که به استفاده از این فناوری روی آوردند، خلبانان بودند.
خلبانان در اتاقک پرواز با استفاده از این سیستم ها علاوه کمک به کنترل امور پرواز بدون نیاز به دست، استرس ناشی از پرواز را کاهش می دادند.
همچنین استفاده از این فناوری درحوزه های مشابه مانند فضا نوردی و هوانوردی نیزآزمایش شده است.
علاوه بر این توانجویان به طور وسیع این فناوری را به عنوان ابزاری برای کنترل محیط و انطباق بیشتر با آن بکار بردند.
به عنوان مثال توانجویان حرکتی قادر خواهند بود با کمک این فناوری دستورات حرکتی به صندلی چرخدار خود بدهند.
یا حتی در ایده ال ترین وضعیت به کمک کار گذاشتن تراشه های هوشمند و سازگار با فناوری تشخیص صدا در عضو مصنوعی به دست و پای مصنوعی خود فرمانهای حرکتی متنوع صادرکنند.

 شکل1-4
شکل1-4
1-2-6- استفاده از فناوری تشخیص گفتار در پزشکی :
استفاده از کامپیوتر را برای کلیه افراد ناتوان بدنی که دارای توانایی شنوایی و گفتاری مناسب هستند را آسان می کند به عنوان یک وسیلهی خروجی کاربرپسند در محیطهای مختلف میتواند با جایگزین کردن بسیاری از علائم دیداری (انواع چراغها و…) و شنوایی (انواع زنگهای اخطار و …) با گفتارهای بیان کنندهی کامل پیامها استفاده و رسیدگی به سیستمهای نیازمند این گونه پیامها را بهینه کند.
و موارد بیشمار کاربرد این فناوری در پزشکی به چشم می خورد.
1-2-7- ساده سازي ارتباط با سيستم گفتار تلفني
امروزه تلفن و سيستم هاي تلفني جزيي جدا نشدني از زندگي همه افراد است.
علاوه بر ايجاد ارتباطات مختلف گفتاري، در مرورگرهاي صوتي، سيستم هاي ارتباط با مشتري و IVR ها به شکل گسترده اي در شرکتها و ادارات به کار گرفته مي شوند.
با وجود کاربردهاي فراوان اين سيستم ها، محدوديت هاي مختلفي مانند نياز به پخش پيغام راهنماهاي زياد، سختي کار با تعداد بالاي انتخاب ها و مبتني بر تن بودن آنها در برخي کاربردها محدودتر کرده است.
اضافه کردن تشخيص خودکار گفتار، يکي از طبيعي ترين راه حل هاي رفع اين محدوديت هاست.


شکل1-5
تشخيص گفتارتلفني علاوه بر آسان ترکردن ارتباط مشتري با موسسات و مراکز مربوطه، کاهش هزينه و ارائه بهتر سرويس ها را به مشتريان به دنبال دارد.
اين قابليت به سادگي محاوره با اين سيستم ها و حل بيشتر مشکلات و محدوديت هاي آنها منجر مي شود.
تعدادي از نسخه هاي مختلف توسعه داده شده براي تشخيص گفتار تلفني به صورت زير است:
– منشي خودکار تلفني مبتني بر گفتار
– تشخيص اعداد و فرامين صوتي از پشت تلفن
– سيستم IVR تلفني مبتني بر گفتار براي بانکها
– تلفن گوياي اطلاع رساني سازمان ها، بهداشت و قرآن با قابليت تشخيص گفتار
دقت تشخيص بالاي 96 درصد، سرعت تشخيص بالا، پشتيباني از زبانهاي انگليسي و فارسي و کار با رابطهاي تلفني موجود مانند مودم و برد دیالاجیک[19] از ويژگي هاي منحصربه فرد اين سيستم ها هستند.
1-2-8- کاربرد فناوری تشخیص گفتار در کتابخانه
سیستم های تشخیص گفتار آنچنان که در حوزه های دیگر مثل پزشکی و انجمن های حقوقی مورد استفاده قرار گرفتند در کتابخانه ها بکار گرفته نشده اند و کتابخانه ها بیشتر موضعی منفعلانه نسبت به بکارگیری این فناوری از خود نشان داده اند.
اما با توجه به ماهیت خدمات کتابخانه ای و همچنین تنوع کاربرانی که تمایل به استفاده ازکتابخانه دارند مطمئناً وجود چنین فناوری کمک فراوانی به کتابداران در تسریع و بهبود خدمات کتابخانه ای می کند.
به عنوان مثال در کارهای خدماتی – فعالیت هایی که کتابدار به یک ابزار ارتباطی غیر از چشم ها و دست ها نیاز دارد- مثل رف خوانی و فهرست نویسی پیوسته، ویا در فعالیتهای مربوط به سرویسهای کتابخانه ای مثل بازیابی اطلاعات و کنترل فرایند امانت، و نهایتاً در ایجاد امکان دسترسی به پایگاه های اطلاعاتی از راه دور می تواند کاربرد موثری داشته باشد.
همچنین با استفاده از اینگونه سیستم ها می توان به نمایه سازی چند رسانه ای ها (مانند فیلم و ویدئو) پرداخت که دراین حالت کلمات کلیدی در قالب گفتار وارد می شوند و به صورت گفتارنیز بازیابی می شوند.
از سوی دیگر با ورود این فناوری به کتابخانه ها و فعالیتهای آن می توان انتظار داشت که کاربران کتابخانه بطور چشمگیری افزایش یابند، چرا که همیشه کاربرانی هستند که نمی توانند با سیستم معمول کتابخانه کار کنند و از منابع اطلاعاتی آن استفاده کنند.
این گروه کاربران می توانند کم سوادان و یا طیف وسیعی از توانجویان باشند که در صورت بکارگیری این فناوری آنها نیز با امکان دسترسی به منابع، جزوکاربران همیشگی کتابخانه ها می شوند.
1-2-9- استفاده از این فناوری برای تشخیص اعداد که بصورت گفتاری بیان شده باشند
مورد استفاده در بسیاری از کاربردها از جمله اعلام شماره شناسائی شخصی، شماره حساب بانکی، یا شماره عضویت برای کاربران یک سیستم خدمات رسانی، ارتباط با بانک اطلاعاتی از راه دور، ثبت نام دانشجویان از طریق تلفن یا اینترنت و مانند آن بسیار حائز اهمیت است.
البته توجه به این نکته که موارد بالا فقط گوشه ای از کاربردهای وسیعی این فناوری بر زندگی بشر دارد اهمیت ویژه ای دارد.
1-3- عملکرد سیستم های تشخیص گفتار
سیستم های تشخیص گفتار به هر منظور که بکار برده شوند، عملکرد نسبتاً مشابهی دارند که عبارت است از:

شکل -16
تبدیل گفتاربه داده
برای تبدیل گفتار به یک متن روی صفحه یا یک فرمان کامپیوتری، یک سیستم باید راه دشواری را طی کند.
وقتی که گوینده صحبت می کند، لرزشهایی در هوا ایجاد می شود، سیستم تشخیص گفتار ابتدا امواج صوتی آنالوگ را دریافت می کند، مبدل آنالوگ به دیجیتال (ADC)[20] این امواج آنالوگ را به دادهه های دیجیتالی تبدیل می کند.
سپس سیگنال به سگمنت های کوچکی که به اندازه چند صدم ثانیه یا در مورد صامت های بی صدا[21] چند هزارم یکک ثانیه هستند، تقسیم می شود.
در مرحله بعد برنامه این سگمنت ها را به واج[22] های شناخته شده در زبان تبدیل می کند.
واج ،کوچکترین عنصریک زبانن است (ارائه ای از صداهایی که ما می سازیم و برای شکل دادن واژه های معنی دار آنها را در کنار هم قرار می دهیم).
گام بعدی ساده به نظر می رسدد اما در واقع انجام آن بسیار دشوار است.
برنامه واج های موجود را با سایر واج هایی که درکنار آن قرار دارد، امتحان می کند و واج های هم بافت را از طریق یک مدل آماری بسیار پیچیده نقطه[23] می کند و آنها را با مجموعه بزرگی متشکل از واژه های شناخته شده، عبارات و جملات مقایسه می کند.
برنامه سپس چیزی را که کاربر احتمالاً گفته است مشخص می کند و آن را به عنوان متن یا شکل یک فرمان کامپیوتری یا صوت بیرون می دهد.
تشخیص گفتار با استفاده از مدل(الگوریتم)آماری
سیستم های تشخیص گفتار اولیه سعی داشتند مجوعه ای از قوانین گرامری و دستوری را با گفتار ورودی منطبق کنند.
به این صورت که اگر کلمه های گفته شده در داخل مجموعه ای از قواعد و قوانین جای می گرفتند و با آن سازگار می شدند، برنامه می توانست کلمه را تشخیص دهد.
تنوع لهجه ها ونوع گفتار افراد مختلف در این حالت از تشخیص می توانست تاثیر منفی بر روی دقت این سیستم ها بگذارد.
به عنون مثال تلفظ کلمه برن[24] توسطط فردی از بوستون و لندن متفاوت است در حالی که هر دو یک لغت را بکار برده اند.
سیستم ها مبتنی بر قواعد و قوانین دستوری به این دلیل موفق نبودندد که نمی توانستند گفتار ممتد را با حداقل میزان اشتباه تشخیص دهند.
سیستم های تشخیص گفتار امروزی از سیستم های مدل آماری بسیار قدرتمند و پیچیده ای استفاده می کنند.
این سیستم ها از قواعد احتمالات وریاضی برای تشخیص نتیجه استفاده می کنند.
دو مدل مسلط امروز در این حوزه مدل مخفی مارکوف[25] و مدل شبکه عصبی[26] هستند.
این روشها اساساً برای مشخص کردن اطلاعات پنهان از سیستم، از اطلاعاتی که برای سیستم شناخته شده هستند استفاده می کنند.
مدل مخفی مارکوف رایجج ترین مدل است.در این مدل هر واج مثل یک پیوند در یک زنجیره است و هنگامی این زنجیره تکمیل می شود، یک کلمه بوجود می آید.
در طی این فرایند، برنامه یک امتیاز[27] احتمالاتی را بر اساس دیکشنری توکار و آموزش کاربر به هر واج اختصاص می دهد.
این فرایند برای عبارات و جملات، حتی از این همم پیچیده تر است. (سیستم مجبور است مشخص کند که هر کلمه کجا شروع می شود و کجا به اتمام می رسد).
گاهی برنامه ناچار است عباراتی را کهه شنیده است را با عبارت یا عبارت های قبل ار آن که در بافت جمله هستند مقایسه کند، آن را تجزیه و تحلیل کند تا بتواند آنرا به درستی تشخیص دهد.
بنابراین اگر یک برنامه دارای 60000 کلمه باشد ترتیبی از سه کلمه می تواند هر یک از 216 تریلیون احتمال ممکن باشد.
بدیهی است که حتی قدرتمندترین سیستم هم نمی تواند بدون کمک، تمام این احتمالات را جستجو کند.
این کمک به شکل”آموزش”برنامه ارائه می شود.
با وجود اینکه توسعه دهندگان و طراحان نرم افزار که دستگاه واژگانی اصل سیستم را تنظیم می کنند، بخش اعظمی از این آموزش را انجام می دهند اما کاربر نهایی نیز باید زمان زیادی را صرف این آموزش کند.
1-4- انواع سیستمهای تشخیص گفتار
1-4-1- تقسیم بندی بر اساس عملکرد
فناوری تشخیص گفتار بر اساس سه معیارقابل بررسی و طبقه بندی است:
تعداد گویندگان
همانطور که قبلاً نیز اشاره شد، درونداد اطلاعات در این سیستم به صورت صوتی-گفتار انسان- است.
بسته به اینکه سیستم برای استفاده تعداد محدودی گوینده طراحی شده باشد یا نه، این سسیستم به دو دسته “وابسته به گوینده” و “مستقل از گوینده” تقسیم می شوند.
در سیستم های وابسته به گوینده، سیستم هر صدایی را تشخیص نمی دهد بلکه فقط صداهایی که قبلاً آنها را آموزش دیده است را تشخیص می دهد.
بدین صورت که شخص با ایجاد یک پروفایل صوتی از صدای خود، صدای خود را به سیستم آموزش می دهد و سیستم نیز با مراجعه به این پروفایل بار دیگر آن را تشخیص می دهد.این سیستم ها دقیق ترند.
اما سیستم های مستقل از گوینده طوری طراحی می شوند که سیستم قادر باشد هر نوع صدایی را تشخیص دهد.
شیوه صحبت کردن
نحوه صحبت کردن گوینده می تواند به دو صورت “گفتار گسسته” و یا “گفتار پیوسته” باشد.
در سیستم های مبتنی بر گفتار گسسته گوینده کلمات را جدا جدا و با مکث حداقل 200 میلی ثانیه بین آنها ادا می کند تا سیستم کلمات را بصورت مجزا تشخیص دهد.
در این نوع از سیستم بانک واژگان شامل کلماتی است که برای سیستم از قبل تعریف شده است.
وقتی که سیستم مبتنی بر گفتار پیوسته باشد، مرز کلمات گوینده واضح نیست که در این صورت برای انطباق گفتار با بانک واژگان، بانک واژگان از “واجهای” زبان تعریف شده تشکیل شده است.
اندازه بانک واژگان
اندازه بانک واژگان، از نظر واژگان ذخیره شده در سیستم ” محدود” و یا “بزرگ” است.
که بین نوع سیستم از نظر وابستگی به گوینده و اندازه بانک واژگان رابطه معکوس وجود دارد.
در سیستم های وابسته به گوینده اندازه بانک واژگان بزرگ و تعداد کاربر کم است.
این نوع سیستم ها که معمولا در محیط های تجاری بکار گرفته می شوند و تعداد کمی کاربر با این برنامه کار می کنند به بهترین نحو ممکن جوابگو هستند.
در حالی که این سیستم ها با سطح دقتی مناسب کار می کنند و دارای هزاران کلمه هستند باید طوری تنظیم شوند که با تعداد کوچکی از کاربران اصلی کار کنند و میزان دقت این سیستم ها تا حد بسیار زیادی به کاربر بستگی دارد.
در سیستم هایی که مستقل از گوینده عمل می کنند،تعداد کاربران زیاد است اما تعداد واژاگان اندک است.
در این سیستم ها کاربران می توانند با لهجه ها و الگوهای گوناگون تلفظ صحبت کنند هرچند، استفاده از این سیستم ها محدود به تعداد اندکی از فرامین و ورودی های از پیش تعریف شده نظیر گزینه های ابتدایی و اعداد است.
1-4-2- سیستم های تشخیص گفتار: تقسیم بندی بر اساس برونداد
سیستم های تشخیص گفتار همگی در یک ویژگی مشترک هستند و آن “لزوم درونداد به صورت صوتی” در این گونه سیستم هاست.
این سیستم ها را بر اساس بروندادی که ارائه می کنند می توانیم به سه دسته تقسیم بندی کنیم:
الف.سیستم های گفتار به متن[28]
ب. سیستم های گفتار به گفتار[29]
ج.سیستم های گفتار به فرامین[30]
که در ادامه هریک به طور مختصر معرفی می شوند.
گفتار به متن
این دسته از سیستم ها توانایی تبدیل گفتار به متن یا تشخیص خودکار گفتار را دارند.
از این تکنولوژی برای “دیکته کردن و ایجاد مدرک” استفاده می شود.
از آنجایی که تایپ کامپیوتری از کارهای متداول و وقت گیر برای کاربرهای عادی و پیشرفته می باشد بنابراین اولین موارد استفاده از این تکنولوژی، تایپ کامپیوتری بوده است که باعث افزایش سهولت و سرعت تایپ می شده است مثل کاربرد این سیستم برای روزنامه نگاران و حقوقدانان.
برخی نرم افزارها در زیر برای این نوع سیستم ها معرفی می شوند:
 شکل1-7
شکل1-7

شکل 1-8
- IBM Via Voice [31]: تنها نرم افزاری است که سیستم عامل لینوکس را پشتیبانی می کند.
- نرم اقزار مدل مخفی مارکوف می یر[32]: نرم افزاری است که توسط ریچارد می یر با الگوی HMM نوشته و طراحی شده است و برای کاربران حرفه ای کاربرد دارد.
- فناوری استفاده شده در ویندوز ویستا، فناوری استفاده شده در ویندوز XP که در قالب برنامه های ورد و ورد 2002 به بعد، ارائه شده است.
- نرم افزار دیکته خودکار فارسی/انگلیسی نویسا
- یک نرم افزار تشخیص گفتار به دو زبان فارسی و انگلیسی بدون وابستگی به گوینده است که توسط گروه SPl [33] در دانشگاه صنعتی شریف طراحی و تولید شده است. کاربرمی تواند از این نرم افزار در هر ویرایشگری در محیط ویندوز استفاده کند.
گفتار به گفتار
سیستم های گفتار به گفتار شامل استفاده از فناوری تشخیص گفتارعمدتاً در تولید نرم افزارهای ترجمه گفتار به گفتار می باشد.
شرکت Via یک مترجم زبانی را توسعه داده است که در اختیار انگلیسی زبانان قرار گرفته است که البته این محصول در تعداد انبوه وارد بازارنشده است.
نام این ابزار که نوعی سخت افزار است، “ابزار مترجم جهانی Via II” می باشد، وسیله ای است به اندازه یک گوشی تلفن با عملکرد PC که به کمر کاربر متصل می شود یا در جیب لباس وی قرار می گیرد.
Via II با یک نرم افزار تشخیص صدا سازگار است و با داشتن در گاه USB حتی امکان اتصال به ادوات جانبی را هم دارا است.
این ابزار با قدرت شناسایی مجموعه گسترده ای از زبانها نظیر کره ای، صربستانی، عربی، تایلندی، چینی،و… ارائه می شود.
این سیستم برای کاربران انگلیسی زبان طراحی شده است که قادر است صدای کاربر را شناسایی کندو به زبان مقصد ترجمه کندو از طریق بلندگو پخش کند و همچنین در مدت زمان کوتاهی قادر است که پاسخ فرد مخاطب را به انگلیسی ترجمه کند که به این ترتیب یک ترجمه دو طرفه انجام می شود.

شکل1- 9
موارد بالا نمونه هایی از تلاش محققان جهان برای توسعه این فناوری بودند.
در ایران و برای کاربران فارسی زبان نیز “نرم افزار پارسیا” طراحی و تولید شده است که یک نرم افزار ترجمه صوتی(گفتار به گفتار) زبان فارسی است و عبارات رایج و مکالمات روزمره فارسی را به زبانهای مقصد (انگلیسی و عربی) ترجمه می کند.
این نرم افزار توسط گروه SPL دانشگاه صنعتی شریف طراحی و تولید شده است.
گفتار به دستور
از این نوع فناوری برای کنترل برنامه ها[34] استفاده می شود.
با استفاده از این فناوری کاربر می تواند با ادا کردن دستورات آنها را انجام دهد.

شکل 1-10
با استفاده از این فناوری کاربر می تواند با گفتن جملات دستوری مانند” فایل را باز کن” یا “صفحه راببند” برنامه های مختلف کامپیوتری رانیزکنترل کند.
از این فناوری به همراه قابلیت تبدیل گفتار به متن در برخی سیستم های عامل استفاده شده است.
برخی از نرم افزارها در زیر آورده شده اند:
- C Voice Control [35]: در سیستم عامل لینوکس استفاده می شود و امکان اجرای دستورات را بوسیله فرامین صوتی فراهم می کند.
- کامندر گیم[36]: برنامه ای است مستقل از گوینده و بدون نیاز به آموزش که با ایجاد فرمانهای صوتی برخی بازی های مشهور ویندوز را کنترل می کند.
1-5- نمونه هایی از نرم افزارهای تشخیص گفتار طراحی و پیاده سازی شده :
نرم افزارهایی که در این زمینه ارائه شده بسیار زیاد می باشد که اگر به ذکر همه موارد بپردازیم شاید به صدها مورد برسد ولی در اینجا به چند نمونه خیلی کاربردی از این نرم افزارها که خوشبختانه اکثر آنها در ایران طراحی و ساخته شده اشاره می کنیم تا به اهمیت، وسعت و کاربرد این نرم افزارها پی ببریم:
1-5-1- طراحی و پیاده سازی سیستم نرم افزار فناوري بازشناسي گفتار توسط جمعي از متخصصين دانشگاه صنعتي شريف در زمينه پردازش گفتار (شيوهاي بسیار جديد براي تشخيص پيام ها و دستورهاي صوتي)

شکل1-11
عنوان طرح: فناوري بازشناسي گفتار مقاوم در برابر نويز
توضيح عمومي و كاربرد: با استفاده از اين فناوري، صداي ضبط شده توسط يك ميكروفون، بازشناسي شده و به فرامين براي يك دستگاه الكترونيكي يا رايانه، تبديل مي شوند. حوزه كاربرد اين فناوري، تمامي دستگاه هاي الكتريكي، الكترونيكي و رايانه اي است كه به طريقي از كاربر فرمان مي گيرند. تمام فرامين قابل بيان با استفاده از مجموعه متناهي كلمات گسسته را مي توان با استفاده از اين فناوري، توسط ميكروفون به دستگاه يا رايانه داد.
مزايا در مقايسه با ديگر فناوري هاي مشابه: مهم ترين خصوصيات اين فناوري، نياز به توان پردازشي بسيار كم و مقاومت بسيار زياد در مقابل سرو صداي محيط (نويز) است.
شرح طرح: روش ارائه شده، از سه بخش اصلي تشكيل شده است: 1. بخش اول كه وظيفه تبديل سيگنال صوتي به دادههاي قابل پردازش را براي دو بخش ديگر انجام ميدهد. 2. بخش دوم كه وظيفه يادگيري و توصيف كلمات را برعهده دارد و با گرفتن نمونههاي ضبط شده كلمات، الگوهاي لازم براي بخش بازشناسي را ميسازد. 3. بخش سوم كه دادههاي گرفته شده از بخش اول را با الگوهايي كه در بخش دوم ياد گرفته شدهاند، مقايسه ميكرده و شبيهترين كلمه را انتخاب ميكند.
از قابليت هاي این طرح آن است که از لحاظ سخت افزاري كوچك و از نظر هزينه مقرون به صرفه می باشد. ويژگي هاي منحصربه فرد اين طرح، آن را از جديدترين فناوري هاي موجود دنيا در زمينه پردازش گفتار، متمايز مي سازد.
از جمله ويژگي هاي اين طرح مي توان به موارد زير اشاره كرد:
قابل اجرا بر روي رايانه يا سخت افزاري مستقل، سهولت استفاده، هزينه اندك پياده سازي، عدم وابستگي به هيچ نوع زبان يا گويشي. عدم حساسيت به سروصداي محيط، امكان تعريف دستورهاي صوتي، مطابق با سليقه كاربرفناوري بازشناسي گفتار، برپايه اين ويژگي ها در طيف گسترده اي از محصولات قابل استفاده است. نمونه هايي از زمينه هاي كاربرد آن عبارتند از: خودروها، لوازم خانگي الكتريكي و الكترونيكي، اسباب بازي ها، عروسك ها و سرگرمي هاي رايانه اي، سيستم هاي دستيار افراد كم توان و سالخورده، نرم افزارهاي رايانه اي مديريتي، سيستم هاي آموزش زبان بهعنوان نمونه، از اين نرم افزار در دادن فرامين صوتي به خودرو بويژه هنگامي كه راننده مشغول رانندگي است و نمي تواند كار دستی ديگري انجام دهد، استفاده مي شود. فرامين صوتي شامل موارد ذيل مي شوند:
- تنظيم آينه هاي بغل و عقب 2. كنترل بالابر شيشه ها 3. كنترل قفل كودك 4. كنترل روغن ترمز و موتور يا بنزين در حال حركت 5. كنترل راديو يا هر نوع رسانه ديگر در خودرو 6. كنترل برف پاك كن ها 7. تنظيم صندلي ها 8. كنترل چراغ ها 9. هر نوع دستور ديگر كه انجام آن نيازمند حركت اضافي راننده و يا سرنشينان است.
اين نرم افزار، به خوبي در محيط پر نويز، عمل مي كند. مثلا، در خودرويي با سرعت 100 كيلومتر در ساعت با شيشه هاي باز و در بزرگراه، تست شده و پاسخ مناسب گرفته است. ديگر مزيت اين نرم افزار، حجم بسيار پايين آن است كه به راحتي قابل برنامه ريزي بر روي يك IC است (نسخه دمو روي کامپیوترهای جیبی[37] به راحتي تا 100 فرمان را پردازش مي كند). نرم افزار مورد بحث، با اين مشخصات، در ايران مشابه ندارد و موارد موجود در دنيا نيزز مانند ویس کامند[38] در میکروسافت آفیس[39] ، حداقل نياز به پردازنده پنتیوم[40] با حجم زياد حافظه دارند. نكته ديگر اينكه اين نرم افزار، هوشمند بوده وو قابل آموزش دادن است و پس از آموزش (مثلا با صداي اعضاي يك خانواده) صداي هر كدام از آنها را كه بشنود (و در كل هر زماني كه كلمه يا فرمان راا بشنود) مستقل از اين كه چه كسي آن را ادا كرده است (صداي زن يا مرد، كلفت يا نازك) فرمان را اجرا مي كند.
1-5-2- سامانه هوش مصنوعی پارسه با نام تجاری (پایس) مشاور رباتیک (سیستم پیشرفته ترین سیستم هوش مصنوعی جهان)
مهندس مولوی مخترع و نابغه جوان ایرانی دانش فنی پیشرفته ترین هوش مصنوعی جهان را با عنوان سامانه پارسه تولید کرد و امسال در فینال مسابقات جام جهانی رایانه در کشور چین با شکست مایکروسافت، آی.بی.ام، ناسا و کمپانی های بزرگ دنیا توانست مقام نایب قهرمانی را پس از اینتل کسب کند. در نخستین بار حضور ایران در مسابقات جام جهانی اختراعات رایانه ای و رقابت با کمپانی های بزرگ و غول های رایانه ای جهان همچون میکروسافت، اینتل، IBM و دانشگاه های بلند آوازه جهان توانسته است پس از گذراندن 4 مرحله مقدماتی، طرح برتر قاره، طرح برتر 3 قاره و نیمه نهایی به فینال این رقابت ها راه پیدا کند و پس از پشت سر گذاشتن طرح هایی مانند: سیستم کنترل تمام هوشمند ایستگاه بین المللی فضایی آژانس تحقیقات فضایی آمریکا (Nasa)، یک طرح از مایکروسافت، بمب هوشمند رباتیکی ارتش فیلیپین، صفحه مانیتور کریستالی با قطر یک برگ کاغذ کمپانی LG و سیستم خبره هوشمند پزشک فوق تخصص برای همه بیماری ها کمپانی فیلیپس مقام نایب قهرمانی را کسب کند. این سیستم پیشرفته ترین سیستم هوش مصنوعی جهان است این سیستم در مقام مشاور شهردار تهران می باشد. و شهردار تهران نخستین شهردار در کشورهای جهان است که از پیشرفته ترین سیستم هوش مصنوعی در دنیا بهره خواهد برد. این سیستم قابلیت ها و توانمندی های زیادی دارد که از آن جمله می توان به این ویژگی های منحصر به فرد اشاره کرد: اطلاعات و آمار و ارقام ده ها متخصص، دانشمند و کارشناس شهرداری را یکجا و به صورت همزمان و آنلاین ارائه کند و در اختیار بگذارد، شهردار نیز با یک میکروفون اطلاعات لازم را از آن بخواهد. از سوی دیگر، قرار است این سیستم به سامانه 137 شهرداری نیز سوئیچ و متصل شود و به نحوی آن را هوشمند کند، به این ترتیب جای تمام کسانی را که در این حوزه کار پاسخگویی را انجام می دهند، بگیرد. این سامانه توانایی گرفتن اطلاعات از شهروندان و پاسخگویی به آنها را دارد و از طرف دیگر به طور مستقیم آن را در اختیار شهردار قرار می دهد این سیستم هوشمند یا همان سامانه پارسه در حقیقت به عنوان مغز کنترل کننده شهر الکترونیکی و مجازی تهران وارد عمل خواهد شد. به عبارت بهتر پایه و بنیان اولیه شهر مجازی و الکترونیکی تهران که مغز کنترل کننده هوشمند آن است در حال حاضر آماده و راه اندازی شد و شهردار با رایانه متصل به این سیستم هوشمند همانند یک انسان می تواند صحبت کند و اطلاعات را بگیرد. سامانه هوش مصنوعی پارسه با نام تجاری (پایس) یک نرم افزار رایانه ای مبتنی بر فناوری هوش مصنوعی است که با داشتن قابلیت های خاص و منحصر به فرد توانسته است بسیاری از آرزو های بشر در زمینه رویای هوش مصنوعی و رباتیک را تا حد بالایی به واقعیت تبدیل کند. این سامانه که با بهره گیری از زبان های مختلف برنامه نویسی نوشته شده است، توانایی درک گفتار طبیعی انسان را به فارسی و انگلیسی و به صورت کاملا محاوره ای، تولید گفتار به زبان های فارسی و انگلیسی (سخن گفتن)، شناسایی گوینده و تصدیق هویت گوینده از روی گفتار، قابلیت دستور پذیری و انجام کامل تمامی دستورات و اعمال در محیط رایانه (سیستم عامل های ویندوز) را با استفاده از گفتار محاوره ای به زبان های فارسی و انگلیسی، امکان گفت وگو با یک تصویر که می تواند حتی تصویر خود کاربر باشد و سامانه به صورت خودکار آن را پویانمایی و به صورت هماهنگ با گفتار به حرکت در خواهد آورد، قابلیت تصمیم گیری و انتخاب مبتنی بر الگو و دانش قبلی، قابلیت استنتاج و استدلال مبتنی بر دانش، قابلیت یادگیری، قابلیت تشخیص و حذف نویز های مخرب در سیگنال گفتار، امکان تایپ گفتاری متون به فارسی و انگلیسی، قابلیت کار در محیط تمامی نرم افزار ها و بازی های رایانه ای بدون محدودیت و به صورت کاملا گفتاری و آن هم به صورت گفتار محاوره ای معمولی را در قالب یک نرم افزار جامع فراهم کرده است. برای مثال کاربرد این سامانه نرم افزاری روی رایانه بدین گونه است که هنگامی که شما این نرم افزار را روی سیستم خود نصب می کنید، می توانید بدون استفاده از صفحه کلید و موس با رایانه کار کنید؛ بدین صورت که شما با گفتار محاوره ای و بسیار معمولی(همانگونه که در طول روز با دیگران صحبت می کنید، البته با در نظر گرفتن اینکه سیستم نمی تواند اصطلاحات شما را متوجه شود) می توانید با رایانه کار کنید. بدین معنا که مثلا برای باز کردن برنامه فتوشاپ فقط کافی است که به سیستم بگویید فتوشاپ روباز کن! تا این عمل انجام شود. البته سیستم های دستور دهی صوتی در جهان بسیار کار شده اند، اما تفاوت این سامانه با آنها این است که در آن سیستم های گذشته نمی توان گفت که کل سیستم به صورت گفتار کار می کند بلکه آنها مثلا در بازی های رایانه ای و یا محیط داخلی نرم افزار ها عمل نمی کردند ولی سامانه هوش مصنوعی پارسه کاملا و می توانم بگویم به طور قطعی صفحه کلید و موس را از رایانه حذف می کند. مزیت بارز دیگر این سیستم در این است که درصد تشخیص گفتار آن بسیار بالا و خطای آن بسیار پایین است و تقریبا تمامی گفتار شما را متوجه می شود. همچنین شما می توانید با آن به طور محاوره ای و معمولی سخن بگویید و سیستم به طور هوشمند متوجه خواسته شما خواهد شد. همچنین در این سیستم شما می توانید با تصویر پویانمایی شده یک صورت صحبت کنید، درد دل کنید، از آن مشاوره بخواهید و همچنین به آن دستور بدهید تا آن هم با شما صحبت کند و عکس العمل نشان دهد. سیستم می تواند سیگنال گفتار شما را شناسایی و شما را تشخیص هویت کند و بسیاری از قابلیت های دیگر که باعث کاربردی تر شدن آن در رایانه می شود. برای مثال اگر شما می خواهید در رایانه متنی را تایپ کنید کافی است به رایانه دستور دهید که مثلا زودباش برنامه ورد را باز کن. یا مثلا بگویید می خواهم یک متن را تایپ کنم. تا سیستم آماده تایپ شود و سپس شما متن خود را بخوانید تا سیستم آن را تایپ کند و در آخر آن را غلط گیری کنید و دستور چاپ آن را بدهید؛ این یک نوع عملکرد این سیستم است و بسیاری از کاربردها و قابلیت های دیگر و مهم این سیستم آن است که سامانه هوش مصنوعی پارسه به دلیل برخورداری از قدرت انتخاب، تصمیم گیری، استدلال و استنتاج و همچنین بازشناسی الگو و به طور عامیانه استفاده از تجربه قبلی می تواند به عنوان یک سیستم هوشمند در هواپیما، اتومبیل، سیستم های فضایی، و… به عنوان کنترل کننده جایگزین انسان گردد. همچنین نصب این سیستم بر روی تلویزیون با موفقیت صورت پذیرفت. تلویزیون های هوشمند طرح پارسه می توانند بدون وجود ریموت کنترل و فقط به صورت گفتاری کنترل شوند، می توانند با شما گفت وگوکنند و با شما صحبت کنند و همچنین شما می توانید تصویر صورت خود را به وسیله یک حافظه فلش به تلویزیون بدهید تا سیستم به طور خودکار آن را پویا نمایی و سخنگو کند و شما بتوانید با آن عکس صحبت کنید.
1-5-3- نرم افزار مترجم صوتی گفتار به گفتار زبان فارسی پارسیا:
این نرم افزار تشخیص گفتار مستقل از گوینده، امکان ترجمه مستقیم گفتار فارسی به گفتار معادل در زبان های انگلیسی و عربی فراهم شد. (مهندس باقر بابا علی، دانشجوی دکتری کامپیوتر دانشگاه صنعتی شریف و مدیر بخش تحقیقات شرکت SPL دانشگاه صنعتی شریف سازنده این نرم افزار) درباره کاربردهای نرم افزار افراد می توانند بدون دانستن زبان خارجی نیازهای ابتدایی خود را برآورده کنند. برای مثال برای پرسیدن ساعت صبحانه، مراکز خرید، یک رستوران خوب یا قیمت لباس می توان به زبان فارسی صحبت کرد و رایانه بعد از درک کلمه، معادل آن در زبان مقصد را بیان می کند. جنبه دیگر این نرم افزار کمک به آموزش زبان و یادگیری عبارات مورد استفاده در مکالمات روزمره است . در مترجم صوتی گفتار به گفتار «پارسیا» جملات و عبارات بیان شده توسط کاربر مستقیما به گفتار معادل در زبان های انگلیسی و عربی ترجمه و بیان می شود تا به زبان مورد نظر ترجمه شود. در نسخه جاری این نرم افزار گفتار فارسی مستقیما به گفتار معادل در زبانهای انگلیسی و عربی ترجمه می شود. ویژگی و هسته اصلی این مترجم، یک سیستم تشخیص خودکار گفتار فارسی است که گفتار کاربر را پردازش کرده و آن را تشخیص می دهد، سپس گفتار تشخیص داده شده به معادل خود در زبان مقصد برگردانده می شود. این ویژگی «پارسیا» را به عنوان اولین نرم افزار فارسی با قابلیت تشخیص گفتار از همه نرم افزارهای دیگر متمایز می کند. این نرم افزار در دو نسخه قابل نصب نسخه روی pc و قابل نصب کامپیوترهای جیبی (pda) توسعه داده شده است .
1-5-4- نرم افزار نویسا:
متخصصان شرکت تحقیقات دانشگاه شریف با دستیابی به فن آوری طراحی و ساخت نرم افزار تشخیص گفتار مستقل از گوینده، نرم افزاری نیز برای تایپ گفتار فارسی طراحی کرده اند که قادر است گفتار کاربران را که از طریق میکروفن به رایانه منتقل می شود به در محیط ورد، نت پد[41] یا هر صفحهه ویرایشی که امکان تایپ فارسی در آن وجود دارد، بنویسد.
از کاربردهای جانبی این سیستم – علاوه بر استفاده به جای تاپیست -، استفاده توسط پزشکان جهت تهیه گزارش یا نسخه ی دارو، نوشتن اسناد حقوقی توسط وکلا یا تایپ سایر متون تخصصی در زمینه های مختلف است که در این راستا نسخه تخصصی نرم افزار نویسا (تایپ گفتاری) به منظور استفاده متخصصان قلب در نوشتن نسخه توسعه داده شده که این قبیل نمونه های تخصصی نرم افزار به دلیل اختصاصی بودن و کاهش دامنه کلمات از دقت و کارایی به مراتب بالاتری برخوردارند.
مزیتهای استفاده از سیستم تایپ گفتاری نویسا:
صرفهجویی در زمان، کاهش هزینه، افزایش سرعت تایپ و ورود اطلاعات، حفظ امنیت اطلاعات در هنگام ورود دادهها، قابلیت استفاده در بسیاری از سیستمهای (مستندسازی، ترجمه گفتاری و …)، جلوگیری از اشتباهات تایپی یک نسخه از این سیستم بر روی یک رایانه نصب میشود و میتواند با صدای کاربران آموزش داده شود. این سیستم دارای لوازم جانبی از جمله میکروفن ویژه تشخیص گفتار میباشد. این سیستم شامل نصب و آموزش در محل به صورت رایگان میباشد. سیستم شامل 18 ماه ضمانت و 5 سال خدمات پس از فروش میباشد. پشتیبانی سرویس دهنده تا 6 ماه رایگان میباشد اما پشتیبانی[42] ها شامل هزینه میباشد.
مشخصات و ویژگیهای سامانه تایپ گفتاری نویسا به صورت زیر است:
دقت تشخیص 95% در محیط اداری، تشخیص و تایپ متن به صورت بی درنگ، قابلیت تشخیص جملات به صورت طبیعی و پیوسته شامل حدود 21 هزار کلمه پر کاربرد زبان فارسی، دارای ویرایشگر ویژه جهت استفاده برای تایپ گفتاری و ویرایش راحتتر قابلیت استفاده در اغلب محیطهای تایپ رایج مانند میکروسافت ورد[43]، نت پد[44] و …، قابلیت استفاده در فرمها یا قسمتهایی که امکان تایپ فارسی دارند، قابلیت ویرایش متون در هنگام تایپ گفتاری یاا بعد از آن، امکان استفاده از تایپ برای کلمات خاص، لاتین یا عربی در هنگام استفاده از سیستم گفتاری، قابلیت اضافه نمودن کلماتی که در بانک کلماتت سیستم موجود نیستند (مانند اسامی خاص)، قابلیت تشخیص علایم خاص مانند نقطه، علامت سوال و علامت تعجب به صورت صوتی، علاوه بر اطلاعات آوایی، در این سیستم مشابه انسان، از اطلاعات زبانی مانند معنی و ترتیب کلمات برای فهم جمله بیان شده استفاده شده است. قابلیت تخصصی نمودن دایره کلمات برای کاربردهای خاص وجود دارد و کلمات تخصصی یا کلمات خاص به سیستم اضافه میشود. همچنین میتوان سیستم را با متنهای آن کاربرد خاص تطبیق نمود تا کارایی سیستم برای این منظور بهبود یابد. اختصاصی نمودن سیستم برای کاربردهای خاص مستلزم هزینه اضافی است که به هزینه سیستم اضافه میشود.
قابلیت تطبیق و آموزش به گوینده یا محیط خاص، استفاده از دستور زبان و سایر اطلاعات زبانی، راحتی و سادگی واسط گرافیگی کاربر، واسط کاربر دو زبانه (انگلیسی و فارسی)
1-5-5- نرم افزار مبتنی بر سیستم تشخیص گفتار پیوسته فارسی نرم افزار «نیوشا» :
شرکت عصر گویش پرداز نرم افزار تشخیص گفتار از پشت تلفن را طراحی و پیاده سازی کرده است استفاده از نرم افزار تشخیص گفتار تلفنی در موسسات و ادارات علاوه بر تسهیل ارتباط مشتری با آنها به کاهش هزینه و ارائه بهتر خدمات به مشتریان منجر می شود. این قابلیت به تسهیل محاوره و حل برخی از مشکلات مربوط به استفاده از سیستم های مبتنی بر «تن» منجر می شود. کار با تعداد کلمات زیاد، استفاده از تلفن های «پالس» و «تن» و جلوگیری از شماره گیری های وسط مکالمه از جمله مزیتهای دیگر این سیستمهاست. منشی خودکار تلفنی مبتنی بر گفتار، تشخیص اعداد فرامین صوتی از پشت تلفن، سیستم IVR تلفنی مبتنی بر گفتار برای بانک ها، سیستم اطلاع رسانی تلفنی مبتنی بر گفتار برای سازمان ها و تلفن های گویای «ندای سلامت» و «ندای قرآن» را از جمله نسخه های توسعه داده شده سیستم تشخیص گفتار تلفنی «نیوشا» عنوان کرد. سیستم های تشخیص گفتار طراحی شده دارای ویژگی های منحصر به فردی هستند، کارایی بالا در شرایط مختلف، سرعت تشخیص بالا، مستقل از گوینده بودن، پشتیبانی از زبان های فارسی و انگلیسی، قابلیت اضافه شدن به عنوان یک واحدمجزا به سیستم های تلفنی موجود و کار با رابطهای تلفنی موجود مانند مودم و برد دیالجیک را از جمله این ویژگی ها عنوان می شود .
1-5-6- [45] C Voice Control: در سیستم عامل لینوکس استفاده می شود و امکان اجرای دستورات را بوسیله فرامین صوتی فراهم می کند.
1-5-7- کامندر گیم[46]: برنامه ای است مستقل از گوینده و بدون نیاز به آموزش که با ایجاد فرمانهای صوتی برخی بازی های مشهور ویندوز را کنترل می کند.
1-5-8- IBM Via Voice[47] : تنها نرم افزاری است که سیستم عامل لینوکس را پشتیبانی می کند.
1-5-9- نرم افزار مدل مخفی مارکوف می یر[48]: نرم افزاری است که توسط ریچارد می یر با الگوی HMM نوشته و طراحی شده است و برای کاربران حرفه ای کاربرد دارد.
1-5-10- فناوری استفاده شده در ویندوز ویستا و ویندوز XP :که در قالب برنامه های ورد XP و ورد 2002 به بعد، ارائه شده است.
1-5-11- ابزار مترجم جهانی Via II : شرکت Via یک مترجم زبانی را توسعه داده است که در اختیار انگلیسی زبانان قرار گرفته است که البته این محصول در تعداد انبوه وارد بازارنشده است.این ابزار که نوعی سخت افزار است وسیله ای به اندازه یک گوشی تلفن با عملکرد PC که به کمر کاربر متصلل می شود یا در جیب لباس وی قرار می گیرد.Via II با یک نرم افزار تشخیص صدا سازگار است و با داشتن در گاه USB حتی امکان اتصال به ادوات جانبی را هم دارا است.این ابزار با قدرت شناسایی مجموعه گسترده ای از زبانها نظیر کره ای،صربستانی،عربی،تایلندی،چینی،و… ارائه می شود .این سیستم برای کاربران انگلیسی زبان طراحی شده است که قادر است صدای کاربر را شناسایی کندو به زبان مقصد ترجمه کندو از طریق بلندگو پخش کند و همچنین در مدت زمان کوتاهی قادر است که پاسخ فرد مخاطب را به انگلیسی ترجمه کند که به این ترتیب یک ترجمه دو طرفه انجام می شود.
1-5-12- فناوری تشخیص گفتاری برای کودکان
يکي از کاربرد هاي جالب موتور تشخيص گفتار، قابليت استفاده از آن توسط کودکان مي باشد. براي رسيدن به اين منظور شرکت عصر گويش پرداز اين موتور تشخيص را در قالب يک بازي سرگرم کننده براي کودکان مورد استفاده قرار داده است. ساختار اين نرم افزار در قالب يک داستان مي باشد که کودک به عنوان شخصيت اول آن (به اسم علي) در جريان بازي قرار مي گيرد. طي اين بازي کودکان بيش از 50 کلمه پرکاربرد زبان انگليسي را آموزش مي بينند و در کنار آن اطلاعات عمومي و روحيه همکاري نيز به او آموزش داده مي شود.

شکل 1-12
کاربرد موتور تشخيص گفتار در اين نرم افزار به اين صورت است که در طول بازي براي عبور از هر مرحله کودک بايد به تعدادي سوال از کلمات انگليسي اي که تا کنون ياد گرفته پاسخ درست بدهد. پاسخ دادن به اين سوالات به اين صورت است که جواب سوال به وسيله ميکروفوني که همراه اين نرم افزار عرضه مي شود بيان مي گردد و موتور تشخيص صحت آن را تشخيص مي دهد.
استفاده از قابليت تشخيص گفتار براي کودکان و اجراي آن در قالب بازي براي اولين بار روي زبان فارسي صورت گرفته است که اين مطلب باعث تمايز چشم گير اين نرم افزار از ساير نرم افزار هاي کودکان گرديده است. دقت بالاي تشخيص کلمات و قابليت انعطاف و راحتي کار با نرم افزار از مزيت هاي اين بازي هستند.
1-5-13- ساخت دستگاه هوشمند جهت جداسازی پسته های پوک از مغزدار با استفاده از پردازش صدا و شبکه های عصبی :
اجزای این دستگاه شامل جعبه صدا، میکروفن، نرم افزار پردازش سیگنال، مکانیسم انتقال و جداسازی پسته می باشد انعکاس صدای برخورد پسته با یک صفحه فولادی در حالت آف لاین[49] از دو ارتفاع برخورد 25 سانتیمتر و 35 سانتیمتری توسط سیستم خودکار استحصال داده توسط میکروفن جمع آوری وو به رایانه منتقل می شود سیگنال های صدای برخورد در دو حوزه زمان، فرکانس مورد پردازش قرار گرفته و در هر حوزه بردارها مشخصات مناسب استخراجج می شود از شبکه عصبی پرسپترون چند لایه جهت جداسازی استفاده شده است. این دستگاه پسته های پوک را دقت 93 درصد و پسته های مغزدار را با دقت 94 درصد جدا می سازند.
1-5-14- تلفنی که دستورات گفتاری کاربر را اجرا می کند:
تلفن همراه SPH-p207 ساخته شرکت سامسونگ دارای نرم افزاری تشخیص گفتار است که بر این اساس به پیام های گفتاری سریعتر از تایپ کردن آنها روی صفحه شماره گیری جواب می دهد.
وظیفه اصلی این تلفن بی سیم تبدیل گفتار انسان به سیگنال های دیجیتالی و بالعکس می باشد استفاده از دستورات گفتاری برای شماره گیری و کنترل سایر وظایف در بعضی از گوشی های گران قیمت متداول بوده است. اما تلفن SPH-p207 سامسونگ اولین تلفنی است که از فناوری تشخیص گفتار برای دیکته یک متن استفاده می کند. قیمت این گوشی 200 دلار است و با شرکت وایرلس سینگیولار[50] قرار داد دو ساله دارد .
1-5-15- دقت 99 درصدي نرمافزارهاي تشخيص صدا:
شركت اسكن سافت, نرم افزار جديد تشخيص صداي خود را با دقت بسيار بالاتر طراحی کرد نرمافزار تشخيص صدا را تحت عنوان[51]DNP8 به بازار عرضه كرد. اين شركت آمريكايي ادعا ميكند: نمونه جديد در ضبط صداي كاربر نسبت به نمونه قبلي 25 درصد دقيقتر عمل ميكند. شركت اسكن سافت, با ادعاي اينكه نرمافزار جديد در 99 درصد موارد صداي كاربران را به طور دقيق ضبط و پردازش ميكند، اعلام كرد: كاربران ميتوانند صداي خود را بر روي تنگستن[52] يا ديگر تجهيزات نظيرPC هاي جيبي و تجهيزات ضبط ديجيتالC ضبط كنند و بعد با انتقال آن به نرم افزار جديد اين شركت آن را به متن تبديلل كنند
-
-
- استفاده مایکروسافت از فناوری تشخیص گفتار:
-
این شرکت سال قبل شرکت نتورکس تل می[53] را خرید. حال با ترکیب فناوری تشخیص گفتار این شرکت با سرویس های موقعیت یاب جهانی (GPS) تحولی در این زمینه ایجاد کرده طوری که کاربران سرویس مذکور با گفتن کلمه «سینما» به نزدیک ترین سینمای محل حضورشان راهنمایی خواهند شد.. آنها می توانند فقط با گفتن نام فیلمی که خواستار دیدنش هستند، پیش از رسیدن به محل سینما بلیط آن رزرو کنند.
همچنین این شرکت فناوری تشخیص گفتار خودروی جدید شرکت فورد را نشان داد. در این خودرو می توان به جای دست با استفاده از گفتار، دستگاه پخش کننده موسیقی را کنترل کرد یا به دستگاه موقعیت یاب فرمان داد. همچنین می توان از طریق وصل کردن گوشی موبایل به ماشین به صورت بی سیم و از طریق بلوتوث، با گفتن نام هر یک افراد ثبت شده در دفترچه تلفن با او تماس برقرار کرد. این فناوری Sync نام دارد و تخمین می زنند که تا سال 2009 حدود یک میلیون ماشین دارای Sync را به فروش رسانده باشد.
1-6- ضعف ها و محدودیت های سیستم های تشخیص گفتار
هیچ برنامه تشخیص گفتاری که بتواند صددرصد درست عمل کند وجود ندارد، چندین عامل وجود دارند که می توانند میزان دقت این برنامه ها را کاهش دهند و یا استفاده از آنها را محدود کنند:
1-6-1- ورود سرو صدای محیط[54]

شکل1-13
برنامه باید واژه هایی که ادا می شوند به طور واضح بشنود هرنوع صدای اضافی همزمان با صدای گوینده وارد شود می تواند با واجهای صوتی اشتباه گرفته شود و در این فرایند تداخل ایجاد کند. منبع ایجاد نویز می تواند بسیار گوناگون باشد. مثل نویز موجود در صدای پس زمینه دریک محیط اداری و شلوغ که برای حذف آنها درهنگام استفاده کاربران باید در یک مکان نسبتاً آرام مستقر شوند و از میکروفن با کیفیت (مثل میکروفونهای نویز پخ[55]) استفاده کنند و یا در هنگام صحبت میکروفن را در نزدیکی دهان خود قرار دهند.
گاهی نیز کارت های صوتی کیفیت پایین باعث کم شدن دقت سیستم می شوند این کارت ها اغلب فاقد لایه محافظ در برابر سیگنال الکتریکی ایجاد شده توسط سایر اجزای کامپیوتر هستند و می توانند صدای هوم یا هیس را به سیگنال (صوتی) وارد کنند.
امروزه با بکار گیری” نرم افزار بهبود کیفیت ” به همراه این فناوری تا حد زیادی سروصدای محیط و خش های اضافی قابل حذف شدن می باشد. این محصول می تواند هم به صورت نرم افزاری مستقل مورد استفاده قرار گیرد و هم به صورت یک امکان مجزا برای بهبود کیفیت گفتار و در نتیجه بهبود کارایی و دقت در نرم افزارهای دیگر بکار گرفته شود. این نرم افزار یکی از محصولات گروه SPL دانشگاه صنعتی شریف می باشد.
1-6-2- اثرگذاری کلمات بر یکدیگر و نحوه تلفظ آنها

شکل1-14
اثر گذاری کلمات بر روی همدیگر هنگام ادا شدن توسط گوینده ها وحتی حذف شدن واج های ابتدایی و انتهایی هنگام چسبیدن کلمات به هم کار تشخیص را مشکل می سازد. همچنین نحوه تلفظ کلمات توسط افراد مختلف و وجود لهجه های گوناگون بر دقت سیستم تاثیر می گذارند. در یک محیط کاری ،کاربران اصلی برنامه باید زمان نسبتاً زیادی را صرف صحبت کردن در سیستم کنند تا سیستم را با الگوی تلفظی خود آموزش دهند و آنرا با گفتار خود هماهنگ کنند. همچنین آنها باید سیستم را با واژه ها، اصطلاحات و کلمات مترادف ویژه ای که در آن محیط استفاده می کنند،آموزش دهند. نسخه های ویژه ای از برنامه های تشخیص صدا (که معمولاً وابسته به گوینده هستند) برای دفاتر قانونی یا مراکز درمانی وجود دارد که دارای واژه های مصطلح و رایجی که در این محیط ها بکار برده می شوند هستند.
1-6-3-کلمات متشابه[56]
کلمات مشابه واژه هایی هستند که از نظر تلفظ شبیه هم هستند اما از نظر معنی و ریشه و گاهی املا با هم فرق دارند.there ،their، air ،heir ؛ be و bee مثال هایی از این نوع کلمات هستند. هیچ راهی برای یک برنامه تشخیص صدا وجود ندارد که بتواند بطور دقیق تفاوت بین این واژه ها را بر اساس صدا به تنهای تشخیص دهد. هرچند که آموزش های بسیار زیاد سیستم ها و مدلهای آماری که امروزه به کار می رود تا حد زیادی کارایی این برنامه ها را افزایش داده است.
1-6-4- ایجاد سرو صدا
ایجاد سرو صدا یکی از محدودیت های این سیستم ها است. با توجه به لزوم تعامل صوتی انسان با این سیستم در هنگام استفاده این مشکل امری طبیعی است ولیکن برای کاهش مزاحمت و افزایش کارایی بهتر است که از این فناوری در محیط های خاص دربسته و مجزا استفاده شود. محدودیت دیگری که هنگام کار با این سیستم با آن مواجه می شویم خطر فاش شدن اطلاعات شخصی و محرمانه هنگام ورود اطلاعات است. یک راه ابتکاری و البته معقول وجود دارد و آن استفاده از ماسک های مخصوص مجهز به میکروفن حساس است. با استفاده از این ماسک ها می توان با پایین ترین فرکانس صوتی ممکن صحبت کرد به طوری که دیگران صدای ما را نشنوند ودر عین حال مطمئن باشیم که صدای ما از طریق میکروفن وارد شده است.
1-7- اصول تشخیص و سنتز گفتار
اصول تشخیص و سنتز گفتار در 5 مرحله انجام مي گيرد :
1- ورودي كاربر :
در اين مرحله، كاربر خواستة خود را بصورت بيان چند كلمه يا عبارت بيان مي كند. سيستم تشخيص گفتار، صداي كاربر رابصورت يك سيگنال صوتي آنالوگ ضبط مي كند.
2- رقمي سازي[57]
در اين مرحله، سيگنال صوتي آنالوگ به سيگنال ديجيتال تبديل مي شود.
3- تجزية اجزاي صدا[58]
نرم افزار تشخيص گفتار، سيگنال ديجيتال را به اجزاي اصلي تشكيل دهندة گفتار تجزيه مي كند. به عنوان مثال حروف صدا دار و بي صدا را تشخيص مي دهد.
هر زبان مجموعه اي از صداهاي مختلف تشكيل شده است كه به هر كدام از اين اصوات يك واج گفته مي شود. تركيب واجها سيلاب يا هجاء را تشكيل مي دهد و از تركيب چند هجاء لغات به وجود مي آيند. هر واج را مي توان بصورتي يك الگوي مشخص در دستگاه اسپكتروگرام شناسايي كرد. تشخيص هر واج نيازمند به تمركز زيادي بر روي انرژي صوت دارد كه آن را فرمانت[59] مي نامند. فرمانت داراي خصوصيات افزايش و كاهش تدريجي[60] در تمامم فركانسها مي باشد كه يكي از ويژگي هاي برجستة صداي انسان است.
اسپكتروگرام در تحليل صدا به ما كمك مي كند. گفتار انسان از نوسانات صوتي حنجره ايجاد مي شود. اگرچه واجها در يك موج صوتي قابل شناسايي نيستند، اما موج صوتي را مي توان به فركانسهاي تشكيل دهندة آن تجزيه كرد و در يك اسپكتروگرام آن را نمايش داد. محور عمودي در اسپكتروگرام فركانسهاي بالاي 8000 هرتز را نمايش مي دهد و محور افقي بيانگر گذشت زمان مي باشد. رنگها نشانگر اهميت قله هاي صوتي صدا مي باشند. تغيير واجهاي يك لغت معني آن لغت را تغيير مي دهد. به عنوان مثال تفاوت دو كلمة Fat و Vat در يك واج مي باشدكه تغيير آن باعث تغيير معني لغت مي شود. در زبانهاي مختلف، لهجه هاي مختلف باعث تلفظ لغات بصورت مختلف مي شود. در زبان انگليسي 38 واج وجود دارد.
4- مدل كردن آماري
بعد از انجام مراحل فوق سيستم مشغول به تطبيق صداها با صداهاي تعريف شده در خودش مي شود. از
يك واژه نامه براي نگه داشتن طرز تلفظ لغات استفاده مي شود. ماشين تشخيص گفتار از اين فرهنگ، استفاده مي كند.
5- تطبيق دادن[61]
نرم افزار تشخيص گفتار تلفظهاي تشخيص داده شده را بر اساس لغات و عباراتي كه بصورت گرامري براي آن تعريف شده است تطبيق مي دهد. به عنوان مثال در يك نرم افزار صوتي مسافرتي، كاربر ممكن است كلمة ”درجه 2“ را براي رزرو كردن يك صندلي كه از نظر اقتصادي با صرفه تر است بكار ببرد، اما اگر كلمة ”درجه 2“ در نرم افزار مربوطه معادلي براي ”درجة اقتصادي“ نباشد، نرم افزار نمي تواند آن را بپذيرد.
تكنولوژي مدل سازي زبانها براي افزايش درصد درستي بكار برده مي شود. بطوريكه صداهاي تشخيص داده شده بوسيلة ليستي از قانونها، صداهاي بعد از خودشان را پيش بيني مي كنند. در اين سيستم ليستي بر اساس لغات يا عبارات تطبيق داده شده با جملات گفته شده به همراه ضريب اطمينان[62] بازگردانده شود. يكي از روشهاي رايج پياده سازي، استفاده از مدل مخفي ماركوف HMM مي باشد. مدل مخفي ماركوف، بر اساس مدل رياضي پردازشش سيگنال ديجيتال مي باشد و يك سيستم پيچيده بر اساس مجموعه حالتهاي متناهي[63] را توصيف مي كند. اين حالتها شرايط رفتن از يك حالت به حالتت بعدي را بيان مي كنند. از مدل HMM براي پيش بيني زنجيره هاي پنهان استفاده مي شود. به عنوان مثال مي توان از اطلاعات صوتي كه بوسيلةة ميكروفون دريافت شده و به سيستم ارسال مي شو درا به صورت يك زنجير تلقي كرد.
1-8- صدا در کامپیوترهای شخصی:
مدت زیادی از ورودی صدا به دنیای کامپیوتر می گذرد و در این مدت تکنولوژی های مربوط به پردازش صوت پیشرفت های چشمگیری داشته اند. از زمان ورود صدای واقعی به دنیای کامپیوتر تکنولوژی های پردازش صوت تغییرات عمده ای را پشت سر گذاشته اند، این تغییرات شامل قوی تر شدن پردازنده های صوتی، بالا رفتن کیفیت ضبط و نمونه برداری صدا و … می باشد.
صدا در کامپیوتر در قالبهای مختلفی ایجاد و نگهداری می شود. به عنوان مثال در فرمت Mid اطلاعات صوتی بصورت نت ذخیره می شوند، یعنی اطلاعات مربوط به هر ساز، به همراه ساز، نت ها و سایر اطلاعات، جداگانه ذخیره می شوند ولی در فرمت Wav اطلاعات صوتی بصورت طول موج های صدا ذخیره می شود و صداها قابل تفکیک نیستند. تعدادی از مهمترین فرمتهای صوتی به این شرح است:
RA,Wma,Mp3,Wav,Mid ,…
اصول کارکرد دیجیتالی کردن صدا:
زمانی که کاربری در یک میکروفن صحبت می کند امواج صوتی میکروفن به امواج الکتریکی تبدیل می شوند. اما هنوز این امواج برای کامپیوترها قابل فهم نیستند. برای این کار سیگنالهای الکتریکی ساخته شده باید به روشی تبدیل به داده های دیجیتالی شوند. اینکار شامل سه مرحله است:
کوانتیزه کرن یا تقریب زدن[64] : برای آنکه هر سیگنال آنالوگی را بتوان به سیگنال دیجیتال تبدیل کرد قبل از هرکاری باید تعداد سطوح ممکن را مشخص کرد. همانطور که می دانیم در یک سیگنال دیجیتال سطوح ممکن 2 سطح است (صفر یا یک مثلا معادل با برق صفر ولت و 20 ولت). اما در سیگنال آنالوگگ یک سیگنال می تواند بین دو سطح مثلا صفر تا 20 ولت هر مقدار ممکنی داشته باشد، مثلا 15/7 ولت. برای اینکه بتوان چنین سیگنالی را به سیگنال دیجیتال تبدیل کرد در گام اول باید فرض کرد سیگنال موردنظر بین دو مقدار حداقل و حداکثر خود چه تعداد سطح دارد. به عنوان مثال برای کاربردهای تلفنی فرض می شود که یک سیگنال آنالوگ می تواند معادل یکی از 256 سطح بینابینی باشد و در غیر اینصورت سطح سیگنال در یک لحظه خاص به نزدیکترین مقدار سطح ولتاژ گرد می شود.
نمونه برداری[65]:
در مرحله بعد تعیین می شود که سیگنال آنالوگ باید در چه فاصله زمانی نمونه برداری شود. هر چه تعداد نقاط نمونه برداری بیشتر باشد دقت عملیات تبدیل و کیفیت سیگنال دیجیتال بدست آمده بالاتر خواهد بود. به مثال در سیستم های آنالوگ در هر ثانیه 4000 بار از سیگنال آنالوگ نمونه برداری می شود (تا بعد تعیین شود که در هر یک از این لحظه ها سطح سیگنال معادل کدام یک از آن 256 سطح ممکن است). در هر ثانیه چهار هزار بار نمونه برداری یعنی سرعت نمونه برداری معادل 4KHz است. این عدد در استانداردهای صوتی امروز بسیار پائین است. بد نیست بدانید که سرعت نمونه برداری برای یک سیگنال صوتی مربوط به موسیقی در حد کیفیت FM معادل KHz 22 و برای سیستم های صوتی با کیفیت CD معادل با KHz 44 است.
کدگذاری[66] :
در آخرین مرحله باید اندازه یا سطح سیگنال را در هریک از لحظات نمونه برداری کرده و آنرا به زبان دیجیتال تبدیل کنیم.
به منظور فهم بیشتر مراحل دیجیتالی کردن صدا، به مثال زیر توجه کنیم:
با توجه به اینکه فرکانس موج مکالمه انسان به طور کلی از صفر تا چهار کیلوهرتز در نظر گرفته می شود، مراحل به این گونه انجام می شوند:
- کوانتیزه کردن: تنها 8 سطح اندازه گیری در نظر می گیریم و مقدار آستانه را مقدار میانی هر سطح ولتاژ داریم.
- نمونه برداری: عمل نمونه برداری بوسیله ضرب موج اصلی در یک تابع مخصوص انجام می شود:
شکل 1-15
شکل موج X(t) :
X(t)=sin(t)
شکل موج نمونه برداری Y(t):
فاصله نمونه برداری اینطور تعیین می شود:
=4KHz= F ماکسیمم فرکانس موج ورودی (موج مکالمه)
2*F=8KHz
میکرو ثانیه =T=125 دوره تناوب
حاصلضرب دو تابع:
- کدگذاری: در این مرحله با توجه به اینکه 8 سطح ولتاژ فرض کرده ایم عمل کدگذاری را انجام می دهیم.
شکل 1-16
اگر مقدار آستانه در نظر گرفته نشود برای بعضی از نمونه ها نمی توان کدی بدست آورد چون روی سطح مشخصی قرار ندارند. بنابراین مقدار آستانه را بین دو سطح در نظر گرفته، اگر مقدار نمونه روی سطح یا بزرگتر بود به مقدار بالایی و اگر کوچکتر بود به مقدار پائینی گرد می کنیم و در نهایت برای هر نمونه کد مربوط به آنرا ذخیره می کنیم به این صورت است که صدا در کامپیوتر بصورت صفر و یک ذخیره می شود.
فصل دوم – پردازش صوت
2-1- دستگاه شنوایی انسان
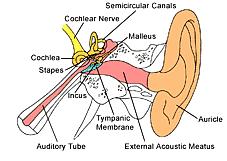
شکل2-1
پردازش صوت محدودههای گوناگونی را در بر میگیرد که همه به منظور ارائهی صدا به شنوندگان انسانی ابداع شدهاند. سه محدودهی تکثیر موسیقی با کیفیتی به خوبی اصل همانند آنچه در سیدیهای صوتی وجود دارد، ارتباط صوتی از راه دور که نام دیگر شبکهی تلفنی است و ترکیب صحبت که در آن کامپیوترها الگوهای صوتی انسان را تولید کرده یا تشخیص میدهند از دیگر قلمروهای دانش پردازش صوت مهمترند. با وجود این که اهداف و مسائل این کاربردها متفاوتند همگی در یک نقطهی مشترک به هم میرسند و آن گوش انسان است.
گوش انسان یک عضو به گونهای فزاینده پیچیده است. قضیه وقتی پیچیدهتر میشود که اطلاعات ارسالی از دو گوش در یک شبکهی پیچیدهی گیج کننده که همانا مغز انسان باشد با هم ترکیب میشوند. به یاد داشته باشیم که بیان فوق یک گذر کلی بر قضیه است و تعداد زیادی از پدیدهها و آثار دقیق مرتبط با گوش انسان هنوز به درستی درک نشدهاند.
شکل 2-1 قسمت اعظم ساختارها و پردازشهایی را که گوش انسان را در بر دارند به تصویر میکشد. گوش خارجی از دو بخش تشکیل شده است: نرمی پوست قابل مشاهده و غضروف متصل به کنار سر و کانال گوش که لولهایست به قطر تقریبی ۰.۵ سانتیمتر و تا حدود ۳ سانتیمتر در داخل سر فرو میرود. این ساختارها صداهای محیط را به بخشهای حساس گوش میانی و گوش داخلی که در درون استخوانهای جمجمه محافظت میشود راهبری میکنند. در انتهای کانال گوش یک ورقهی نازک از نسوج که پردهی صماخ یا طبل گوش نامیده میشود کشیده شده است. امواج صدا با برخورد به پردهی صماخ باعث لرزش آن میشوند. گوش میانی مجموعهای از استخوانهای کوچک است که لرزش مزبور را به حلزون گوش(گوش داخلی) انتقال میدهند و در آنجا این لرزشها تبدیل به ضربههای عصبی میگردند. حلزون گوش یک لولهی پر از مایع است که به زحمت قطر آن به ۲ میلیمتر و طول آن به ۳ سانتیمتر میرسد. اگر چه حلزون گوش در شکل شماره ۱ به صورت یک لولهی مستقیم نشان داده شده اما در واقع به دور خودش همانند صدف حلزون پیچ خورده است و وجه تسمیهی آن که ریشه در کلمهای یونانی به معنای حلزون دارد نیز این واقعیت است.
وقتی یک موج صوتی سعی دارد از هوا وارد مایع شود تنها کسر کوچکی از آن از بین دو محیط عبور میکند و باقیماندهی انرژی آن بازتابیده میشود. دلیل این امر مقاومت مکانیکی پایین هوا (ناشی از پایین بودن میزان فشار صوتی و سرعت بالای ذرات هوا که به نوبهی خود از چگالی پایین و تراکمپذیری بالای آنها نشأت میگیرد) در برابر مقاومت مکانیکی بالای مایع است. به عبارت سادهتر دلیل این امر مشابه دلیل این موضوع است که برای ایجاد موج با دست در درون آب به تلاش بیشتری به نسبت انجام این کار در هوا نیازمندیم. تفاوت موجود باعث بازتابش قسمت اعظم صوت در مرز هوا/مایع میگردد.
گوش میانی یک شبکهی تطبیق مقاومت است که کسر انرژی صوتی وارد شده به مایع گوش داخلی را زیاد میکند. برای نمونه ماهی پردهی صماخ یا گوش میانی ندارد چرا که نیازی به شنیدن در هوا ندارد. تغییر شدت، بیشتر ناشی از تفاوت مساحت پردهی صماخ (که صدا را از هوا دریافت میکند) و دریچه بیضوی (که مطابق شکل ۱صدا را به داخل مایع انتقال میدهد) میباشد. مساحت پردهی صماخ حدوداً ۶۰ میلیمتر مربع است حال آن که دریچهی بیضوی حدوداً ۴ میلیمتر مربع مساحت دارد. از آنجا که فشار برابر است با نسبت نیرو به مساحت، این تفاوت مساحت فشار موج صدا را حدوداً ۱۵ برابر افزایش میدهد.
در داخل حلزون گوش پردهی اصلی قرار دارد که ساختاری را برای ۱۲۰۰۰ سلول حسی که شکلدهندهی عصب حلزونی است ایجاد میکند. پردهی اصلی در نزدیکی دریچهی بیضوی بسیار سفت است و در انتهای دیگر انعطافپذیرتر است که این امر به این عضو کمک میکند تا به عنوان تحلیلگر طیف فرکانسی عمل کند. وقتی پردهی اصلی در معرض یک سیگنال با فرکانس بالا قرار میگیرد در قسمت سفتتر طنین میاندازد که سبب تحریک سلولهای عصبی نزدیک به دریچهی بیضوی میگردد. به همین ترتیب فرکانسهای پایین موجب تحریک انتهای دورتر پردهی اصلی میشوند. این امر موجب پاسخگویی رشتههای خاص عصب حلزونی در برابر فرکانسهای خاص میگردد. این سازوکار اصل مکان نامیده میشود و در سراسر مسیر به سمت مغز حفظ میشود.
طرح کدگذاری اطلاعات دیگری نیز در شنوایی انسان به کار میرود که اصل رگبار نامیده میشود. سلولهای عصبی اطلاعات را با تولید پالسهای الکتریکی کوچکی که پتانسیل کنش نامیده میشوند انتقال میدهد. یک سلول عصبی واقع بر پردهی پایینی میتواند اطلاعات صوتی را با تولید یک پتانسیل کنش در پاسخ هر سیکل لرزش کدگذاری کند. برای نمونه یک موج صدای ۲۰۰ هرتزی میتواند توسط یک نورون ایجاد کنندهی ۲۰۰ پتانسیل کنش در ثانیه نشان داده شود. در هر صورت این روش تنها در فرکانسهای زیر حدوداً ۵۰۰ هرتز – بالاترین سرعت ممکن تولید پتانسیل کنش در نورونها – به کار میآید. گوش انسان برای غلبه بر این مشکل به نورونها اجازه میدهد که برای انجام این کار دستهجمعی عمل کنند. برای نمونه یک صدای ۳۰۰۰ هرتزی میتواند توسط ده سلول عصبی که هر کدام ۳۰۰ ضربه در ثانیه علامت میدهند نشان داده شود. این پدیده بازهی کارایی اصل رگبار را تا ۴ کیلوهرتز گسترش میدهد که بالاتر از بازهی عملیاتی اصل مکان میباشد.
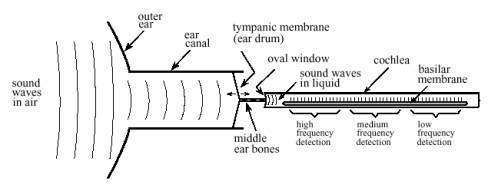
شکل2-2- توضیحات مربوط به شکل: نمودار کارکردی گوش انسان. گوش خارجی امواج صوتی را از محیط میگیرد و آنها را به سوی پردهی صماخ (طبل گوش) که ورقهی نازکی از بافت است و هماهنگ با شکل موج هوا میلرزد راهبری میکند. استخوانهای گوش میانی (استخوانهای چکشی، سندانی و رکابی) این لرزشها را به دریچهی بیضوی که پردهای منعطف واقع در حلزون گوش پر از مایع است انتقال میدهند. در داخل حلزون گوش پردهی اصلی قرار دارد که ایجاد کنندهی ساختاری برای ۱۲۰۰۰ سلول عصبی شکلدهندهی عصب حلزون گوش است. بسته به سفتی متغیر پردهی پایینی، هر سلول فقط به بازهی کوچکی از فرکانسهای صدا پاسخ میدهد که این پدیده گوش را تبدیل به یک تحلیلگر طیف فرکانسی مینماید.
شکل شماره 2-۲ رابطهی بین شدت صدا و بلندی مشاهده شده را نشان میدهد. غالباً شدت صدا را با یک اندازهی لگاریتمی که دسیبل اس.پی.ال (سطح توان صدا) نامیده میشود نشان میدهند. در این معیار۰ دسیبل اس.پی.ال موج صدایی با قدرت ده به توان منفی شانزده وات بر سانتیمتر مربع است که حدوداً ضعیفترین صدای قابل تشخیص توسط گوش انسان است. صحبت معمولی حدوداً ۶۰ دسیبل اس.پی.ال است و صدایی با شدت ۱۴۰ دسیبل اس.پی.ای برای گوش دردناک و زیانآور است
.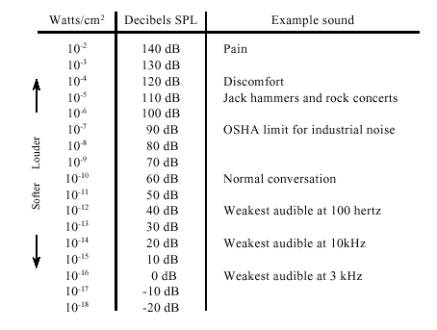
شکل شماره 2-3 – واحدهای شدت صدا. شدت صدا به صورت توان بر واحد مساحت تعریف میشود (مثلاُ وات بر سانتیمتر مربع) یا به صورت معمولتر با استفاده از یک اندازهی لگاریتمی که دسیبل اس.پی.ال خوانده میشود. همچنان که این جدول نشان میدهد قوهی شنوایی انسان بیشتر به صداهای بین ۱کیلوهرتز تا ۴ کیلوهرتز حساس است.
- پیش بینی سری زمانی به کمک شبکه عصبی در متلب
- تشخیص فونم ها(لب خوانی) با SVM در متلب
- راهکار ارائه پیشنهاد تطبیقی بر اساس یادگیری-Q در حراجهای ترکیبی
- ماشین های القایی متقارن در متلب
- سفارش پروژه های دینامیک سیالات محاسباتی با متلب
اختلاف بلندترین و ضعیفترین صداهایی که انسان میتواند بشنود ۱۲۰ دسیبل است که از لحاظ دامنه معادل بازهای حدود یک میلیون است. شنونده تغییر بلندی صدا را وقتی صدا حدود ۱ دسیبل (۱۲% در دامنه) تغییر کند تشخیص میدهد به عبارت دیگر تنها ۱۲۰ سطح بلندی صدا از ملایمترین نجوا تا بلندترین تندر قابل تشخیص است. حساسیت گوش آنقدر جالب توجه است که هنگام شنیدن به ضعیفترین صداها پردهی صماخ به اندازهای کمتر از قطر یک ملکول به لرزش درمیآید!
احساس بلندی صدا با توان صدا رابطهی توانی با نمای ۱/۳ دارد. به عنوان نمونه اگر شما توان صدا را ده برابر کنید شنوندگان آن صدا دو برابر شدن بلندی صدا را احساس و گزارش میکنند.
این مسأله یک مشکل بزرگ برای حذف صداهای محیطی ناخواسته به وجود میآورد. برای نمونه فرض کنید که شما ۹۹% دیوار را با عایق صوتی پوشاندهاید و تنها ۱% که مربوط به درها، گوشهها، منافذ و… هستند باقی ماندهاند. با وجود آن که توان صدا تا اندازهی ۱% مقدار اولیهی آن کاسته شده بلندی صدا تنها به اندازهی ۲۰% کاهش پیدا کردهاست.
بازهی شنیداری انسان بین ۲۰ هرتز تا ۲۰ کیلوهرتز در نظر گرفته میشود، حال آن که بیشتر صداهای قابل حس در بازهی ۱ کیلوهرتز تا ۴ کیلوهرتز قرار دارند. برای نمونه شنوندگان میتوانند صدایی به میزان صفر دسیبل را در فرکانس ۳ کیلوهرتز بشنوند حال آن که برای شنیدن یک صدای ۱۰۰ هرتزی حداقل مقدار آن باید ۴۰ دسیبل باشد. شنوندگان میتوانند بگویند که دو صدا متفاوتند اگر فرکانس آنها بیش از حدود %۰.۳ در ۳ کیلوهرتز متفاوت باشد. به عنوان نمونه کلیدهای کنار هم در پیانو به اندازهی حدود ۶% تفاوت فرکانس دارند.
مهمترین مزیت داشتن دو گوش تشخیص جهت صداست. شنوندگان انسانی میتوانند تفاوت بین دو منبع صدا را که فاصلهای به کمی ۳ درجه دارند (حدوداً برابر با عرض یک انسان در فاصلهی ده متری) تشخیص دهند. این اطلاعات جهتی به دو روش جداگانه به دست میآیند. اولاً فرکانسهای حدوداً بالای ۱ کیلوهرتز به شدت زیر سایهی سر قرار میگیرند. به بیان دیگر گوشی که به منبع نزدیکتر است سیگنال قوی تری را به نسبت گوشی که در جهت مخالف دارد دریافت میکند. روش دیگر تشخیص جهت آن است که گوش دورتر به خاطر فاصلهی بیشترش از منبع صدا را کمی دیرتر از گوش نزدیکتر دریافت میکند. به واسطهی اندازهی معمول سر (حدوداً ۲۲ سانتیمتر) و سرعت صوت (حدود ۳۴۰ متر در ثانیه) تفاوتگذاری زاویهای سه درجه دقت زمانی حدود ۳۰ میکروثانیه نیاز دارد. چون این فاصلهی زمانی نیازمند اصل رگبار است این روش جهتیابی برای صداهای دارای فرکانس کمتر از حدود ۱ کیلوهرتز به کار میرود.
در حالی که قوهی شنوایی انسان میتواند جهت صدا را تشخیص دهد در نشخیص فاصلهی منبع صدا مشکل دارد. این امر بدان علت است که چیزهای کمی در موج صدا وجود دارد که اطلاعات این گونه را در اختیار بگذارد. شنوایی انسان به صورت ضعیفی در مییابد که منابع صداهای با فرکانس بالا نزدیکند و صداهای با فرکانس پایین از فاصلهی دورتری پخش میشوند. این به آن دلیل است که صداها در فاصلههای دور از میزان فرکانسشان کاسته میشود. پژواک روش ضعیف دیگری برای تشخیص فاصله است و با استفاده از آن مثلاً میتوان ابعاد یک اتاق را حدس زد. برای نمونه صداهای موجود در یک تالار بزرگ پژواکهایی با وقفهی ۱۰۰ میلی ثانیه دارند، حال آن که برای یک دفتر کار کوچک این مقدار ۱۰ میلی ثانیه است. بعضی از موجودات با استفاده از دستگاه طبیعی تشخیص فاصلهی صوتی مسألهی فاصلهیابی را حل کردهاند. مثلاً خفاشها و دلفینها صداهایی مثل تیک و جیغ تولید میکنند که از سوی اشیاء نزدیک بازتابیده میشوند. با اندازهگیری میزان وقفهی بازتاب این صداها این جانوران میتوانند با دقت ۱سانتیمتر اشیاء را مکانیابی کنند. تجربیات نشان دادهاند که بعضی انسانها به خصوص نابینایان تا حد کمی از روش مکانیابی با استفاده از پژواک استفاده میکنند.
2-2- ویژگیهای امواج صوتی

شکل2-4
غالباً برای درک یک صوت پیوسته مثل نت یک ابزار موسیقیایی سه بخش مجزا را باید تشخیص داد: بلندی صدا، زیری یا بمی صدا (پیچ) و طنین صدا. بلندی همانگونه که قبلاً توضیح داده شد معیاری برای شدت موج صوتی است. پیچ، فرکانس جزء اصلی صدا – فرکانسی تکرار موج صوتی توسط خودش – میباشد.
طنین صدا از دو جزء قبلی پیچیدهتر است و با تعیین محتوای همساز صدا تعیین میگردد. شکل شماره ۳ دو موج را که هر دو از جمع یک موج سینوسی یک کیلوهرتزی با دامنهی یک و یک موج سینوسی سه کیلوهرتزی با دامنهی یک دوم به وجود آمدهاند نشان میدهد. تفاوت آنها در آن است که در شکل b جزء با فرکانس بالاتر ابتدا معکوس شده و سپس با موج دوم جمع شده است. علیرغم موجهای در دامنهی زمان بسیار متفاوت این دو صوت یکسان به نظر میرسند. این به خاطر آن است که شنوایی انسان بر اساس دامنهی فرکانسهاست و نسبت به فاز آنها بسیار غیر حساس است. شکل موج صوتی در دامنهی زمان فقط به صورت غیر مستقیم با شنوایی رابطه دارد و معمولاُ در سیستمهای صوتی در نظر گرفته نمیشود.
عدم حساسیت گوش به فاز صدا با توجه به روش پخش شدن آن در محیط قابل درک است. فرض کنید که شما در یک اتاق به صحبتهای فردی گوش میدهید. بیشتر صداهایی که گوش شما دریافت میکند حاصل بازتاب صدای اصلی از دیوارها، سقف و کف اتاق است. از آنجا که انتشار صدا بستگی به فرکانس آن دارد و میرایی، بازتاب و مقاومت در برابر صدا بر روی آن تأثیرگذار است فرکانسهای متفاوتی از مسیرهای متفاوت به گوش میرسد. این به این معنی است که وقتی شما جای خود را در اتاق عوض میکنید فاز هر یک از فرکانسها تغییر میکند. چون گوش این تغییر فازها را نادیده میانگارد با وجود تغییر مکان شما تغییری در صدای شخص صحبت کننده احساس نمیکنید. از دیدگاه فیزیکی فاز یک سیگنال صدا در هنگام پخش در یک محیط پیچیده به صورت تصادفی تغییر میکند. از طرف دیگر گوش به فاز صدا غیر حساس است زیرا این جزء دارای اطلاعات قابل استفادهی بسیار کمی میباشد.
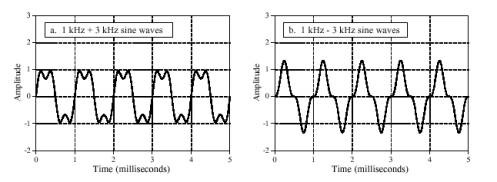
شکل شماره 2-5 – تشخیص فاز توسط گوش انسان. گوش انسان نسبت به فاز نسبی سینوسیهای مرکب بسیار غیر حساس است. برای نمونه این دو موج یکسان به نظر خواهند رسید، زیر دامنهی اجزاء آنها یکسان است اگر چه فاز نسبی آنها متفاوت است.
در حالت کلی نمیتوان گفت که گوش نسبت به فاز کاملاً ناشنواست. چرا که تغییر فاز میتواند باعث تغییر آرایش زمانی یک سیگنال صوتی شود. اما چنین امری یک پدیدهی نادر است که در محیطهای شنیداری طبیعی اتفاق نمیافتد.
فرض کنید از یک نوازندهی ویولون خواستهایم نتی را بنوازد. وقتی که موج صوتی ایجاد شده بر روی اسیلوسکوپ نشان داده شود یک موج دندانهارهای مانند شکل شماره ۴ (a) مشاهده میشود. شکل شماره ۴ (b) نشان میدهد که این صوت چگونه توسط گوش دریافت میشود. گوش یک فرکانس اساسی (در مثال شکل ۲۲۰ هرتز) را و همسازهایی را در ۴۴۰، ۶۶۰، ۸۸۰ و… هرتز دریافت میکند. اگر این نت بر روی ابزار دیگری نواخته شود گوش هنوز هم همان ۲۲۰ هرتز (همان فرکانس اساسی) را دریافت میکند. و از این لحاظ دو صوت مشابهند که گفته میشود این دو صوت پیچ یکسانی دارند ولی چون دامنهی همسازها متفاوت است دو صوت یکسان نیستند و گفته میشود که طنین دو صوت متفاوت است.
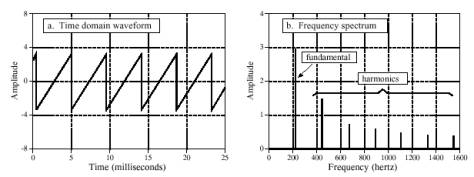
شکل شماره 2-6 – موج صوتی ویولن. ویولن موج دندانهارهای ایجاد میکند(شکل a)، صدای دریافت شده شامل فرکانس اساسی و همسازهای آن است (شکل b)
اغلب گفته میشود که طنین صدا از روی شکل موج صوتی تعیین میگردد. این مسأله درست است ولی کمی گمراه کننده است. احساس طنین صدا از روی میزان هارمونیکهای تشخیص داده شده توسط گوش تعیین میگردد. در حالی که هارمونیکها از روی شکل موج صوتی تعیین میگردد عدم حساسیت گوش به فاز رابطه را بسیار یک طرفه میکند. به همین دلیل هر موج صوتی فقط یک طنین دارد حال آن که یک زنگ خاص متعلق به تعداد بینهایتی از موجهای صوتی است.
- الگوریتم جستجوی کلاغ ها به همراه کد متلب
- مقالات شبیه سازی شده با متلب کد جیg -بخش دوم
- سفارش شبیه سازی مباحث درس دینامیک سیستم های قدرت
- توابع سینوسی با متلب و با دستور stem
- قسمت سوم بانک مقالات شبیه سازی شده برق قدرت
گوش بیشتر برای شنیدن هارمونیکهای اساسی تنظیم شده است. اگر یک شنونده به صدایی که حاصل ترکیب دو موج صوتی سینوسی ۱ کیلوهرتز و ۳ کیلوهرتز است گوش دهد آن را مطلوب و طبیعی توصیف خواهد کرد حال آن که اگر از موجهای ۱ کیلوهرتزی و ۳.۱ کیلوهرتزی استفاده شود برای شنونده شکایت برانگیز خواهد بود. این مسأله اساسی برای اندازهها و اختلافهای استاندارد ابزارهای موسیقیایی فراهم میآورد.
2-3- روشهای دیجیتالی ذخیرهی صدا
در طراحی یک سیستم صوتی دیجیتال دو پرسش وجود دارند که باید پاسخ داده شوند: ۱- چقدر لازم است صوت خوب به نظر برسد؟ ۲- چه نرخ دادهای قابل تحمل است؟ جواب به این پرسشها غالباً به یکی از این سه انتخاب منجر میشود: اول موسیقی با وفاداری بالا که در آن کیفیت صدا مهمترین چیز است و تقریباً هر نرخ دادهای قابل قبول است. دوم ارتباط تلفنی که نیازمند طبیعی به نظر رسیدن صحبت و یک نرخ دادهی پایین برای کاهش هزینهی سیستم است. سوم صحبت فشرده شده که در آن کاهش نرخ داده بسیار مهم است و مقداری غیر طبیعی به نظر رسیدن کیفیت صدا قابل تحمل است. این مورد در بر دارندهی ارتباطات نظامی، تلفنهای سلولی و صحبت ذخیره شده به صورت دیجیتال برای پست الکترونیکی صوتی یا کاربردهای چند رسانهای است.
شکل شماره 2-5 بده بستانهای موجود در انتخاب هر یک از این سه روش را نشان میدهد.
در حالی که موسیقی نیازمند پهنای باند ۲۰ کیلوهرتز است صحبتی که طبیعی به نظر برسد فقط به پهنای باندی در حدود ۳.۲ کیلوهرتز نیازمند است. در این حال هر چند پهنای باند به اندازهی ۱۶% مقدار اولیه محدود میشود ولی فقط ۲۰% اطلاعات اولیه از دست میرود.
سیستمهای ارتباط راهدور اغلب از نرخ نمونهبرداری در حدود ۸ کیلوهرتز استفاده میکنند که اجازهی انتقال صحبت را با کیفیتی در حد طبیعی میدهد ولی اگر از آن برای انتقال موسیقی استفاده شود تا میزان بالایی از کیفیت آن از دست میرود. شما احتمالاً با تفاوت این دو میزان آشنایی دارید: ایستگاههای رادیویی اف.ام با پهنای باندی در حدود ۲۰ کیلوهرتز اقدام به پخش میکنند حال آن که ایستگاههای ای.ام محدود به ۳.۲ کیلوهرتز هستند. صحبت و صداهای معمول روی ایستگاههای نوع دوم طبیعی به نظر میرسد حال آن که موسیقی این گونه نیست.
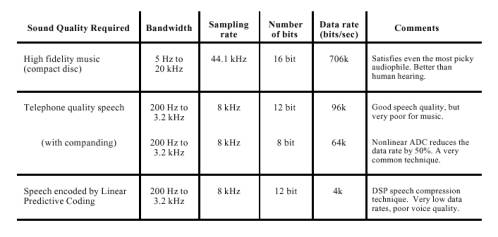
شکل شماره 2-7- نرخ دادهی صوتی در برابر کیفیت صدا. کیفیت صدای یک سیگنال صوتی دیجیتال به نرخ دادهی آن که برابر با حاصلضرب نرخ نمونهبرداری آن در تعداد بیتهای آن در هر نمونه بستگی دارد که به سه بخش تقسیم میشود: موسیقی باوفاداری بالا (۷۰۶کیلوبیت بر ثانیه)، صحبت با کیفیت تلفن ۶۴کیلوبیت بر ثانیه وصحبت فشرده شده (۴ کیلوبیت بر ثانیه)
سیستمهایی که فقط با صدا (و نه موسیقی) سر و کار دارند میتوانند مقدار دقت را از ۱۶ بیت به ۱۲ بیت بدون از دست رفتن دقتی قابل توجه کاهش دهند. این میزان میتواند با انتخاب اندازهی نامتساوی برای گام مقدارگزینی میتواند به ۸ بیت در هر نمونه نیز کاهش یابد. یک نرخ نمونهبرداری ۸ کیلوهرتز با دقت ای.دی.سی ۸ بیت در هر نمونه به نرخ دادهی ۶۴کیلوبیت بر ثانیه میانجامد. این یک حد نهایی برای طبیعی به نظر رسیدن صحبت است. دقت کنید که صحبت نیازمند نرخ دادهای معادل ۱۰% نرخ دادهی موسیقی با وفاداری بالاست.
نرخ دادهی ۶۴ کیلو بیت بر ثانیه نمایانگر کاربرد نهایی نظریهی نمونهبرداری و مقدارگزینی برای سیگنالهای صوتی است. روشهای کاهش نرخ داده به اندازهای بیشتر از این مبتنی بر فشردهسازی جریان داده با حذف تکرارهای ذاتی سیگنال صحبت است. یکی از کاراترین روشهای موجود ال.پی.سی است که انواع و زیرگروههای متعدد دارد. بر اساس کیفیت سیگنال صحبت مورد نیاز این روش میتواند نرخ داده را تا اندازهای بین ۲ تا ۶ کیلو بیت بر ثانیه کاهش دهد.
2-4- برنامهنویسی و پیادهسازی پردازش صوت
2-4-1- ساختار مورد نیاز برای نگهداری ویژگیهای صدا
همانطور که اشاره شد برای ذخیره یا بازخوانی یک نمونه صدا به صورت دیجیتال نیازمند آنیم که برخی ویژگیهای خاص صدای دیجیتالی از قبیل نرخ نمونهبرداری، تعداد بیت هر نمونه و یککاناله یا دوکاناله بودن صدا را مشخص کنیم.
برای این منظور در محیط برنامهنویسی مورد نظر ما (ویندوز) از ساختاری به نام WAVEFORMATEX استفاده میگردد که به صورت زیر تعریف میگردد:
typedef struct {
WORD wFormatTag;
WORD nChannels;
DWORD nSamplesPerSec;
DWORD nAvgBytesPerSec;
WORD nBlockAlign;
WORD wBitsPerSample;
WORD cbSize;
} WAVEFORMATEXX;
در این ساختار فیلد wFormatTag فرمت فایل را که نشان دهندهی نوع الگوریتمهای به کار گرفته شده برای فشردهسازی صدا و… است را مشخص میکند. برای استفادهی مورد نظر ما فرمت خاصی که با ثابت WAVE_FORMAT_PCM مشخص میگردد و فرمت پی.سی.ام نامیده میشود مناسب است. علاوه بر آن فیلد cbSize برای فرمتهای غیر پی.سی.ام استفاده میشود و ما همواره مقدار آن را صفر در نظر خواهیم گرفت.
از آنجا که پردازش این ساختار در برنامهنویسی صدا برای پروژهی مورد نظر بارها صورت میگیرد و از آنجا که یک شیوهی طراحی شیءگرا (شیوهی ام.اف.سی) برای پیادهسازی پروژه در نظر گرفته شده بود و از آنجا که پردازش این ساختار نیاز به برخی محاسبات تکراری (تعیین nBlockAlign و nAvgBytesPerSec) دارد و به چند دلیل دیگر تصمیم گرفته شد که این ساختار و پردازش آن به صورت یک کلاس با نام HSound پیاده سازی گردد که ضمن خودکار نمودن پردازش این ساختار کلاسهایی که به اعمال پخش و ضبط را بر عهده دارند از این کلاس ارثبری نموده برنامه نویسی را آسانتر و کد به دست آمده را خواناتر نمایند.
تعریف این کلاس به صورت زیر است:
class HSound
{
public:
//constructor and destructor:
HSound();
virtual ~HSound();
//setting wave data:
void SetBitsPerSample(int bps);
void SetSamplesPerSecond(int sps);
void SetNumberOfChannels(int nchan);
//retrieving wave data:
WAVEFORMATEX* GetFormat();
int GetSamplesPerSecond();
int GetBitsPerSample();
int GetNumberOfChannels();
protected:
WAVEFORMATEX m_wfData;
private:
void Update();
};
قبل از هر چیز باید به این نکته اشاره شود که این کلاس برای پردازش فرمت پی.سی.ام در نظر گرفته شده، لذا ضمن تعریف مقادیر پیشفرض لازم برای این فرمت و استفاده از روشهای خاص این فرمت برای محاسبهی فیلدهای مختلف امکان تغییر فرمت و استفاده از سایر فرمتها را به برنامهنویس نمیدهد و به منظور پردازش سایر فرمتها ساختار کلاس میبایست تغییر کند.
فیلد wBitsPerSample تعداد بیتِ هر نمونه را مشخص میکند که برای فرمت پی.سی.ام فقط میتواند یکی از دو مقدار ۸ و ۱۶ را داشته باشد و برای سایر فرمتها مقادیر ممکن بستگی به مشخصات منتشر شده توسط شرکتهای به وجود آورنده و پشتیبانیکنندهی آنها دارد.
متدی که در پی میآیند آن را مقدارگذاری میکند (در مورد متد Update و علت فراخوانی آن در ادامه توضیح داده خواهد شد :
void HSound::SetBitsPerSample(int bps)
{
m_wfData.wBitsPerSample = bps;
Update();
}
و متد زیر مقدار انتخاب شده را برمیگرداند:
int HSound::GetBitsPerSample()
{
return m_wfData.wBitsPerSample;
}
فیلد nSamplesPerSec تعداد نمونهها در هر ثانیه (نرخ نمونهبرداری) را مشخص میکند. برای فرمت پی.سی.ام مقادیر معمول ۸کیلوهرتز (۸۰۰۰)، ۱۱.۰۲۵کیلوهرتز (۱۱۰۲۵)، ۲۲.۰۵کیلوهرتز (۲۲۰۵۰) و ۴۴.۱کیلوهرتز (۴۴۱۰۰) میباشد و برای سایر فرمتها مقادیر ممکن بستگی به مشخصات منتشر شده توسط شرکتهای به وجود آورنده و پشتیبانیکنندهی آنها دارد.
متد مقدارگذاری این فیلد:
void HSound::SetSamplesPerSecond(int sps)
{
m_wfData.nSamplesPerSec = sps;
Update();
}
و متد دریافت مقدار آن:
int HSound::GetSamplesPerSecond()
{
return m_wfData.nSamplesPerSec;
}
فیلد nChannels تعداد کانالهای موج صوتی را مشخص میکنند. صداهای تک کانال (مقدار فیلد برابر با ۱) مونو و صداهای دوکاناله (مقدار فیلد برابر با ۲) استریو خواهند بود.
متد مقدارگذاری این فیلد:
void HSound::SetNumberOfChannels(int nchan)
{
m_wfData.nChannels = nchan;
Update();
}
و متد دریافت مقدار آن:
int HSound::GetNumberOfChannels()
{
return m_wfData.nChannels;
}
هر چند تعداد کانالهای صدا در این کلاس قابل تغییراست اما در کلاسهای مشتق شده همواره الگوریتمها برای موج صوتی تککاناله نوشته شدهاند و استفاده از آنها برای پردازش موج صوتی دو کاناله نیازمند دستکاری کد این کلاسهاست که به لحاظ استفادهای که ما از این کلاسها نمودهایم یک کار اضافی و غیرضروری به نظر میرسد.
فیلد nBlockAlign کمینهی تعداد واحد داده را برای فرمت انتخاب شده تعیید میکند که اگر فرمت انتخاب شده پی.سی.ام باشد برابر با حاصل ضرب تعداد کانالها (nChannels) در تعداد بیتِ هر نمونه (nBitsPerSample) تقسیم بر تعداد بیتهای موجود در هر بایت (۸) خواهد بود و برای سایر فرمتها بستگی به مشخصات منتشر شده توسط شرکتهای به وجود آورنده و پشتیبانیکنندهی آنها دارد. فیلد nAvgBytesPerSec نیز تعداد متوسط بایتهای موجود در هر ثانیهی صدا را مشخص میکند و برای فرمت پی.سی.ام برابر با تعداد نمونههای موجود در هر ثانیه (nSamplesPerSec) در کمینهی تعداد واحد داده (nBlockAlign) خواهد بود و برای سایر فرمتها بستگی به مشخصات منتشر شده توسط شرکتهای به وجود آورنده و پشتیبانیکنندهی آنها دارد.
متد Update که در کد مقدارگذاری سایر فیلدها محاسبات توضیح داده شدهی بالا را انجام میدهد:
void HSound::Update()
{
m_wfData.nBlockAlign = m_wfData.nChannels*(m_wfData.wBitsPerSample/8);
m_wfData.nAvgBytesPerSec = m_wfData.nSamplesPerSec*m_wfData.nBlockAlign;
}
در صورتی که نیاز باشد با ساختار اصلی WAVEFORMATEX کار شود متد زیر مقدار عضوی از کلاس را که از این نوع است باز میگرداند:
WAVEFORMATEX* HSound::GetFormat()
{
return &m_wfData;
}
در متد سازندهی این کلاس به طور پیشفرض برای نمونهی صوتی مورد نظر نرخ نمونهبرداری ۴۴.۱کیلوهرتز با ۱۶ بیت در هر نمونه در نظر گرفته شده و فرض بر آن است که نمونهی صوتی یک کاناله است:
HSound::HSound()
{
m_wfData.wFormatTag = WAVE_FORMAT_PCM;
m_wfData.cbSize = 0;
SetBitsPerSample(16);
SetSamplesPerSecond(44100);
SetNumberOfChannels(1);
}
همچنانکه از روی تعریف کلاس قابل فهم است این کلاس در واقع تمامی اعمال را روی عضو دادهی محافظت شدهی m_wfData اِعمال مینماید و با غیر مستقیم نمودن دسترسی به این عضو داده برای برنامهی استفاده کننده ضمن رعایت اصل پنهانسازی اطلاعات به فراخوانی رویهی Update در متدهای تغییر دهندهی اعضای مرتبط با nBlockAlign و nAvgBytesPerSec تغییرات لازم را به آنها اعمال میکند.
2-4-2- انجام پردازش صدا به صورت یک رشتهی مستقل
میتوان با استفاده از توابع کار با صدای ویندوز به گونهای برنامهنویسی نمود که نیازی به ایجاد رشتههای مستقل برای پردازندههای صدا نباشد، اما وجود دلایلی از قبیل عدم انعطافپذیری این روش و تکوظیفهای شدن برنامه در حین انجام عملیات پردازش صدا باعث میشود که روش استفاده از رشتههای مستقل مورد توجه ما قرار گیرد.
از آغاز در نظر داشتیم که رابط برنامه به گونه طراحی شود که کاربر در هنگام کار با برنامه و انجام عملیاتی نظیر ضبط صدا از عملکرد برنامه مطمئن باشد. به این معنی که مثلاً در حین هنگام صدا با استفاده از یک رابط گرافیکی مانند یک نمایشگر اسیلوسکوپی از این که برنامه واقعاً و به درستی در حال ضبط صدای اوست و یا به لحاظ فاصلهی نامتناسب با میکروفن یا عدم اتصال درست آن به کارت صوتی یا خرابی آن بیشتر آنچه ضبط میشود سکوت و یا نویز است مطلع گردد. یک روش مناسب برای ایجاد چنین رابطی استفاده از پیام فرستاده شده برای پردازش صدا توسط یک رشته برای فعال شدن یک تابع رسمکنندهی نمودار اسیلوسکوپی است که نیاز به آن دارد که بدون قطع شدن جریان ضبط پردازش دیگری صورت گیرد. به این منظور و با استفاده از کد اولیهای که در منبع شمارهی ۲ به آن اشاره شده کلاسی به نام HSoundRunner را از کلاس HSound اعضای داده و متدهای مرتبط با پردازش صوت و از کلاس ام.اف.سی CwinThread اعضای داده و متدهای لازم برای یک رشته را ارثبری میکند به صورت زیر تعریف نمودیم:
class HSoundRunner:
public CWinThread,
public HSound
{
public:
DECLARE_DYNCREATE(HSoundRunner)
HSoundRunner();
~HSoundRunner();
void SetBufferSize(int nSamples);
int GetBufferSize();
//this metheods should be overriden:
void AddBuffer();
BOOL Start(WAVEFORMATEX* pwfex=NULL);
BOOL Stop();
//for graphical display:
void SetOwner(CWnd* pWnd);
void ClearOwner(COLORREF crBkColor=0×000000);
public:
//{{AFX_VIRTUAL(HSoundRecorder)
public:
virtual BOOL InitInstance();
//}}AFX_VIRTUAL
protected:
DWORD m_dwThreadID;
int m_iBufferSize; // number of samples per each period
int m_nBuffers; //number of buffers remained to be run
int m_nSamples; //number of samples stored
short* m_pSamples; //samples stored
BOOL m_bRunning; //indicated running or not
//if graphical display is intended set this value
CWnd* m_pOwner;
void DrawBuffer(int nSamples, short* pSamples, COLORREF crBkColor=0×000000, COLORREF crLineColor=0×00FF00);
};
اعضای دادهی این کلاس در روند انجام عملیات توسط کلاسهای مشتق شده از آنها نقش خود را نشان خواهند داد و به عنوان نمونه عضو دادهی m_iBufferSize که نشان دهندهی آن است که بعد از ضبط با پخش چند نمونه تابع پردازندهی پیام در کلاس پنجرهی کنترل کننده باید فراخوانی شود در این هیچکدام از متدهای این کلاس نقش عملی پیدا نمیکند و فقط مقدارگذاری آن از طریق متد SetBufferSize و دریافت مقدار فعلی آن از طریق GetBufferSize صورت میگیرد:
void HSoundRunner::SetBufferSize(int nSamples)
{
m_iBufferSize=nSamples;
}
int HSoundRunner::GetBufferSize()
{
return m_iBufferSize;
}
عضو دادهی m_dwThreadID مقدار شناسهی رشتهی ایجاد شده را که در کلاس سازنده با فراخوانی CreateThead ایجاد میشود در بر میگیرد که در کلاسهای مشتق شده برای کار با فراخوانیهای ای.پی.آی پردازش صدا کاربرد پیدا میکند. مقدار این عضو داده در متد بازنویسی شدهی InitInstance و به صورت زیر تعیین میگردد:
BOOL HSoundRunner::InitInstance()
{
m_dwThreadID = ::GetCurrentThreadId();
return TRUE;
}
اعضای دادهی m_nSamples و m_pSamples به ترتیب تعداد نمونههای ضبط شده یا آماده برای پخش و آرایهی حاوی آنها -که به لحاظ آسانتر شدن کار با کتابخانهای که برای پردازش سیگنال صحبت استفاده شده و همسان با آن از نوع short در نظر گرفته شده را نشان میدهند. این دو عضو داده به صورت پویا پس از انجام عملیات ضبط مقدارگذاری میشوند و برای عملیات پخش باید قبلاً مقدارگذاری شده باشند.
آنچه این کلاس انجام میدهد غیر از ایجاد یک رشته برای انجام پردازش صدا فراهم آوردن روشی برای نمایش اسیلوسکوپی صداست که از طریق متد DrawBuffer انجام میشود.
این متد در توابع پیامهای مربوط به پردازش صوت خود به خود فراخوانی میگردد و در صورتی که مقدار m_pOwner اشارهگر به یک پنجره یا کنترل انتخاب شود (توسط متد SetOwner) آرایهی ورودی که معمولاً یک تکهی تازه ضبط با پخش شده از کل صداست متناسب با طول و عرض پنجرهی مورد نظر بر روی آن کشیده میشود. این کار با ایجاد یک ابزار متن و یک Bitmap متناسب با ابزار متن پنجرهی مورد نظر، کشیدن طرح لازم با استفاده از این دو و در نهایت نمایش تصویر ایجاد شده بر روی پنجرهی مقصد و مطابق با کد زیر انجام میشود:
void HSoundRunner::DrawBuffer(int nSamples, short* pSamples, COLORREF crBkColor, COLORREF crLineColor)
{
if(m_pOwner==NULL)
return;
CRect rc;
m_pOwner->GetClientRect(&rc);
int iWidth=rc.Width();
int iHeight=rc.Height();
CDC* pDC=m_pOwner->GetDC();
CBitmap Bitmap;
Bitmap.CreateCompatibleBitmap(pDC, iWidth, iHeight);
CDC dc;
dc.CreateCompatibleDC(pDC);
dc.SelectObject(&Bitmap);
CBrush Brush(crBkColor);
dc.FillRect(&rc,&Brush);
CPen Pen(PS_SOLID,1,crLineColor);
dc.SelectObject(&Pen);
dc.SetBkColor(crBkColor);
if(GetBitsPerSample()==16)
{
float fx=iWidth/float(nSamples);
float fy=float(iHeight/32767.0);
dc.MoveTo(0, iHeight/2);
int i=0;
for(float f=0; f<iWidth&&i<nSamples; f+=fx, i++)
dc.LineTo(int(f), int(iHeight/2+fy*pSamples[i]));
pDC->BitBlt(0, 0, iWidth, iHeight, &dc, 0, 0, SRCCOPY);
}
}
متد ClearBuffer یک روش قابل دسترسی توسط برنامه برای پاک کردن پنجرهی مورد استفاده به وجود میآورد و شامل یک فراخوانی متد محافظت شدهی DrawBuffer با یک آرایهی به طول صفر است:
void HSoundRunner::ClearOwner(COLORREF crBkColor)
{
DrawBuffer(0,NULL,crBkColor);
}
عضو دادهی m_nBuffers تعداد بافرهای اختصاص داده شده و استفاده نشده را نشان میدهد که در متد AddBuffer این کلاس و بازنویسی شدهی آن برای کلاسهاس مشتق شده مقدار آن به ازای هر بار فراخوانی یک واحد افزوده میشود و در پیامهای پردازش صدا که از طرف سیستم عامل فعال میشوند و نشانگر استفاده شدن بافر مورد نظر است (در کلاسهای مشتق شده) یک واحد کاهش مییابد. در نهایت صفر نبودن این عضو داده نشانگر استفادهی ناکامل از بافرهای اختصاص داده شده (معادل با کامل انجام نشدن فرایند ضبط یا پخش) است که میتواند پردازش مناسب برای آن صورت گیرد:
void HSoundRunner::AddBuffer()
{
m_nBuffers++;
}
عضو دادهی m_bRunning به منظور تشخیص این که برنامه در حال اجرای عملیات پردازش صداست و یا نه به منظور جلوگیری از ایجاد اشکال با فراخوانیهای تکراری در نظر گرفته شده که در هنگام آغاز عملیات مقدار آن برابر با TRUE و در پایان آن برابر با FALSE انتخاب میگردد. همچنان که در ادامه توضیح داده خواهد شد کلاسهای مشتق شده متدهایی از لحاظ نام متناسب با عملی که برای آن در نظر گرفته شدهاند (ضبط یا پخش) برای بازگرداندن این مقدار به برنامهنویس کاربر این کلاسها دارند:
BOOL HSoundRunner::Start(WAVEFORMATEX* pwfex)
{
if(m_bRunning)
return FALSE;
if(pwfex != NULL)
m_wfData = *pwfex;
return TRUE;
}
BOOL HSoundRunner::Stop()
{
if(m_bRunning)
{
m_bRunning=FALSE;
Sleep(500);
return TRUE;
}
return FALSE;
}
فراخوانی استاندارد Sleep در متد Stop برای مصرف کامل بافر ایجاد شده انجام میگردد. در ضمن متد Start روشی برای جایگزینی مقدار پیشفرض m_wfData (عضو کلاس Hsound) با مقدار جدید در اختیار میگذارد.
در متد سازنده اعضای داده با مقادیر پیشفرض مقدارگذاری شده و رشتهی مورد نظر با فراخوانی CreateThead ایجاد میگردد:
HSoundRunner::HSoundRunner()
{
m_iBufferSize= 2048;
m_nBuffers = 0;
m_bRunning = FALSE;
m_nSamples=0;
m_pSamples=NULL;
m_pOwner=NULL;
CreateThread();
}
در متد ویرانگر نیز در صورتی که شیء از نوع این کلاس در حال انجام عملیات پردازش صوت باشد متوقف خواهد شد:
HSoundRunner::~HSoundRunner()
{
if(m_bRunning)
Stop();
}
به لحاظ آن که آرایهی دادهها (m_pSamples) در این کلاس ایجاد نمیگردد در متد ویرانگر آزاد شدن آن پیش بینی نشده است.
2-4-3- ضبط صدا
برای ضبط صدا و انجام پردازشهای مرتبط با آن کلاسی به نام HSoundRecorder به صورت زیر از کلاس HSoundRunner مشتق گردید:
class HSoundRecorder : public HSoundRunner
{
DECLARE_DYNCREATE(HSoundRecorder)
public:
HSoundRecorder();
virtual ~HSoundRecorder();
protected:
void AddBuffer();
//Message Map For WM_WIM_DATA:
afx_msg void OnDataReady(UINT uParm, LONG lWaveHdr);
private:
HWAVEIN m_hWaveIn;
HShortQueue* m_pQueue;
public:
BOOL Start(WAVEFORMATEX* pwfex=NULL);
BOOL Stop();
short* GetSamples(int& nSamples);
BOOL IsRecording();
DECLARE_MESSAGE_MAP()
};
برای استفاده از این کلاس کافی است متدهای Start و Stop آن فراخوانی گردند ولی درک کامل نحوهی عملکرد آن نیاز به برخی مقدمات دارد.
برای شروع کار ضبط از فراخوانی ای.پی.آی زیر با پارامترهای مناسب برای در اختیار گرفتن یک ابزار ورودی صدا استفاده میکنیم:
MMRESULT waveInOpen(LPHWAVEIN phwi, UINT uDeviceID, LPWAVEFORMATEX pwfx, DWORD dwCallback, DWORD dwCallbackInstance, DWORD fdwOpen);
که در آن phwi اشارهگر به بافری است که یک handle به ابزار باز شده برای ورودی صدا را در اختیار میگذارد. این پارامتر ابزاری را برای دسترسی به وسیلهی ورودی صدا در اختیار میگذارد که ما در سایر فراخوانیهای مرتبط به آن نیاز داریم لذا در کلاس تعریف شده متغیر m_hWaveIn را برای ذخیرهی این پارامتر پس از این فراخوانی و دسترسی به آن در سایر متدها در نظر گرفتهایم.
پارامتر uDeviceID شناسهی ابزار ورودی را به تابع میدهد. میتوان از شناسهی WAVE_MAPPER استفاده کرد که با استفاده از آن برنامه سختافزار پیشفرض موجود را که دارای قابلیت پردازش فرمت انتخاب شده که توسط پارمتر pwfx به تابع داده میشود و ما از عضو دادهی m_wfData از کلاس HSound برای انتخاب مقدار آن استفاده میکنیم به طور خودکار انتخاب میکند.
پارامتر dwCallback شناسهی پنجره، پردازه یا رشتهای را که پیامهای چندرسانهای به آن ارسال خواهد شد به تابع میدهد که ما از شناسهی رشته (عضو دادهی m_dwThreadID) برای تعیین این پارامتر استفاده خواهیم نمود. پارامتر بعدی dwCallbackInstance دادهی سطح کاربری را که به ساز و کار فرتخوانی callback ارسال میشود تعیین مینماید و ما از این پارامتر استفاده نخواهیم نمود.
پارامتر آخر یعنی fdwOpen پرچمی برای ابزار ورودی است که سازوکار تفسیر پارامترها را مشخص میکند و چون ما از سازوکار فراخوانی رشتهای استفاده میکنیم مقدار آن را برابر با CALLBACK_THREAD انتخاب مینماییم.
مقدار بازگشتی در صورت بروز اشکال غیرصفر خواهد بود مسائلی از قبیل اختصاص یافتن وسیلهی ورودی به یک پردازهی دیگر به صورتی که سیستم عامل به صورت اشتراکی آن را در اختیار نگذارد، کمبود حافظه و … ممکن است باعث بروز اشکال شوند که نوع اشکال با توجه به مقدار بازگشتی مشخص میگردد و میتواند به کاربر اعلام گردد.
بعد از در اختیار گرفتن یک وسیلهی ورودی لازم است که برای عملیات حافظه اختصاص یابد و این عمل میتواند با فراخوانی AddBuffer به تعداد کافی صورت گیرد.
بعد از تخصیص حافظه توسط فراخوانی ای.پی.آی زیر عمل ضبط شروع میگردد:
MMRESULT waveInStart(HWAVEIN hwi);
پارامتر وروی همان پارامتر بازگشت با مقدار فراخوانی waveInOpen یعنی phwi است که همچنانکه اشاره شد ما آن را در عضو دادهی m_hWaveIn نگهداری میکنیم. این فراخوانی نیز مانند قبلی در صورت موفقیتآمیز بودن مقدار صفر باز میگرداند.
توضیحات بالا مقدمات کافی را برای درک کد متد Start که در زیر میآید فراهم میآورد:
BOOL HSoundRecorder::Start(WAVEFORMATEX* pwfex)
{
if(!HSoundRunner::Start(pwfex))
return FALSE;
m_pQueue=new HShortQueue;
//Open the wave device:
if(::waveInOpen(&m_hWaveIn, WAVE_MAPPER, &m_wfData, m_dwThreadID, 0L, CALLBACK_THREAD))
return FALSE;
//Add several buffers to queue:
for(int i=0;i<3;i++)
AddBuffer();
if(::waveInStart(m_hWaveIn))
return FALSE;
m_bRunning=TRUE;
return TRUE;
}
اما توابع چندرسانهای ویندوز سازوکار خاصی برای اضافه کردن بافر دارند که میبایست آنها را در نسخهی بازنویسی شدهی AddBuffer این کلاس لحاظ کنیم. برای اضافه کردن یک بافر ابتدا باید آن را توسط فراخوانی زیر برای استفاده آماده کنیم:
MMRESULT waveInPrepareHeader(HWAVEIN hwi, LPWAVEHDR pwh, UINT cbwh);
به جای پارامتر hwi عضو دادهی m_hWaveIn را که قبلاً در فراخوانی waveInOpen مقدارگذاری شده قرار میدهیم. پارامتر دوم یک اشارهگر به متغیری با ساختار زیر است:
typedef struct {
LPSTR lpData;
DWORD dwBufferLength;
DWORD dwBytesRecorded;
DWORD dwUser;
DWORD dwFlags;
DWORD dwLoops;
struct wavehdr_tag * lpNext;
DWORD reserved;
} WAVEHDRR;
که لازم است اشارهگر lpData به یک حافظه حاوی تعداد مورد نیاز عضو اشاره کند. از آنجا که ما هر بار بافری با اندازهی m_iBufferSize در نظر میگیریم، تعداد خانههای این آرایه بر حس ب بایت برابر با اندازهی بافر ضرب در حداقل تعداد بلوک برای فرمت انتخاب شده (فیلد nBlockAlign ساختار WAVEFORMATEX) میباشد و لازم است که به این تعداد حافظه اختصاص داده اشارهگر lpData را برابر با آدرس آن انتخاب کنیم، در ضمن اندازهی بافر اختصاص داده شده را از طریق فیلد dwBufferLength به اطلاع تابع استفاده کننده میرسانیم. پارامتر آخر فراخوانی مورد بحث باید برابر با اندازهی پارامتر دوم بر حسب بایت قرار داده شود.
بعد از آماده شدن بافر آن را توسط فراخوانی زیر به بافرهای آماده برای اعمال چندرسانهای اضافه میکنیم:
MMRESULT waveInAddBuffer(HWAVEIN hwi, LPWAVEHDR pwh, UINT cbwh);
مانند فراخوانیهای قبل مقدار خروجی دو فراخوانی اخیر در صورت عدم بروز خطا صفر خواهد بود. کد زیر پیادهسازی کامل متد بازنویسی شدهی AddBuffer را برای کلاس HSoundRecorder به نمایش میگذارد:
void HSoundRecorder::AddBuffer()
{
//new a buffer:
char *sBuf=new char[m_wfData.nBlockAlign*m_iBufferSize];
//new a header:
LPWAVEHDR pHdr=new WAVEHDR;
if(!pHdr) return;
ZeroMemory(pHdr,sizeof(WAVEHDR));
pHdr->lpData=sBuf;
pHdr->dwBufferLength=m_wfData.nBlockAlign*m_iBufferSize;
//prepare it:
::waveInPrepareHeader(m_hWaveIn, pHdr, sizeof(WAVEHDR));
//add it:
::waveInAddBuffer(m_hWaveIn, pHdr, sizeof(WAVEHDR));
HSoundRunner::AddBuffer();
}
بعد از آن که عمل ضبط آغاز شد و پس از پر شدن هر بافر پیغامی به پنجره یا رشتهای که شناسهی آن به فراخوانی waveInOpen داده شده ارسال میگردد که با شناسهی MM_WIM_DATA میتوان به آن مراجعه نمود. در هنگام فعال شدن این پیغام لازم است بافر استفاده شده برای استفادهی مجدد آماده گردد و در ضمن مکان مناسب برای ذخیرهی دادههای ضبط شده و همچنین نمایش آنها پس از فعال شدن این پیغام است.
از آنجا که طول زمان ضبط صدا مشخص نیست طول بافری که نهایتاً دادهها باید در آن قرار گیرند قابل پیشبینی نمیباشد. از این رو ما از یک ساختار که نوع آن را HShortPocket نامگذاری کردهایم برای ذخیرهی دادههای ارسال شده استفاده مینماییم و حاصل را در صفی که در قالب کلاس HShortQueue پیادهسازی شده درج مینماییم.(این دو ساختار ربطی به برنامهنویسی پردازش صدا ندارند و درک عملکرد آنها نیاز به توضیح اضافی ندارد لذا در اینجا توضیح داده نمیشوند.) عضو دادهی m_pQueue از کلاس HSoundRecorder صفی است که در سطور قبل در مورد آن بحث شد.
ما به شیوهی ام.اف.سی برای پیغام MM_WIM_DATA تابعی به نام OnDataReady میسازیم که پارامترهای آن پارامترهای ارسالی از طرف پیغام هستند که دومین آنها که حاوی ساختار بافر استفاده شده است برای ما اهمیت دارد. با توجه به توضیحات داده شده درک کد این تابع میسر است:
void HSoundRecorder::OnDataReady(UINT uParm, LONG lWaveHdr)
{
LPWAVEHDR pHdr=(LPWAVEHDR)lWaveHdr;
::waveInUnprepareHeader(m_hWaveIn, pHdr, sizeof(WAVEHDR));
if(m_bRunning)
{
//Save Input Data:
m_pQueue->InsertItem(pHdr->dwBytesRecorded/2, (short*)pHdr->lpData);
//Draw Buffer:
DrawBuffer(pHdr->dwBytesRecorded/2, (short*)pHdr->lpData);
//reuse the header:
::waveInPrepareHeader(m_hWaveIn, pHdr, sizeof(WAVEHDR));
::waveInAddBuffer(m_hWaveIn, pHdr, sizeof(WAVEHDR));
return;
}
//we are stopping:
delete pHdr->lpData;
delete pHdr;
m_nBuffers–;
}
در صورتی که متد Stop احضار شده باشد مقدار m_bRunning برابر با FALSE است در این هنگام نه تنها نیازی به اضافه کردن بافر نداریم بلکه میتوانیم بافرهای اختصاص داده شده را آزاد کنیم. قسمت آخر کد چنین عملی را انجام میدهد.
پس از انجام عمل و احضار متدStop توسط برنامه لازم است با فراخوانی waveInStop عمل ضبط را متوقف کنیم و با فراخوانی waveInClose ابزار ضبط آن را برای استفادهی سایر برنامهها آزاد کنیم. علاوه بر این در این هنگام تمامی بافرها ارسال شدهاند و میتوانیم آن را به صورت یک آرایهی معمولی ذخیره کنیم و متغیر m_pQueue را آزاد نماییم:
BOOL HSoundRecorder::Stop()
{
if(!HSoundRunner::Stop())
return FALSE;
::waveInStop(m_hWaveIn);
::waveInClose(m_hWaveIn);
m_pSamples=m_pQueue->ConvertToArray(m_nSamples);
delete m_pQueue;
return TRUE;
}
پس از انجام این عمل برنامه میتواند با فراخوانی GetSamples به آرایهی حاوی صدای ضبط شده دسترسی پیدا کند:
short* HSoundRecorder::GetSamples(int& nSamples)
{
nSamples=m_nSamples;
return m_pSamples;
}
این آرایه در هنگام آزاد شدن متغیر از نوع HSoundRecorder در متد ویرانگر آزاد میشود:
HSoundRecorder::~HSoundRecorder()
{
if(m_pSamples)
delete []m_pSamples;
}
در متد سازندهی کلاس پدر مقدار m_pOwner برابر با NULL در نظر گرفته میشود. این به این معنی است که در حالت پیشفرض عملیات به صورت گرافیکی نشان داده نمیشود و برای انجام این عمل لازم است که ابتدا مقدار m_pOwner به اشارهگر به یک پنجره یا کنترل توسط فراخوانی SetOwner مقدارگذاری شود. در متد سازندهی این کلاس به منظور جلوگیری از مقدارگزینیهای ناخواسته مقدار m_hWaveIn برابر با NULL انتخاب میگردد:
HSoundRecorder::HSoundRecorder()
{
m_hWaveIn =NULL;
}
2-4-4- پخش صدا
پردازشهای مربوط به پخش صدا مشابهت زیادی با پردازشهای مربوط به ضبط دارد در اینجا نیز باید ابتدا یک ابزار صدا را برای خروجی باز کرد، تعدادی بافر اضافه نمود، در تابع پیام بافرهای جدید آماده نمود و سرانجام در متد Stop ابزار خروجی را بست:
class HSoundPlayer:
public HSoundRunner
{
public:
HSoundPlayer();
~HSoundPlayer();
void SetData(int nSamples, short* pSamples);
BOOL Start(WAVEFORMATEX* format=NULL);
BOOL Start(int iSize, short* pData, WAVEFORMATEX* pwfex=NULL);
BOOL Stop();
BOOL IsPlaying();
void AddBuffer();
DECLARE_MESSAGE_MAP()
afx_msg void OnMM_WOM_DONE(UINT parm1, LONG parm2);
private:
HWAVEOUT m_hWaveOut;
int m_nSamplesPlayed;
};
تفاوت تنها در این مورد است که در اینجا ما باید دادههای آماده را به برنامه بدهیم. به دلیل آن که در برنامههای ما خروجی همیشه پس از ورودی مطرح میگردد و ما پس از پایان ورودی به دادههای آن دسترسی داریم سادهترین راه دادن دادهها مقداردهی اشارهگر m_pSamples با بافر حاوی دادههای ورودی است که معمولاُ ما آن را از شیء ضبط کننده میگیریم:
void HSoundPlayer::SetData(int iSize, short* pData)
{
m_nSamples=iSize;
m_pSamples=pData;
}
به منظور افزایش انعطافپذیری میتوان این دادهها را در متد Start نیز دریافت نمود:
BOOL HSoundPlayer::Start(int iSize, short* pData, WAVEFORMATEX* format)
{
SetData(iSize, pData);
return Start(format);
}
فراخوانی waveOutOpen عملی مشابه waveInOpen را برای خروجی صدا انجام میدهد و پارامترهای آن مشابه با آن است:
BOOL HSoundPlayer::Start(WAVEFORMATEX* format)
{
if(m_pSamples==NULL)
return FALSE;
if(!HSoundRunner::Start(format))
return FALSE;
else
{
// open wavein device
MMRESULT mmReturn = 0;
mmReturn = ::waveOutOpen(&m_hWaveOut, WAVE_MAPPER, &m_wfData, m_dwThreadID, NULL, CALLBACK_THREAD);
if(mmReturn)
return FALSE;
else
{
m_bRunning = TRUE;
m_nSamplesPlayed=0;
for(int i=0; i<3; i++)
AddBuffer();
}
}
return TRUE;
}
در اینجا تفاوتی نیز وجود دارد. در فرایند ضبط این برنامهی کاربر بود که پیغام Stop را ارسال میکرد حال آن که در اینجا علاوه بر کاربر، تمام شدن بافر حاوی دادهها نیز باید باعث فعال شدن آن پیغام شود. برای این منظور از متغیر شمارشگری به نام m_pSamplesPlayed استفاده کردهایم که تعداد نمونههای پخش شده بر حسب تعداد حافظهی short (که نصف تعداد نمونه در حافظهی معادل بر حسب بایت است) را ذخیره میکند.
تفاوت دیگری نیز وجود دارد و آن این است که ما باید توسط فراخوانی waveOutWrite دادهها را روی بافر ارسالی بنویسیم:
void HSoundPlayer::AddBuffer()
{
MMRESULT mmReturn = 0;
// create the header
LPWAVEHDR pHdr = new WAVEHDR;
if(pHdr == NULL) return;
// new a buffer
pHdr->lpData=(char*)(m_pSamples+m_nSamplesPlayed);//buffer;
pHdr->dwBufferLength = m_iBufferSize;
pHdr->dwFlags = 0;
// prepare it
mmReturn=::waveOutPrepareHeader(m_hWaveOut, pHdr, sizeof(WAVEHDR));
// write the buffer to output queue
mmReturn =::waveOutWrite(m_hWaveOut, pHdr,sizeof(WAVEHDR));
if(mmReturn) return;
// increment the number of waiting buffers
m_nSamplesPlayed+=m_iBufferSize/2;
HSoundRunner::AddBuffer();
}
در انجام عمل پخش نیز پیغامی پس از پایان پخش هر بافر با شناسهی MM_WON_DONE به پنجره یا رشتهی کنترل کننده ارسال میشود که در آن میتوانیم دادهی پخش شده را به صورت گرافیکی نشان دهیم، بافر بعدی را بفرستیم و در صورت رسیدن به پایان دادهها پیغام Stop را ارسال کنیم:
void HSoundPlayer::OnMM_WOM_DONE(UINT parm1, LONG parm2)
{
LPWAVEHDR pHdr = (LPWAVEHDR) parm2;
//Draw Buffer:
DrawBuffer(pHdr->dwBufferLength/2, (short*)pHdr->lpData);
if(::waveOutUnprepareHeader(m_hWaveOut, pHdr, sizeof(WAVEHDR)))
return;
m_nBuffers–;
if(m_bRunning)
{
if(!(m_nSamplesPlayed+m_iBufferSize/2>=m_nSamples))
{
AddBuffer();
// delete old header
delete pHdr;
return;
}
else
{
Stop();
}
}
// we are closing the waveOut handle,
// all data must be deleted
// this buffer was allocated in Start()
delete pHdr;
if(m_nBuffers == 0 && m_bRunning == false)
{
if (::waveOutClose(m_hWaveOut))
return;
}
}
اگر دقت کرده باشید در هنگام رسیدن به پایان دادهها در همین تابع اخیر ما ابزار خروجی را میبندیم. اگر زودتر پیغام Stop توسط برنامه ارسال شود نیز به لحاظ FALSE شدن مقدار m_bRunning این عمل انجام میپذیرد لذا کافی است که در متد Stop ابزار برای استفادهی بعدی به طور کامل آزاد گردد:
BOOL HSoundPlayer::Stop()
{
if(HSoundRunner::Stop())
return (::waveOutReset(m_hWaveOut)!=0);
return FALSE;
}
از آنجا که در این کلاس حافظهای اختصاص داده نمیشود در متد ویرانگری نیز آزاد شدن حافظه انجام نمیگیرد. مشابه متد سازندهی کلاس HSoundPlayer مقدار m_hWaveOut در ابتدا برابر با NULL در نظر گرفته میشود:
HSoundPlayer::HSoundPlayer()
{
m_hWaveOut = NULL;
}
2-4-5- کتابخانهی پردازش صوت
از آنجا که کلاسهای پیادهسازی شده که در این فصل توضیح داده شدند مورد استفادهی بیش از یک برنامه قرار گرفتهاند آنها را به صورت یک کتابخانهی ایستا و با نام HSoundLib گردآوری نمودیم تا تغییر کد این کتابخانه راحتتر در تمامی برنامهها اعمال گردد و نیاز به تغییر کد تک تک آنها نباشد.
فصل سوم – پردازش گفتار
3-1- ترکیب و تشخیص گفتار
کاربردهای نیازمند پردازش صحبت اغلب در دو دستهی ترکیب صحبت و تشخیص صحبت مورد بررسی قرار میگیرند.
ترکیب صحبت عبارت است از فنآوری تولید مصنوعی صحبت به وسیلهی ماشین و به طور عمده از پروندههای متنی به عنوان ورودی آن استفاده میگردد. در اینجا باید به یک نکتهی مهم اشاره شود که بسیاری از تولیدات تجاری که صدای شبیه به صحبت انسان ایجاد میکنند در واقع ترکیب صحبت انجام نمیدهند بلکه تنها یک تکهی ضبط شده به صورت دیجیتال از صدای انسان را پخش میکنند. این روش کیفیت صدای بالایی ایجاد میکند اما به واژهها و عبارات از پیش ضبط شده محدود است. از کاربردهای عمدهی ترکیب صحبت میتوان به ایجاد ابزارهایی برای افراد دارای ناتوانی بینایی برای مطلع شدن از آنچه بر روی صفحهی کامپیوتر میگذرد اشاره کرد.
تشخیص صحبت عبارت است از تشخیص کامپیوتری صحبت تولید شده توسط انسان و تبدیل آن به یک سری فرامین یا پروندههای متنی. کاربردهای عمدهی موجود برای این گونه سیستمها دربرگیرندهی بازهی گستردهای از سیستمها وکاربردها از سیستمهای دیکتهی کامپیوتری که در سیستمهای آموزشی و همچنین سیستمهای پردازش واژه کاربرد دارد گرفته تا سیستمهای کنترل کامپیوترها به وسیلهی صحبت و به طور خاص سیستمهای فراهم آورندهی امکان کنترل کامپیوترها برای افراد ناتوان از لحاظ بینایی یا حرکتی میباشد.
کاربرد مورد نظر ما یعنی تشخیص گفتار از لحاظ نحوهی پیادهسازی و استفاده تناسب فراوانی با خانوادهی دوم یعنی تشخیص کامپیوتری صحبت دارد، ولی از لحاظ اهداف و کاربردها میتواند در خانوادهای جداگانه از کاربردهای نیازمند پردازش صحبت قرار گیرد.
3-2- آواشناسی
آواشناسی دانش بررسی آواها و صداهای گفتاری است.و به دلیل ارتباطات خیلی قوی که با فناوری تشخیص گفتار دارد به صورت خلاصه به بررسی آن می پردازیم.
این دانش که بخشی از زبانشناسی بشمار میآید با بررسی سرشت آواها و شیوههای تولید آنها سر و کار دارد. با اینکه حروف نوشتاری بازتابدهنده آواهای گفتاری انسانها هستند ولی زمینه کاری آواشناسان بیشتر درباره اصوات گفتار است تا نمادهایی که آنها را بازتاب میدهند. هرچند بخاطر پیوندد تنگاتنگ این دو مقوله، برخی از واژهنامهها دانش بررسی نمادها و حروف (یعنی نشانهشناسی) را همچون بخشی از مطالعات آوایی معرفی میکنند
وقتی با کلمه آواشناسی روبرو می شویم مراحل تولید اصوات در ذهن ما تداعی می شود و عقیده اکثر افراد بر این است که آواشناسی علمی است که چگونگی تولید اصوات را بررسی می کند. ولی آیا فقط با تولید اصوات رابطه زبانی بین سخنگو و مخاطب برقرار می شود ؟ قطعا چنین نیست .اگر ما سخن بگوییم بدون اینکه مخاطب ما سخنانمان را بفهمد ارتباط زبانی برقرار نشده است .بنابراین اگرچه اولین مرحله در برقراری ارتباط تولید صوت توسط سخنگوست اما برای برقراری ارتباط زبانی کافی نیست. قبل از اینکه سخنگو شروع به صحبت کند تصمیم می گیرد که چه بگوید و این مغز است که پیغام تولید صوت را بر اساس آنچه سخنگو در نظر دارد به اندام های تولید صوت می رساند .پس از رسیدن این پیام، اندام های صوتی شروع به تولید صوت برای رساندن منظورومفهومی خاص می کنند. این اصوات امواج صوتی هستند که توسط هوا در فضا جا به جا می شوند و به گوش مخاطب یا مخاطبین می رسند بنابراین بین سخنگو و مخاطب، اصوات به صورت امواج صوتی منتقل می- شوند. این امواج به گوش مخاطب رسیده وپیغام های عصبی تولید می کند که به مغز می رود و در مغز تجزیه وتحلیل می شود و منظور سخنگو به مخاطب می رسد. پس آواشناسی مطالعه صداهای گفتار است و مطالعه تولید ذات فیزیکی و درک صداها. بنابراین آواشناسی شامل سه بخش می شود :
- آواشناسی تولیدی(ساختمان دستگاه گفتاری انسان که در این قسمت با زیست شناسی و پزشکی ارتباط پیدا می کنیم)
- آواشناسی آکوستیک (بررسی امواج صوتی که با فیزیک و ریاضی مرتبط می شویم)
- آواشناسی شنیداری(در حیطه زیست شناسی، پزشکی، روان شناسی، عصب شناسی و… وارد می شویم)
اما چگونگی تولید صوت:
اما چطور صداها تولید می شوند. بعنوان مثال اندام های مختلف درون دهان، گلو و بینی جریان های هوای از شش ها را تغییر می دهد صدا بوسیله حرکات سریع مولکولها هوا تولید می شود. اغلب صداها در زبانهای گتفاری انسان بوسیله خروج هوا از داخل ششها و گذر آن از میان نای، حنجره تولید می شوند. حنجره شامل دو چین کوچک ماهیچه ای است که می توانند همراه با یکدیگر یا جداگانه حرکت کنند. فضای بین این دو چین دهانه حنجره[67] نام دارد. اگر این دو قسمت با هم بسته شوند (اما نه کاملاً بسته) هنگام عبور هوا به ارتعاش در می آیند. اگر بین آنها فاصله زیاد باشد نوسان نخواهندد کرد. در زبان انگلیسی صداهایی که بوسیله این لرزش بوجود می آیند شامل z,v,g,d,b و همه مصوت های دیگر Voiced نامیده می شوند و صداهایی که بدون لرزش این اندامها ایجاد می شوند صداهای گنگ نام دارند مثل f,t,k,p و …
ناحیه بالای نای قسمت صوتی نامیده می شود ه شامل بخش زبانی و بخش تودماغی[68] می شود. بعد از اینکه صدا از نای خارج شد می تواند از دهان یا بینی خارج می شود. اغلب صداها بوسیله گذر از میان دهان ایجاد می شوند. صداهایی که بوسیله عبور هوا از طریق بینی ایجاد می شوند صداهاا تودماغی نام دارند. این صداها از قسمتهای زبانی و دماغی بعنوان اسباب ارتعاش استفاده می کنند. صداهای تودماغی انگلیسی مانند m,n,ng و..
پس به طور خلاصه می توان گفت:
وقتی کسی صحبت می کند هوای داخل ششها از میان دو پرده نازک در نای به تمام تارهای صوتی عبور می کند این دو پرده نازک که مرتعش شده و هوا را جبهه جبهه (کپه کپه)به بیرون می فرستد. در هر ثانیه صدها و گاهی اوقات هزاران جبهه هوا ساخته می شود بطوریکه هوا بین گلو و دهان با مکانیزمم لوله ها ی صوتی مرتعش می شود این ارتعش تحت تاثیر چگونگی قرار گرفتن زبان ـ دندانها ـ لب و سایر عوامل قرارمی گیرد .این هوای مرتعش باعثث تغییرات جزئی در اطراف شخص صحبت کننده می شود که به آن صوت می گوییم .
صداها به دو کلاس اصلی تقسیم می شوند. حروف بی صدا و مصوتها. هر دو نوع بوسیله حرکت صدا از میان دهان، نای یا بینی شکل می گیرند. حروف بی صدا مانند z,s,v,f,q و k,d,t,b,pو حروف صدادار مانند aa,ae,aw,ao,ih,ow .
حروف نیمه صدادار مانند w,y مشخصاتی از هردو دارند. آنها شبیه حروف صدادار هستند اما کوتاه و دارای هجاهای شمرده کمتر هستند(مانند حروف بی صدا)
3-3- مکانیزم تولید گفتار
شکل3-1
مکانیزم تولید گفتار از چهار پروسه تشکیل شده است:
- پردازش زبان که در آن محتوای گفتار در مرکز زبانی مغز به سمبل های صوتی تبدیل می شود.
- تولید فرمان های موتوری که به سمت اندام های صوتی در مرکز موتوری مغز صورت می گیرد.
- حرکت هماهنگ اندام های صوتی که بر پایه فرمان های ارسال شده از مرکز موتوری مغز انجام می شود.
- انتشار هوای فرستاده شده از سمت ریه ها به صورت گفتار.
متغیرهای ناحیه صوتی:
- میزان باز بودن آرواره
- میزان باز بودن و جلو آمدن لب ها
- فرم زبان
- میزان باز بودن بخش نرم سقف زبان[69] که اتصال ناحیه صوتی را به حفره های داخلی بینی را تنظیم می کند.
برخی از نکات اساسی دراین زمینه:
کار مرکز موتوری مغز بسته به صورت مورد نظر فرق می کند. به عنوان مثال برای گفتن حرف /p/، فقط میزان باز بودن لب ها و بخش نرم سقف زبان تعیین می شود.
از طرفی انسان می تواند سخنی را که می شنود، بدون آنکه ضرورتاً قادر به صحبت کردن به آن خاص باشد، تقلید کند. این بدآن معناست که انسان می تواند حرکات دهان که برای تولید صدایی شبیه به آنچه که قبلا شنیده، لازم است، تخمین بزند.
به فضای بین تارهای صوتیglottis گفته می شود. سقف یا کام دهان[70] دارای دو بخش سخت و نرم می باشد. به بخش سخت آن معمولا همان پالت اطلاق می شود. بخش نرم سقف دهان، بعد از بخش سخت آن قرار دارد که به آن بخش نرم سقف زبان گفته می شود. زبان در تلفظ /k/ حرف به اینن قسمت از کام برخورد می کند. بخش نرم سقف زبان همچنین می تواند حرکت کند. وقتی پایین است، دریچه ای ایجاد می کند که اجازه می دهد جریان هوا به سمت بینی برود. وقتی بالاست، دریچه مسدود می شود و هیچ هوایی نمی تواند به درون بینی جاری شود. زبان کوچک در پشت بخش نرم سقف زبان قرار دارد. در بعضی از لهجه های فرانسوی در حین تلفظ صدای /r/ این قسمت می لرزد. اپی گلاتیس[71] زیر ریشه زبان قرار دارد و در پوشاندنن حنجره در هنگام بلعیدن غذا کمک می کند تا غذا وارد معده شده و وارد ریه ها نشود. در بعضی از زبان ها برای تولید صدا از این قسمت استفاده می کنندد که زبان انگلیسی در این گروه قرار نمی گیرد. همچنین تارهای صوتی در مسیر هوایی ریه ها قرار دارد. آنها با لرزیدن بیشتر صداها را در حین صحبت کردن به وجود می آورند از طرفی حنجره ساختاری است که تارهای صوتی را در بر دارد. و به پایین ترین قسمت زبان در گلو، ریشه زبان گفته می شود. به قسمت اصلی زبان، بدنه زبان گفته می شود. بدنه زبان به ویژه بخش انتهایی آن در ساختن حروف صدادار و برخی حروف بی صدا، حرکت می کند.
یک نوزاد چگونه مهارت موتوری لازم برای تولید آواهای مربوط به زبان خودش را کسب می کند؟
تعامل بین بخش های متفاوت باید متغیر با زمان باشد. در زمانی که نوزاد رشد میکند، مشخصه های فیزیکی مانند اندازه ناحیه صوتی و شکل آرتیکورلاتورها تغییر می کند. همچنین ممکن است آرتیکولاتورها دچار آسیب موقت یا دائم شوند. این تغییرات بر روی سینگنال آکوستیکی که توسط یک سری فرمان های قشر موتوری مغز تولید شده است تاثیر می گذارد. برای اینکه ویژگی سیگنال آکوستیکی موردنظر در شرایط متفاوت حفظ شود، لازم است که چگونگی تعامل بین بخش های آکوستیکی و سنسوری و موتوری با گذشت زمان تغییر می کند. این بدان معناست که سیستم تولید گفتار باید تطبیق پذیر باشد.
در فرآیند تولید گفتار به طور ذاتی، فعالیت های متفاوت موتوری برای تولید یک صوت گفتار یکسان می تواند مورد استفاده قرار گیرد. به زبان ریاضی، یک نگاشت چند به یک از قشر موتوری به تولید یک صوت وجود دارد.
به عنوان مثال بلوک دیاگرام زیرمدل استفاده از دو نوع ساختار عصبی برای نشان دادن اطلاعات را ارائه می دهد
3-4- مدلی برای توصیف روش تولید صحبت
تقریباً تمام تکنیکهای ترکیب و تشخیص صحبت بر اساس مدل تولید صحبت انسان که در شکل شماره ۳ نشان داده شده است ایجاد شدهاند. بیشتر صداهای مربوط به صحبت انسان به دو دستهی صدادارو سایشی تقسیم میشوند. اصوات صدادار وقتی که هوا از ریهها و از مسیر تارهای صوتی به بیرون دهان یا بینی رانده میشوند ایجاد میگردند. تارهای صوتی دو رشتهی آویخته از بافت هستند که در مسیر جریان هوا کشیده شدهاند. در پاسخ به کشش ماهیچهای متفاوت تارهای صوتی با فرکانسی بین ۵۰ تا ۱۰۰۰هرتز ارتعاش میکنند که باعث انتقال حرکتهای متناوب هوا به نای میشود. در شکل شماره ۳ اصوات صدادار با یک مولد پالس بالا پارامتر قابل تنظیم پیچ (فرکانس پایهی موج صوتی) نشان داده شده است.
در مقایسه، اصوات سایشی به صورت نویز تصادفی و نه حاصل از ارتعاش تارهای صوتی به وجود میآیند. این حادثه زمانی رخ میدهد که تقریباً جریان هوا به وسیلهی زبان و لبها یا دندانها حبس میشود که این امر باعث ایجاد اغتشاش هوا در نزدیکی محل فشردگی میگردد
شکل شماره ۳-4- مدل صحبت انسان. در یک تکه زمان کوتاه، حدود ۲ تا ۴۰ میلیثانیه صحبت میتواند با استفاده از سه پارامتر مدلسازی شود: ۱- انتخاب یک آشفتگی متناوب یا نویزوار. ۲- پیچ آشفتگی متناوب ۳ – ضرایب یک فیلتر خطی بازگشتی که پاسخ اثر صوتی را تقلید میکند.
اصوات سایشی زبان انگلیسی عبارتند از s، f، sh، z، v و th. در مدل شکل شماره ۳ اصوات سایشی با استفاده از یک مولد نویز نشان داده شدهاند.
هر دو نوع این اصوات، توسط چالههای صوتی که از زبان، لبها، دهان، گلو و گذرگاههای بینی تشکیل شدهاند دچار تغییر میشوند. چون انتشار صدا در این ساختارها یک فرایند خطی است میتواند با استفاده از یک فیلتر خطی با یک پاسخ ضربهی مناسب نمایش داده شود. در بیشتر موارد از یک فیلتر بازگشتی که ضرایب بازگشتی آن ویژگیهای فیلتر را مشخص میکند استفاده میشود. به خاطر این که چالههای صوتی ابعادی به اندازهی چند سانتیمتر دارند پاسخ فرکانسی یک دنباله از تشدیدها با اندازههای کیلوهرتزی است. در اصطلاح پردازش صوت این قلههای تشدید فرکانسهای فرمانت خوانده میشوند. با تغییر جایگاه نسبی زبان و لبها فرکانسهای فرمانت هم از لحاظ دامنه و هم از لحاظ فرکانس ممکن است تغییر کنند.
شکل شماره 3-۴ یک روش معمول برای نمایش سیگنالهای صحبت را نشان میدهد که طیفنگارهیا اثر صوت خوانده میشود. سیگنال صوتی به تکههای کوچک به اندازهی ۲ تا ۴۰ میلیثانیه تقسیم میشوند و از الگوریتم اف.اف.تی برای یافتن طیف فرکانسی هر تکه استفاده میشود. این طیفها در کنار هم قرار داده شده تبدیل به یک تصوبر سیاه و سفید میشود (دامنههای پایین روشن و دامنههای بالا تیره میشوند). این کار یک روش گرافیکی برای مشاهدهی این که چگونه محتویات فرکانسی صحبت با زمان تغییر میکند به وجود میآورد. اندازهی هر تکه بر اساس اعمال یک بدهبستان بین دقت فرکانسی (که با تکههای بزرگتر بهتر میشود) و دقت زمانی (که با تکههای کوچکتر بهتر میشود) انتخاب میگردد.
شکل شماره 3-5- طیف صوت. شکلهای a و b ویژگیهای عمومی اصوات صدادار و شکلهای c و d ویژگیهای عمومی اصوات سایشی را نمایش میدهند.
همچنانکه در شکل ۴ دیده میشود اصوات صدا دار مثل a در rain دارای موج صوتی متناوبی مانند آنچه در شکل a نشان داده شده و طیف فرکانسی آنها که عبارت است از یک دنباله از همسازهای با اندازهی منظم مانند شکل b میباشد در مقابل، اصوات سایشی مانند s در storm دارای یک سیگنال نویزی در دامنهی زمان مانند شکل c و یک طیف نویزی مانند شکل d هستند.این طیفها همچنین شکل فرکانسهای فرمانت برای هر دو نوع صوت نشان میدهند. همچنین به این نکته توجه کنید که نمایش زمان- فرکانس کلمهی rain در هر دو باری که ادا شده شبیه به هم است.
در یک دورهی کوتاه برای نمونه ۲۵ میلیثانیه یک سیگنال صحبت میتواند با مشخص کردن سه پارامتر تقریب زده شود:
- انتخاب یک اغتشاش متناوب یا نویزوار
- فرکانس موج متناوب (اگر مورد استفاده قرار گرفته باشد)
- ضرایب فیلتر دیجیتالی که برای تقلید پاسخ تارهای صوتی استفاده شده است.
صحبت پیوسته با بروزآوری این سه پارامتر به صورت پیوسته به اندازهی ۴۰ بار در ثانیه ترکیب شود. این راهکار برای یکی از کاربردهای تجاری دی.اس.پی که «صحبت و املا» نامیده میشود و یک وسیلهی الکترونیکی پرفروش برای بچههاست مناسب است. کیفیت صدای این نوع ترکیب کنندهی صحبت پایین است و بسیار مکانیکی و متفاوت با صدای انسان به نظر میرسد. ولی در هر صورت نرخ دادهی خیلی پایینی در حدود چند کیلوبیت بر ثانیه نیاز دارد.
همچنین این راهکار پایهای برای روش کدگذاری پیشگویانهی خطی (ال.پی.سی) در فشردهسازی صحبت فراهم میآورد. صحبت ضبط شدهی دیجیتالی انسان به تکههای کوچک تقسیم میشود و هر کدام با توجه به سه پارامتر مدل توصیف میشود. این عمل به طور معمول نیاز به یک دوجین بایت برای هر تکه دارد که نرخ دادهای برابر با ۲ تا ۶ کیلوبایت بر ثانیه را طلب میکند. این تکهی اطلاعاتی ارسال میشود و در صورت لزوم ذخیره میگردد و سپس توسط ترکیب کنندهی صحبت بازسازی میشود.
الگوریتمهای تشخیص صحبت با تلاش برای شناسایی الگوهای پارامترهای استخراج شده از این روش نیز پیشتر میروند. این روشها معمولاً شامل مقایسهی تکههای اطلاعاتی با قالبهای صدای از پیش ذخیره شده در تلاش برای تشخیص کلمات گفته شده میباشند. مشکلی که در اینجا وجود دارد این است که این روش همیشه به درستی کار نمیکند. این روش برای بعضی کاربردها قابل استفاده است اما با تواناییهای شنوندگان انسانی خیلی فاصله دارد.
3-5-مدلهای محاسباتی پردازش زبان و گفتار
مهمترین مدلهای محاسباتی پردازش زبان و گفتار که همان ماشین های اتومات می باشند که عبارتند از :
3-5-1- اتوماتهای متناهی (محدود) و عبارتهای منظم[72]:
در این بخش عبارات منظم را معرفی می کنیم که استانداری برای توصیف توالی های متنی است. اتوماتهای محدود نه فقط ابزاری ریاضی برای استفاده در عبارات منظم هستند بلکه یکی از ابزارهای مهم در زبانشناسی محاسباتی[73] است.
عبارات منظم ابزاز تئوری مهمی در تمامی علوم کامپیوتر و زبانشناسی است. یک عبارت منظم (که اولین بار توسط کلین[74] در سال 1956 گسترش یافت) قاعده ای است در یک زبان مشخص که در تکنیکهای جستجو بر اساس متن غالباً استفاده می شود. در یک رشته، هر توالی از کارکترهای الفباا عددی (شامل لغات، اعداد، فاصله ها، نشانه گذاری ها) است. در اینجا یک فاصله، درست مثل کاراکترهای دیگر است و ما آنرا بوسیله یک علامت نشان می دهیم.
یک عبارت منظم نمادهای جبری برای مشخص کردن مجموعه ای از رشته هاست. بنابراین آنها می توانند برای تعیین رشته های جستجو بخوبی استفاده شوند می خواهیم بحث را با صحبت درباره عبارات منظم بعنوان روشی برای انجام جستجو در متن آغاز کنیم و پیش برویم.
جستجو در عبارت منظم به یک الگو که می خواهیم جستجو کنیم به مجموعه ای از متون برای جستجو در آن احتیاج دارد، تابع جستجو که از میان مجموعه ای از متون عمل خواهد کرد، همه متونی که شامل الگو باشند را برمی گرداند در یک سیتسم بازیابی اطلاعات مانند یک موتور جستجوی وب، نتیاج ممکن است شامل همه مستندات یا صفحات وب شود. در یک پرداشگر لغت نتایج ممکن است لغات منحصربفرد یا شامل چند سند باشد. بنابراین زمانی که ما الگوی جستجویی داریم، فرض خواهیم کرد که موتور جستجو خطی از سند را بر می گرداند این چیزی است که خط فرمان grep در یونیکس انجام می دهد.
-
-
-
- الگوهای عبارت منظم
-
-
ساده ترین نوع عبارت منظم، توالی از کارکترهای ساده است. بعنوان مثال برای جستجوی لغت ” Buttercup” ما عبارت / Buttercup/را تایپ می کنیم، بنابراین منظم / Buttercup/ با هر رشته ای شامل زیررشتهButtercup مطابقت می یابد.(بعنوان مثال خط Buttercup “ “Iam (called در اینجا ما علامت اسلش را اطراف هر عبارت منظمی قرار خواهیم داد تا از الگو تشخیص داده شود. اسلش بخشی از عبارت منظم نیست.
رشته جستجو می تواند شامل یک حرف (مثل /!/) یا توالی از حروف (مثل /urgl/) باشد. می توان برای جستجو تعیین کرد که تنها اولین مورد یافته شود یا بیشتر از یک مورد را بدهد.
عبارت منظم به بزرگ یا کوچک بودن حروف حساس است، یعنی شکل /s/ با حرف بزرگ آن یعنی /S/ متفاوت است. این یعنی اگر الگو /Woodchucks/ باشد، با رشته Woodchucks مطابقت ندارد. ما این مسئله را با استفاده از براکت، به معنی یا، حل می کنیم. یعنی الگوی /[Ww]/ با w یا W جور می شود و بهمین ترتیب داریم: /[A-Z]/ و/ / [a-z] و /[0-9]/
| موارد مطابقت یافته | عبارت منظم |
| Woodchuck یا woodchuck
‘a’ یا ‘b’ یا ‘c’ هر عددی |
/[Ww]oodchucks/
/[abc]/ /[1234567890]/ |
جدول 3-1
با استفاده از براکت می توان عبارت منظم را طوری تعریف کرد که شامل یک کارکتر نباشد. اینکار بوسیله علامت ^ انجام می شود که باید بعد از [ و قبل از حرفی که نباید در الگو باشد قرار گیرد. این تنها زمانی درست است که بعنوان اولین سمبل بعد از ] باشد و گرنه جزء خود عبارت در نظر گرفته می شود.
مثال:
| موارد مطابقت یافته | عبارت منظم |
| هیچ یک از حروف بزرگ انگلیسی
نه s یا نه S e یا ^ با الگوی a^b جور می شود |
[^A-Z]
[^Ss] [e^] a^b |
جدول 3-2
اما برای اینکه بتوانیم Woodchuck را از Woodchucks تشخیص دهیم باید چگونه عمل کنیم؟ چون می خواهیم s باشد یا نباشد نمی توان از [] استفاده کرد بنابراین از /?/ استفاده می کنیم به این معنی که یا حرف قبل از ؟ یا هیچ.
بنابراین:
| موارد مطابقت یافته | عبارت منظم |
| Woodchucksیا woodchuck
Colour یا color |
Woodchuc?s
Colou?r |
جدول 3-3
روشی برای اینکه بتوان تعداد یک چیز را مشخص کرد وجود دارد. مثلا برای اینکه یک عبارت منظم با این عبارات جور شود: …ba,baaa,baaaaaaa
می توان از *kleen (کلین استار) استفاده کرد که به معنی تعداد تکرار است. می تواند صفر یا بیشتر باشد. بنابراین //a * یعنی رشته ای از صفر یا تعداد بیشتری.aعبارت منظم//a * با این الگوها می تواند جور شود:
a,aa,aaaaa,…..
بنابراین عبارت منظمی که شامل حتما یک a و بیشتر است به اینصورت است: //aa *
//[ab] *یعنی عبارت منظمی که شامل صفر یا بیشتر از aها و یا bها است. یعنی الگوهایی مثل aaa,ababab,bbb یادآوری می کنیم کهRE برای یک عدد صحیح یک رقمی [0-9]/ /بود. REبرای یک عدد صحیح چند رقمی هم بصورت //[0-9][0-9] * است.
برای نمایش عدد صحیح چند رقمی بهتر است از Kleeen+ استفاده کنیم که به معنی تعداد یک یا بیشتر است. (برخلاف * که به معنی تعداد صفر یا بیشتر است)
یکی ازمهمترین کاراکترهای مخصوص نقطه است. /./ یک جایگزین شونده است که با هر کاراکتری مطابقت دارد.
مثال:
| مثال | موارد مطابقت یافته | عبارت منظم |
| Begin,beg,n,begun | هر کاراکتری که بین n,beg قرار می گیرد | /beg,n/ |
جدول 3-4
جایگزین شونده می تواند همراه با * برای هر رشته ای از کاراکترها استفاده شود. مثل /abbbas.*ali/ برای اینکه خود علامت شامل عبارت منظم شود باید از آن علامت بک اسلش قرارداد.مثال /the dog\./ در این حالت علامت نقطه دیگر به معنای کاراکتر جایگزینی نیست.
علامت /b (Anchor) هم مشخص کننده حدود کلمه است. مثلا برای عبارت منظم /\bThe\b/ الگوی The مطابقت دارد ولی Other نه. همچنین در مورد /\b99/ که با 99 جور می شود ولی با 299 نه.
-
-
-
- تفکیک، گروهبندی و اولویت :
-
-
جدا کننده: فرض کنیم عبارت جستجویی به صورت “Dog or Cat” داشته باشیم. یعنی حاصل جستجو شامل عباراتی که کلمات Dog یا Cat دارند است. در عبارت منظم این کار با براکت [] نمی توان انجام داد پس نیاز به عملگر جدیدی داریم بنام جداکننده یا Pipe (|). عبارت منظم /Dog|/Cat با رشته هایی کهه Dog یا Cat دارند مطابقت دارد. اما چگونه می توانیم عبارت منظم را هم برای الگوی Guppy و هم Gupies مشخص کنیم؟ مطمئناً RE اینطور نمی شود: /Guppy|ies/. بنابراین بوسیله پرانتز اولویت تعیین می کنیم که ابتدا عملگر جداکننده در نظر گرفته شود. یعنی RE صحیح اینطور می شود: /Guppy|ies)/
اگر * را همراه با () استفاده کنیم یعنی می توان رشته ای را که درون () است را صفربار یا بیشتر تکرار کرد. مثال : /(dog)*/
اولویت عملگرهای RE به این ترتیب است:
()
[]?+
Anchor و جملات
|(Pipe)
* از جملات اولویت بالاتری دارد
3-5-1-3- اتومات ها
- اتومات حالت محدود
عبارت منظم بیشتر از یک فراز زبان مناسب برای جستجوی متن است. اولا اینکه، عبارت منظم روشی برای وصف کردن ماشین حالت محدود (FSA) است. هر عبارت منظم می تواند بوسیله یک FSA اجرا شود و بطوربالعکس هر ماشین حالت محدود را می توان با یک عبارت منظم وصف کرد. دوم اینکه، RE روشی برای توصیف کردن نوعی ویژه از زبانهای رسمی بنام زبانهای منظم است. هر دوی عبارت منظم و FSA برای توصیف زبان منظم (زبان منظم مجموعه ای از رشته هاست که هر رشته از علامتهای تعریف شده آن زبان (آلفابت) تشکیل شده است). استفاده می شوند. اگرچه ما بحث را با کاربرد FSA در اجرای عبارات منظم شورع می کنیم ولی FSAها زمینه کاربرد وسیعی دارند.
2- استفاده از FSA در تشخیص صدای گوسفندی: baaa…
ما زبان گوسفندی را بعنوان رشته ای مطابق زیر تعریف کرده ایم: baa!,baaa!,baaaaa!,….
RE برای آن بصورت /Baa_!/ است و FSA برای آن به شکل زیر است:
اتومات یک گراف جهت دار است شامل تعداد محدودی راس (نود)، بهمراه تعدادی لینک بین هر جفت نود (Node) نودها بوسیله دایره و لینکها که نشانه انتقال از یک نود به نود دیگر است توسط پیکانهایی نمایش داده می شوند. FSA می تواند برای تشخیص (پذیرش) رشته یک زبان بکار برده شود.
اضافه کردن حالت Eeeor به ماشین:
شکل 3-6
-
-
-
- اتوماتهای محدود غیرقطعی (NFSA)
-
-
اجازه دهید بحثمان را در مورد کلاس دیگری از FSA ادامه دهیم، یعنی NFSA شکل زیر را ملاحظه کنید که چه شباهتی با شکل قبل دارد.
شکل 3-7
در این ماشین Error نداریم.
تفاوت بین این دو ماشین در این هست که حلقه تکرار ایجاد a در حالت q2 است بجای q3. این ماشین هم برای پذیرش صدای گوسفندی است. در این ماشین زمانی که به حالت q2 می رسیم اگر یک a ببینیم نمی دانیم که آیا باید در همین حالت بمانیم یا به حالت بعدی برویم. اتومات با این حالت تصمیم گیری را ماشین غیرقطعی می نامند و اتوماتی که برای هر ورودی مشخص است تا به چه حالتی برود ماشین قطعی گفته می شود.
-
-
-
- مبدلات حالت محدود و شکل شناسی
-
-
در قسمت های قبلی به معرفی عبارت منظم پرداختیم، بعنوان مثالی نشان دادیم که چگونه یک رشته مفرد توانست در پیدا کردن هر دو کلمه در موتور جستجو متنی استفاده شود. فرآیند جستجو برای یافتن حالت جمع یا مفرد این کلمه آسان است چون در حالت جمع به آخر آن تنها یک S اضافه می شود. اما فرض کنید که ما در جستجوی کلمات دیگری هستیمف مثلا goose,fish,fox فرآیند جستجو برای حالت جمع این کلمات چیزی بیشتر از اضافه شدن یک S است. حالت جمع fox,foxes است، برای goose، حالت جمع geese است همچنین برای کلمه fish که حالت جمع آن تغییر نمی کند و همان fish است.
قواعد املائی به ما می گویند که لغات انگلیسی که به y ختم می شوند هنگام جمع y به i تبدیل شده و به آخر آن es اضافه می شود. دستورات شکل شناسی به ما می گویند که کلمه fish حالت جمع ندارد و حالت جمع کلمه gosse با تغییر حروف صدادار آن تشکیل می شود یعنی geese.
مسئله تشخیص اینکه لغت foxes به دو قسمت fox و es شکسته می شود را تجزیه شکلی[77] نامند. تجزیه به معنای دریافت ورودی و تولید ساختارهایی برای آن است. می خواهیم از اصطلاح “تجزیه ” خیلی وسیعتر استفاده می کنیم، شامل انواع زیادی از ساختارهایی که ممکن است ایجادد شوند: ریخت شناسی، قواعد صرف و نحوی، قواعد معنایی و عملگرایانه.
در عمل تجزیه فقط بحث شکل حالت جمع و مفرد مطرح نیست. مثلاً برای لغاتی مثل talking، going و … می خواهیم آنها را به دو دسته شامل ریشه لغت بعلاوه ing تجزیه کنیم. بنابراین برای شکل ورودی going ممکن است بخواهیم فرم تجزیه شده ای به صورت VERB-go+GERUND-ING تولید کنیم. این بخش می خواهد آگاهی هایی مربوط به ریخت شناسی را که برای نمایش زبانهای مختلفی احتیاج می شود بررسی کند و اجزاء اصلی یک الگوریتم مهم برای تجزیه ریختی را معرفی کند، یعنی مبدل حالت محدود.
مسئله ای دیگر این است که چرا ما شکل جمع همه اسامی یا شکل ingدار همه افعال را در فرهنگ لغت لیست نمی کنیم؟ بدلیل اینکه مثلا ing یک پسوند است که به هر فعلی اضافه می شود به طور مشابه s به اغلب اسامی اضافه می شود. بنابراین ایده لیست کردن همه اسامی وافعال می تواند ناکارآمد باشد. بنابراین مطمئناً نمی توانیم همه اشکال مختلف هر لغتی را لیست کنیم.
3-5-2-3- تجزیه ریختی حالت محدود
اکنون اجازه دهید به بحث تجزیه ریختی بپردازیم. به یک مثال ساده توجه کنید:
تجزیه حالت جمع اسم و ingدار شدن فعل. هدف ما این خواهد بود که ورودی هایی مثل شکل بعد بدهیم و خروجی های لازم را تولید کنیم:
| خروجی | ورودی | ||
| Cat +N+PL
Cat+N+SG City+N+PL Goose+N+SG یا Goose+ V Goose+V+3SG Merge+V+Pres-Part Catch+V+Past-Part یا Catch+V+Past |
Cats
Cat Cities Geese Goooses Merging Caught |
||
جدول 3-5
ستون دوم شامل ریشه ای از هر لغت همراه با ویژگی های ریختی مناسب آن است. این ویژگی ها اطلاعات اضافه ای درباره ریشه لغت است. بعنوان مثال ویژگی +N به این معنی است، +SG یعنی مفرد، +PL یعنی جمع است.
به منظور ساخت یک تجزیه کننده ریختی ما به موارد زیر نیاز داریم:
لغت نامه[78]: لیستی از اصل لغات و پسوندها همواره با اطلاعاتی اساسی در مورد آنها (مثلا اینکه لغت اسم است یا فعل؟)
ریخت شناسی[79]: مدلی از ترتیب واژکها (کوچکترین واحد معنی دار) که کلاسهایی از واژکهایی که می توانند از کلاسهای دیگر پیروی کنند را شرح می دهد.
قواعد املائی[80] : این قواعد برای مدلسازی تغییراتی که در یک لغت اتفاق می افتد استفاده می شود. مثلا زمانی که دو واژک با هم ادغام می شوند (مثل City +s که به Cities تبدیل می شود نه به Cityss).
-
-
-
- لغت نامه و مدل واژکها :
-
-
لغت نامه انباری از لغات است ساده ترین لغت نامه می تواند شامل لیستی از هر لغتی از یک زبان به شکل زیر باشد. (هر لغتی، یعنی شامل اختصارات، نامها و اسامی اشخاص و …)
a
AAA
AA
Aachen
Aardwolf
Aba
Aback و…
از آنجایی ک خیلی اوقات محتوی لغت نامه اینگونه نیست، لغت نامه های محاسباتی معمولا بوسیله لیستی از مدلهای واژک که به ما می گویند چگونه به هم می چسبند، ساختاربندی شده اند. روشهای زیادی برای مدلسازی واژکها وجود دارد.یکی از رایج ترین آنها ماشینهای حالت محدود FSA برای اسمها در انگلیسی به شکل زیر است:
شکل 3-8
و یک مدل مشابه برای افراد در انگلیسی:
شکل 3-9
این لغت نامه سه کلاس ریشه دارد: ریشه فعل با قاعده، بی قاعده و حالت گذشته بعلاوه4 کلاس پسوند شامل : ed (فعل ماضی)، ed(صفت مفعولی)، ingو s برای فعل سوم شخص.
3-5-2-5 – تجزیه ریختی بوسیله مبدلات حالت محدود
اکنون که دیدیم چگونه از FSA برای نمایش لغت نامه و ضمنا انجام تشخیص شکل شناسی استفاده می شودف اجازه دهید به بحث تجزیه ریختی بپردازیم. بعنوان مثال، برای ورودی Cats دوست داریم تا خروجی به شکل Cat+N+PL شود تا به ما بگوید که Cats یک اسم جمع است. می خواهیم اینکار را بوسیله ریخت شناسی دو سطحی انجام دهیم که ابتدا کاسکونینی آنرا مطرح کرد.
ریخت شناسی دوسطحی یک لغت را بعنوان تناظر بین سطح واژه ای[81] که یک الحاق ساده از واژکهایی است که یک لغت را می سازند نشان می دهد و سطح ظاهری[82] که املای درست لغت نهایی است- را بیان می کند.
تجزیه ریختی بوسیله ساخت قواعد نگاشتی – که توالی از حروف (مانند Cats) را در سطح ظاهری به واژکها و توالی از ویژگی ها می نگارد- انجام می شود (مانند Cat+N+PL در سطح واژه ای)
شکل زیر دو سطح برای لغت Cats را نشان می دهد:
واژه ای:
| +PL | +N | t | a | C |
ظاهری :
| s | t | a | C |
نکته اینکه سطح واژه ای اصل و ریشه کلمه را دارد. مطابق اطلاعات ریخت شناسی، +N+PL به ما می گویند که Cats یک اسم جمع است.
اتوماتی که ما برای انجام تناظر بین این دو سطح استفاده می کنیم FST [83] یا مبدلات حالت محدود نام دارد. یک FST این کار را توسط اتومات محدود انجام می دهد. بنابراین معمولا ما یک FST را بعنوان اتوماتی دو نواره تصور می کنیم که زوج رشته هایی را تشخیص می دهد یا تولید می کند. بنابراینن FST کارکرد اصلی زیادی نسبت به FSA دارد. در جایی که FSA یک زبان رسمی را بوسیله تعریف یک مجموعه رشته ها تعریف می کند، FST ارتباط بین مجموعه رشته ها را مشخص می کند. این، چشم انداز دیگری از FST را بازگو می کند. بعنوان ماشینی که یک رشته را می خواند و نتایجی تولید می کند.
در اینجا خلاصه ای از چهار دسته موارد کاربرد مبدلات حالت محدود آورده شده است:
- FST بعنوان شناسنده: مبدل یک زوج رشته بعنوان ورودی می گیرد و پذیرش بعنوان خروجی می دهد اگر زوج رشته در زبان موجود باشد و عدم پذیرش می دهد اگر موجود نباشد
- FST بعنوان مولد: ماشینی که زوج رشته های زبان را در خروجی می دهد خروجی Yes یا No است بهمراه زوج رشته.
- FST بعنوان مترجم: ماشینی که یک رشته را می خواند و رشته ای دیگر را ترجمه شده می دهد.
- FST بعنوان مجموعه ای از بازگوگرها
FST می تواند رسما به چند روش تعریف شود ما روی تعریف زیر تاکید می کنیم که برپایه چیزی بنام Mealy Machine است و تعمیمی از یک FSA ساده است.
Q: مجموعه ای محدود از n حالت q0,q1,q2,q3, …,qn
∑ : الفبای محدود از علائم پیچیده است. هر علامت از یک جفت ورودی خروجی o:I تشکیل شده است.
q0 : حالت آغازین
F: مجموعه ای از حالت های پایانی که در آنجا رشته توسط ماشین پذیرش می شود.
: معرف انتقال بین حالتها به ازای ورودی – خروجی مشخص است.
جائیکه FSA زبانی که دارای الفبای محدودی است را پذیرش کند- مانند زبان گوسفندی
FST-∑={b,a,!} زبانی را پذیرش می کند که روی جفت علامتهاست:
∑={a:a,b:b,!:!,a:!,a,ε,ε:!}
-
-
-
- مدلسازی آماری زبان
-
-
مدلهای زبانی که به منظور بازشناسی گفتار و دیگر فناورهای زبانی بکار برده می شوند، برای اولین بار در سال 1980 مطرح شدند. از آن زمان تاکنون تلاشهای فراوانی برای اصلاح و توسعه این مدلها به جهت کاربرد در سیستم های پیشرفته امروزی صورت گرفته است. مدلهای آماری زبان توزیع احتمال واحدهای زبانی مختلف مانند آواها، کلمات و جملات یک متن را محاسبه می نمایند.
مدلسازی زبان تلاشی در جهت تسخیر قواعد زبان طبیعی به منظور بهبود کارآئی کاربردهای مختلف زبان طبیعی است مدلهای زبانی برای کاربردهای مختلفی از فن آوری زبان از جمله بازشناسی گفتار، ترجمه ماشینی، طبقه بندی متون، بازشناخت نوری کاراکترها، بازشناسی دست نوشته و تصحیح هجاها و … بکار گرفته شده اند.
مدلهای آماری زبان از روی دادگان متنی، پارامترهای بسیار زیادی را تخمین می زنند و بنابراین به حجم بالائی از دادگان تعلیم نیاز دارند. موفق ترین فن آوری SLM دانش بسیار محدودی را از آنچه که یک زبان براستی است، در نظر می گیرد. مشهورترین مدلهای زبانی (N گرم ها) واقعیتی را مدل می کنند ک زبان نیست، بلکه دنباله ای از نمادها است وهیچ ساختار عمیقی ندارد.
در ادامه برخی از فن آوریهای SLM مرور می شود:
تقریباً تمامی مدلهای آماری زبان احتمال یک جمله را به حاصل ضرب احتمال های شرطی تجزیه می نمایند. استفاده از مدلهای زبانی نه تنها در سطح کلمه، بلکه در سطح آوا نیز کاملاً رایج است. هاوس و نئوبرگ نشان دادند که محدودیت های موجود روی زنجیره آواها به عنوان روش موثری در شناسائی می تواند بکار گرفته شود. در کار انجام شده، نشان داده شد که این محدودیت ها به عنوان مشخصه قدرتمند در بازشناسی گفتار، حتی در مواردی که گفتار به بخش های متنوعی تعلق دارد، می تواند مورد استفاده قرار گیرد.
در هر مساله مدلسازی در ابتدا دو عامل اصلی می باید ابداع و تدوین شوند- ساختار مناسب و جامع برای مدل و سپس چگونگی تنظیم و محاسبه پارامترهای آن. براساس مطالعات و بررسی های انجام شده و با توجه به سوابق و کاربردهای متعدد، مدل پنهان مارکوف برای مدلسازی کلمات و مدلهای N_gram برای جملات در نظر گرفته شده اند. از آنجا که هر روش یادگیری نیاز به مجموعه ای از داده های آموزشی دارد لذا روشی کارآمد و جامع برای نمایش متن باید در نظر گرفته شود.
3-5-3- مدل مخفی مارکوف:
مدلهای مارکوف مخفی اولین بار در یک سری از مقالات آماری توسط لیونارد ای بوم[84] و نویسندگان دیگر در نیمه 1960مطرح گردید. اولین کاربرد آن در شناسایی گفتار بود که در نیمه 1970شروع گردید. درنیمه 1980برای آنالیز رشته های بیولوژیکی بخصوص DNA استفاده گردید. از آن زمان بعنوان زمینه ایی از بیوانفورماتیک درنظر گرفته شد.
آندری آندرویچ مارکوف٬ فارغ التحصیل دانشگاه سنت پترزبورگ در سال ۱۸۷۸ بود. وی در سال ۱۸۸۶ مدرک پروفسوری خود را دریافت کرد. کارهای زودهنگام مارکوف در تئوری اعداد٬ آنالیز٬ حدود انتگرال ها٬ همگرایی سری ها٬ دنباله کسرها و … بسیار اساسی بود
بعد از سال ۱۹۰۰ ٬ مارکوف تحت تأثیر استاد خود چبیشف٬ از روش دنباله های کسرها در تئوری احتمالات استفاده کرد.وی هم چنین در مورد رشته های متغیرهای وابسته متقابل٬ مطالعاتی انجام داد.با این امید ثابت کردن قوانین حدی در احتمالات در حالات کلی آنها. او قضیه حد مرکزی را با در نظر گرفتن فرض های کامل آن٬ اثبات کرد.
مارکوف به دلیل مطالعاتش پیرامون زنجیرهای مارکوف که رشته هایی از متغیرهای تصادفی هستند٬ معروف است.در زنجیرهای مارکوف٬ متغیر بعدی توسط متغیر کنونی مشخص می شود ولی از راهی که تا کنون طی شده است مستقل است.
مدلهای مخفی مارکوف ابتدا در سالهاي اواخر 1960 و اوايل 1970 معرفي و مورد مطالعه قرار گرفت. روشهاي آماري منبع مارکوف يا مدلسازي مارکوف پنهان بطور روزافزوني در سالهاي اخير متداول گرديد. براي اين امر دو دليل بسيار قوي وجود دارد.
اولاً مدلها در ساختمان رياضي خيلي غني هستند و در اينصورت ميتوانند مبنائي نظري براي استفاده در محدودهء وسيعي از کاربردها را تشکيل دهند. ثانيا” مدلها، در هنگامي که بطور صحيحي بکار برده ميشوند، در عمل براي کابردهاي مهم خيلي خوب کار ميکنند.
چرا مخفی؟
اطلاق کلمة مخفي, به موضوع مورد بحث ما به اين دليل است که در بارة مسائلي صحبت ميکنيم که طريقة انجام آنها از ديد ما پنهان است و البته ماهيت پارامتري آماري دارد. يعني اينکه نه تنها نميدانيم نتيجه چه خواهد بود, بلکه نوع اتفاق و احتمال آن اتفاق نيز بايد از پارامترهايي که در دسترس است, نتيجهگيري شود. مانند پرتاب سکه در يک جعبة در بسته, يا جايي دور از ديد ما. يعني مدل حاصل يک مدل تصادفي با يک فرآيند تصادفي زيرين است که از ديد ناظر, غير قابل مشاهده (مخفي) است و تنها توسط مجموعه اي از فرآيندهاي تصادفي که دنبالة مشاهدات را توليد مي کنند قابل استنتاج (به جاي مشاهده) است.
مثال : متوجه شدن وضع آب و هوا از طریق جلبک
انواع مدل
مدل مخفی مارکوف
مدل مخفی مارکوف یک سری متناهی از حالتهاست، که با یک توزیع احتمال پیوسته است
در یک حالت خاص، توسط توزیع احتمال پیوسته یک خروجی یا مشاهده می تواند بدست آید. حالات از خارج مخفی هستند از این رو مدل مخفی مارکوف نامیده شده است. مدل مخفی مارکوف، یک مدل آماری است که در آن پارامترهای مخفی را از پارامترهای مشاهده شده مشخص می نماید. پارامترهای بیرون کشیده شده برای آنالیزهای بعدی می توانند استفاده شوند.به عنوان مثال برای دستور العمل های بازشناسی الگو.
در مدل مارکوف معمولی، وضعیت به طور مستقیم توسط مشاهده گر قابل مشاهده است. بنابراین حالت انتقال احتمالات تنها پارامترها هستند. در مدل مخفی مارکوف، وضعیت به طور مستقیم قابل مشاهده نیست، اما متغییرهای تحت تاثیر با وضعیت قابل مشاهده هستند. هر حالت یک توزیع احتمالات دارد برای خروجی ممکن که گرفته شود. بنابراین ترتیب گرفته های ایجاد شده توسط HMM اطلاعاتی در رابطه با حالت توالی میدهد. مدل های مخفی مارکوف برای دستورالعمل در شناسایی الگوهای موقت مانند گفتار، دست خط، شناسایی ایما و اشاره، بیو انفورماتیک و… معروف هستند
پارامترهاي اصلي مدل مارکوف
- مجموعة حالتهايي که ممکن است اتفاق بيفتد.
- مجموعة تصميماتي که ميتوان در حالتهاي مختلف گرفت.
- مجموعة نتايجي که ممکن است متعاقب هر تصميمگيري بدست آيد.
- منافع و ارزش افزوده اين تصميمگيري در مقايسه با تصميمات ممکن ديگر
با گرفتن مناسبترين تصميم, بهترين راه حل براي مسئلة مطرح شده را تشخيص داده, و به بهترين حالت بعدي ممکن رسيد. اين راه حل, بصورت يک تابع ارزش نشان داده مي شود که در هر حالت (موجود), بهترين حالت بعدي (مطلوب) توسط آن تعيين ميشود.
معماری مدل مخفی مارکوف
شکل 3-10
هر شکل بیضی بیانگر یک مقدار متغیر تصادفی است که مقادیری را می پذیرد. x(t) مقدار متغیر تصادفی است که مقدار تغییرپذیرش در واحد زمان مخفی است. y(t) مقدار متغیر تصادفی است که مقدارش در زمان t قابل مشاهده است.
از دیاگرام مشخص است که مقدار x(t) به مقدار x(t − 1) وابسته است.که این را خاصیت مارکوف می نامند.
بطورمشابه، مقدار y(t) نیز به x(t) وابسته است.
فرآيند مارکوف
دياگرام زير، حالتهاي مخفي و قابل مشاهده مثال آب و هوا را نشان ميدهد. اين دياگرام اظهار ميدارد كه حالتهاي مخفي در آب و هواي صحيح توسط يك فرآيند ماركوف ساده دستور اول، مدل شدهاند و بنابراين آنها همه به همديگر متصل شدهاند.
شکل 3-12
 اتصال بين حالتهاي مخفي و قابل مشاهده، احتمال توليد يك حالت خاص قابل مشاهده را كه تحت تاثير فرآيند ماركوف در حالت مخفي ويژه بوده، نمايش ميدهد. بنابراين روشن است كه همه احتمالات كه توسط حالت قابل مشاهده وارد ميشوند با عدد 1 جمع ميشوند، از اين رو در مورد بالا، مجموع احتمال آفتابي و ابري و بارانی ميشود. بنابراين علاوه بر ماتريس احتمالات که فرآيند ماركوف را توصيف مي كنند، ما ماتريس ديگري داريم، مصطلح به ماتريس اغتشاش كه شامل احتمالات حالتهاي قابل مشاهده است كه حالتهاي مخفي ويژه در آن پنهان است. براي مثال آب و هوا، ماتريس اغتشاش اينگونه باشد:
اتصال بين حالتهاي مخفي و قابل مشاهده، احتمال توليد يك حالت خاص قابل مشاهده را كه تحت تاثير فرآيند ماركوف در حالت مخفي ويژه بوده، نمايش ميدهد. بنابراين روشن است كه همه احتمالات كه توسط حالت قابل مشاهده وارد ميشوند با عدد 1 جمع ميشوند، از اين رو در مورد بالا، مجموع احتمال آفتابي و ابري و بارانی ميشود. بنابراين علاوه بر ماتريس احتمالات که فرآيند ماركوف را توصيف مي كنند، ما ماتريس ديگري داريم، مصطلح به ماتريس اغتشاش كه شامل احتمالات حالتهاي قابل مشاهده است كه حالتهاي مخفي ويژه در آن پنهان است. براي مثال آب و هوا، ماتريس اغتشاش اينگونه باشد:
اجزای مدلهاي مخفي ماركوف
- بردار احتمال حالت اوليه
- ماتريس تغيير حالت
- ماتريس اغتشاش
هر احتمالي در ماتريس تغيير حالت و اغتشاش به زمان وابسته نمی باشد. براي همين، ماتريسها هنگامي كه سيستم درگير تغيير زمان ميشود، وابسته به زمان تغيير نميكنند. در عمل اين يكي از غير واقعي ترين فرضيات مدل ماركوف درباره فرآيند هاي واقعي است.
مرتبه مدل مارکوف
- مدل مارکوف مرتبه صفر
مدل مارکوف از مرتبه صفر مانند يک توزيع احتمال چند جمله اي مي باشد. چگونگي تخمين پارامترهاي مدل مارکوف مرتبه صفر و همچنين پيچيدگي مدل مشخص و قابل حل است و در کتابهاي آمار و احتمالات وجود دارد.
- مدل مارکوف مرتبه اول
احتمال يک وضعيت به احتمال وضعيت قبلي آن (از نظر زماني) بستگي دارد، به بيان ديگر احتمال وضعيتهاي ممکن، مستقل نيستند.
- مدل مارکوف مرتبه M
مرتبه يک مدل مارکوف برابر است با طول حافظه اي که مقادير احتمال ممکن براي حالت بعدي به کمک آن محاسبه مي شود. براي مثال، حالت بعدي در يک مدل مارکوف از درجه 2 (مدل مارکوف مرتبه دوم) به دو حالت قبلي آن بستگي دارد.
مثالی از یک پردازش مارکوفی
شکل 3-13
فرضيات تئوری مدل مخفی مارکوف
- فرض مارکوف
به بيان ديگر فرض می شود که حالت بعدی تنها به حالت فعلی بستگی دارد. مدل حاصل از فرض مارکوف يک مدل HMM مرتبه صفر می باشد. در حالت کلی، حالت بعدی می تواند با k حالت قبلی وابسته باشد.
- فرض ايستايی[87]
در اينجا فرض می شود که احتمال انتقال در بين حالات از زمان واقعی رخداد انتقال مستقل است.
- فرض استقلال خروجی
در اين حالت فرض می شود که خروجی (مشاهدات) فعلی به صورت آماری از خروجی قبلی مستقل است. مي توان اين فرض را با داشتن دنباله ای از خروجی ها مانند بيان نمود
براي اينکه مدل HMM در دنياي واقعي قابل استفاده باشد بايد سه مساله مهم حل شود :
- مساله ارزيابي
- مساله کدگشايي
- مساله یادگیری
انواع مدلهاي مخفي مارکوف و HMM پيوسته
- مدل ارگوديک
- مدل چپ به راست
- مدل موازي چپ به راست
شکل 3-14
الگوريتم ها
کاربردهای HMM
- طبقه بندی رشته ها با HMM
- تولید مسیرهای چندگانه
- شناسايي گفتار
- شناسايي کلمات جداگانه
- مدلسازی و یادگیری
- مدلسازی و ارزيابی عملكرد جراحی با استفاده از مدلهای مخفی ماركف
- نرم افزار تشخیص گفتار از روی حرکات لب
- زنجيرههاي مارکوف در برنامهريزي نيروي انساني و پيشبيني آن در شرکت ملي ذوبآهن
- ارزیابی قابلیت اطمینان منبع قدرت شبکه الکترونیکی جهت کاربردهای ایمنی
محدوديتهاي فرآيند ماركوف
در مدل مخفی مارکوف، فرآيند هايي وجود دارند كه رشته قابل مشاهده احتمالات به يك فرآيند ماركوف لايه زيرين مرتبط است. در چنين مواردي، تعداد حالتهاي قابل مشاهده ممكن است از تعداد حالتهاي مخفي متفاوت باشد.
يك مشكل واقعي ديگر، تشخيص گفتار است. صدايي كه ما ميشنويم، از طريق تارهاي صوتي، اندازه گلو، وضعيت قرار گرفتن زبان و خيلي موارد ديگر توليد ميگردد
هر كدام از اين فاكتورها، با تاثيرات متقابل روي هم صداي يك كلمه را ايجاد ميكنند و صداهايي كه يك سيستم تشخيص گفتار، نشان ميدهد، صداي تغيير يافته از تغييرات فيزيكي در صحبت كردن فرد ميباشد. بعضي دستگاههاي تشخيص گفتار، توليد گفتار داخلي را بعنوان رشته حالتهاي پنهان در نظر می گيرند و صداي منتج از اين سيستمها، يك رشته از حالات قابل مشاهده ميباشندكه بوسيله فرايند گفتار توليد شدهاند و در بهترين حالت صحيح (مخفي) قرار دارند.
جعبه ابزار مدل مخفی مارکوف در مطلب
این جعبه ابزار یک استنباط ویادگیری را برای HMM با خروجی های گسسته (dhmm’s)، خروجی های گوسین(ghmm’s)، یا مخلوطی از خروجی های گوسین(mhmm’s) پشتبانی میکند. همچنین ورودی های گسسته را پشتبانی می کند.
-
-
- مدل زبانی Nگرم[91]
-
ابتدا باید گفت که در هر شبیه سازی و حل مسئله، یک مدل سازی اولیه لازم است. این مدل سازی ممکن است ریاضی، فیزیکی، تجسمی و یا به هر گونه دیگر متناسب با ماهیت شبیه سازی یا حل مسئله باشد. برای مثال، وقتی شما می خواهید یک پدیده فیزیکی را شبیه سازی کنید و یا یک مسئله فیزیک را حل کنید، ابتدا سعی می کنید، شرایط را در غالب یک مدل ریاضی یا تجسمی، مجرد کنید. بدین معنی که اجزای بدون اهمیت آن را کنار بگذارید و یا تنها مهم ترین عوامل را در بررسی خود تأثیر دهید. بدین ترتیب، با تقریب بالایی توانسته اید نزدیک ترین جواب را پیدا کنید. بنابراین، قدرت مدل سازی شما آن جا معلوم می شود که در عین سادگی، جامع و شامل باشد.
در این جا، به یکی از پرکاربردترین مدل ها در زمینه شبیه سازی زبان انسان اشاره می کنیم. این مدل، بر خلاف اسم آن، نه تنها در مدل سازی زبان، بلکه در بسیاری از زمینه های هوش مصنوعی، مانند پردازش متن، پردازش سیگنال، تصویر و … راهکارهای مفیدی در اختیار می گذارد.
همان طور که می دانیم زبان طبیعی ، به زبانی می گویند که بین انسان ها رایج است و انسان ها می توانند از آن برای ارتباط با یکدیگر به صورت های نوشتن، حرف زدن، خواندن و … استفاده می شود. وقتی می گوییم مدل سازی زبان طبیعی، یعنی بیاییم و روابط و قواعد زبان را به طور هدفمند، ساده کنیم تا به ابزاری برسیم که بتوان از آن برای بررسی زبان و یا استفاده یا حتی تولید آن استفاده کرد. بسیاری از این مدل- ها، از یک پس زمینه ریاضی برخوردار هستند، مانند گراف، احتمالات و … . این هفته، یکی از این مدل ها را معرفی می کنیم و در مورد کاربردها و خصوصیات آن بحث می کنیم.
مدل Nگرم یکی از این مدل هاست. در این مدل، از آمار کلاسیک و احتمال بهره گرفته شده است. فرض کنید که یک سری اشیا یا نشانه ها و یا هر چیز دیگری داشته باشیم. هر کدام از این ها را به صورت یک رأس در گراف تصور کنید که می تواند به رأس دیگری یال جهت دار داشته باشد. این یال جهت دار، نشان دهنده یک نوع رابطه است که با توجه به مورد دلخواه ما می تواند معانی متفاوتی داشته باشد. مثلاً در مورد زبان، می- تواند توالی دو کلمه باشد (اگر کلمه ای بعد از کلمه دیگری بیاید، یک یال از اولی به دومی وجود دارد). به یک توالی n تایی از این رأس ها، n-gram می گوییم (توالی های 3gram، 2gram و … داریم). در این مدل، یک مجموعه داده های آماری بسیار بزرگ نیاز داریم که هر کدام مجموعه ای از این نشانه ها به همراه روابط بین آن ها است. برای مثال، در مورد یک زبان خاص، یک سری متن به آن زبان می باشد. حال، روابطی در این مدل تعریف می شود که می توان با استفاده از آن، درستی یک توالی خواص از این نشانه ها را بررسی کرد.
فرض کنید می خواهیم درستی عبارت a1→a2→a3→a4 را بررسی کنیم. در این مدل، احتمال درستی به صورت یک عدد تعیین می شود که هرچه داده های آماری ما بیشتر باشد، نتیجه مطلوب تر است. عبارت بالا را به اجزای زیر تقسیم می کنیم و تعداد تکرار هر کدام را در داده های آماری پیدا می کنیم.
a1→a2
a2→a3
a3→a4
a1→a2→a3
a2→a3→a4
a1→a2→a3→a4
حال احتمال هایgram3، 2gram و … به صورت زیر تعریف می شوند:
P2gram = P(a2|a1) P(a3|a2) … : 2Gram
P3gram = P(a3|a1a2) P(a4|a2a3) … : 3Gram
P4gram = P(a4|a1a2a3) : 4Gram
عبارت P(a3|a1a2) یعنی احتمال درستی آمدن a3 پس از توالی a1a2 که مقدار آن برابر عبارت زیر است:
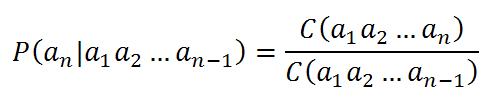
در عبارت بالا، تابع C یعنی تعداد تکرار توالی مورد نظر در داده های آماری.
در حالت کلی، احتمال درستی عبارت بالا در n-gram به صورت رابطه زیر است:
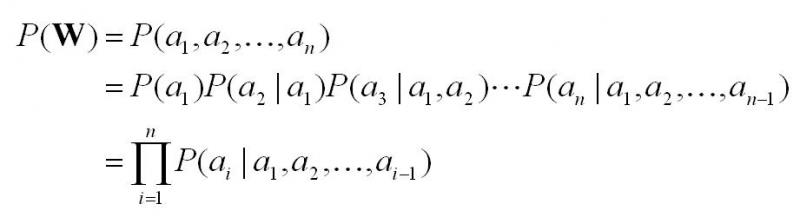
در این جا، تنها یک مشکل باقی می ماند و آن هم این است که اگر تنها یکی از این احتمال ها، صفر شود، احتمال کل صفر خواهد شد. در حالی که می دانیم، داده های آماری ما محدودیت دارند و ممکن است، بالاخره، یکی از توالی ها، مخصوصاً اگر تعداد آن زیاد باشد، در داده ها وجود نداشته باشد. راه حل این است که به هر کدام، یک مقدار ثابت (مثلاً 1) اضافه کنیم. روش های زیادی برای رفع این مشکل وجود دارند که در ههه آن ها، تابع احتمال به گونه ای تعریف می شود که مقدار صفر برنگرداند.
البته باید توجه داشت که این مدل، از مدل های آماری است. مدل های آماری این ویژگی را دارند که داده های آماری آن ها باید بسیار زیاد باشد تا نتیجه قابل قبولی به دست آید. در ضمن، شما می توانید ترکیبی از این مدل با مدل های دیگر را استفاده کنید و یا حتی روابط و شکل آن را متناسب با کارتان تغییر دهید.
آیندهی فناوریهای پردازش صحبت

شکل3-15
ارزش ایجاد فنآوریهای ترکیب و تشخیص صحبت بسیار زیاد است. صحبت سریعترین و کاراترین روش ارتباط انسانهاست. تشخیص صحبت پتانسیل جایگزینی نوشتن، تایپ، ورود صفحهکلید و کنترل الکترونیکی را که توسط کلیدها و دکمهها اعمال میشود را داراست و فقط نیاز به آن دارد که کمی برای پذیرش توسط بازار تجاری بهتر کار کند.
ترکیب صحبت علاوه بر آن که همانند تشخیص صحبت میتواند استفاده از کامپیوتر را برای کلیهی افراد ناتوان بدنی که دارای تواناییهای شنوایی و گفتاری مناسب هستند آسانتر سازد به عنوان یک وسیلهی خروجی کاربرپسند در محیطهای مختلف میتواند با جایگزین کردن بسیاری از علائم دیداری (انواع چراغها و…) و شنوایی (انواع زنگهای اخطار و …) با گفتارهای بیان کنندهی کامل پیامها استفاده از و رسیدگی به سیستمهای نیازمند این گونه پیامها را بهینه کند.
در اینجا لازم است به این نکته اشاره شود که پیشرفت در فنآوری تشخیص صحبت (و همچنین تشخیص گوینده) همان قدر که محدودهی دی.اس.پی را در بر میگیرد نیازمند دانش به دست آمده از محدودههای هوش مصنوعی و شبکههای عصبی است. شاید این تنوع دانشهای مورد نیاز به عنوان عامل دشواری مطالعهی مبحث پردازش صحبت در نظر گرفته شود حال آن که این گونه نیست و این تنوع راهکارها بخت رسیدن به سیستم با کارایی مطلوب را افزایش میدهد.
تواناییهای ابزارهایی که در بخش های قبل ارائه شد امیدواریهای فراوانی را در زمینهی موفقیت ابزارهای موجود فراهم میآورد و دامنهی وسیع شرکتها و مراکز دانشگاهی که در این زمینه فعالیت میکنند بر تنوع در قابلیتها و کاربردهای پیادهسازی شدهی این ابزارها میافزاید.
فصل چهارم – مدلسازی سیگنال
4-1- اهمیت مدلسازی سیگنال
تشخیص کامپیوتری صحبت در واقع بر دارندهی دو نوع عمل اصلی تشخیص است: تشخیص گفتار و تشخیص گوینده. با تحلیل یک موج صوتی میتوان خصیصههای اندامهای گفتاری گوینده را تخمین زد که این خصیصهها راهکاری برای تشخیص هویت و تصدیق آن به روش زیستسنجی فراهم میآورند. در مقابل، سیستمهای تشخیص گفتار برای درک مفهوم موج صوتی گفته شده تلاش میکنند. جهت بیشتر تحقیقات فعلی در فنآوری تشخیص صحبت به سمت ایجاد سیستمهای مستقل از گوینده است که توانایی تبدیل صحبت همهی گویندگان را داشته باشد. در حالی که اهداف این دو نوع سیستم کاملاً متفاوت به نظر میرسند هر دو عمیقاً از آبشخوری به نام الگوریتمهای پردازش سیگنال برای استخراج خصیصهها تغذیه میشوند. در هر دو زمینه تلاش برای پیدا کردن دستهای از خصیصهها که در مقابل تغییرات محیطی پایدار باشند ادامه دارد. این قسمت مروری خواهد داشت بر الگوریتمهای استخراج خصیصهها که در هر دو زمینه استفاده شدهاند و شامل ارزیابی کوتاهی از الگوریتمهای گوناگون مدلسازی سیگنال با آزمایشهای تشخیصی کوچک میباشد.
4-2- آشنایی با مدلسازی سیگنال
هدف سیستمهای تشخیص گفتار بازشناسی خصیصههای اندامهای گفتاری و حالت صحبت کردن با استفاده از صدای گوینده به منظور اهداف تشخیص هویتی میباشد. ساختار اندامهای صوتی، اندازهی چالهی بینی و ویژگیهای تارهای صوتی همگی با استفاده از تحلیل سیگنال قابل تخمین هستند. تشخیص گفتار اصطلاحی کلی است که به اعمال تشخیص هویت گوینده و تأیید هویت گوینده، تایید گفتار گوینده اطلاق میگردد. برای تشخیص، خصیصههای تخمینی گفتار با خصیصههای موجود در یک پایگاه دادهها از داده های ثبت شده برای یافتن نزدیکترین خصیصههای قابل تطبیق مقایسه میشوند.
شکل شماره 4-1 – وظایف مختلف
تشخیص صحبت تلاش دارد تا یک سیگنال صوتی صحبت را به واژهها تبدیل کند. انسانها واژهها را با حرکت دادن اندامهای صوتی به یک سری از مکانهای قابل پیش بینی ادا میکنند. اگر این دنبالهها از سیگنال استخراج گردند واژههای گفته شده میتوانند تشخیص داده شوند. بسیاری از کاربردهای تشخیص صحبت نیازمند سیستمهای مستقل از گوینده میباشند این تولیدات میتوانند صحبت هر گویندهای را تشخیص دهند.

شکل4-2
اگر چه این دو هدف کاملاً متفاوت به نظر میرسند هر دوی آنها بر روی دادههای صحبت تشخیص الگو را اعمال میکنند. بعضی از سیستمهای موجود مانند Nuance ۶ server هم تشخیص گفتار و هم تأیید هویت گوینده را به صورت همزمان اعمال میکنند. به خاطر همین شباهت رویه هر دوی این فنآوریها از یک نقطه ضربه میخورند: یک تنزل کارایی شدید در اثر تفاوتهای محیطهای آموزشی و آزمایشی به وجود میآید. به طور خلاصه کارایی این فنآوریها شدیداً به محیطی که در آن توسعه مییابند وابسته است و بنابراین حالات پر از نویز جهان واقعی آنها را به کارایی زیر کارایی بهینه راهبری میکند.
الگوریتمهایی مورد استفادهی محصولات پردازش کنندهی صحبت بر اساس مدل صوتی ناحیهی صوتی و کانال گوش استوارند. بخش بعدی اهمیت استخراج خصیصهها را با یک مرور کلی از تشخیص الگو روشن میکند و سپس با توصیف الگوریتمهای رایج در محصولات پراستفاده ادامه پیدا میکند.
4-3- تشخیص الگو
یک سیستم تشخیص الگو شامل دو جزء است: یک استخراج کنندهی خصیصهها و یک طبقهبندی کننده. ایدهآل آن است که وقتی دادهها به فضای دادههای خصیصهها انتقال پیدا کرد به سمت طبقهای کشیده شود که از همه به آن نزدیکتر است و از طرف طبقههای متفاوت دیگر بازپس زده شود. وقتی که به طبقهبندی کننده آموزش داده شد که بین طبقهها در این فضای انتقال داده شده از خصیصهها تمایز قائل شود یک سیستم تشخیص نیازمند آن است که تنها دادههای ورودی را از طریق همان سیستم استخراج خصیصهها انتقال دهد و مشخص کند که در کدام طبقه یک مشاهدهی جدید رخ میدهد.
دو مشکل مهم در اعمال این راهکار به پردازش صحبت وجود دارد. اولی آن است که هیچ التزامی وجود ندارد که محیط آموزش و محیط آزمایش قابل مقایسه باشند. استفاده از یک میکروفون متفاوت، نویز پسزمینه و کانالهای انتقال میتواند باعث کاهش کارایی جدی شود (یک معیار اساسی برای قضاوت در مورد یک مجموعه از خصیصهها پایداری آن در مقابل چنین تغییرات کانالی میباشد). دومین مشکل آن است که برهمنهی زیادی بین طبقههای موجود در فضای خصیصهها وجود دارد. ژائو نمودارهایی برای نشان دادن این برهمنهی در دو دسته دادههای صحبت جمعآوری کرده از طریق شبکهی تلفن ارائه میکند. موتورهای تشخیص صحبت برای غلبه بر این مشکل برهمنهی از پردازشهای آماری توانمند برای یکسانسازی مدل زبان استفاده میکنند که فراتر از حد این نوشتار است.
4-4- الگوریتمهای مدلسازی سیگنال
هدف مدلسازی سیگنال (که اغلب از آن با عنوان استخراج خصیصهها یاد میشود) انتقال دادههای صوتی به فضایی است که مشاهدات مربوط به یک طبقه با هم در یک گروه قرار گیرند و مشاهدات مربوط به طبقات متفاوت از هم جدا شوند. این انتقالها بر اساس مطالعات زیستشناختی سیستمهای صوتی و اندامهای گفتاری انسان انتخاب میشوند. برای مثال اندامهای گفتاری نمیتوانند از یک مکان به مکان دیگر در کمتر از حدود پنج میلیثانیه جابهجا شوند لذا سیستمهای عملی میتوانند از طیف ۱۰۰ بار در ثانیه نمونهبرداری کنند در حالی که از دقت عملیات فقط مقدار بسیار کمی کاسته شود.
صحبت یک سیگنال پویاست لذا ما علاقمند به آزمون طیف بازهی کوچک هستیم. زمان استمرار یک قاب به صورت طول زمانی که یک مجموعه از پارامترها معتبر هستند تعریف میشوند. با وجود این که قابها همپوشانی ندارند ما معمولاً از پنجرهی تحلیل دارای همپوشانی برای در نظر داشتن تعداد بیشتری از نمونههای سیگنال برای هر اندازهگیری طیف استفاده میکنیم. اعمال مستقیم تحلیل طیفی بر روی چنین مقدار کمی از دادهها معادل با اعمال یک پنجرهی مستطیلی تیز به سیگنال است که باعث ایجاد اعوجاج طیفی میشود. پاسخ فرکانسی پالس مستطیلی یک تابع sinc میباشد((sinc x=sin x/x که دارای یک باند عبور منحنی شکل و مقدار زیادی ناهمواری در باند توقف میباشد. شکلهای مختلف برای پنجرهها از طریق اعمال یک تابع وزن به دست میآیند. پنجرهی همینگ با رابطهی
w(n)= (a-(۱-a)cos(۲p/[N-۱])/ b
یک نمونهی ویژه از پنجرهی همینگ با۰.۵۴= a میباشد p (عدد پی)… ۳.۱۴۱۵ است. پارامتر b برای هنجارسازی به گونهای انتخاب میشود که انرژی سیگنال در خلال آزمایش بدون تغییر باقی بماند. شکل پنجرهی همینگ یک تحلیل طیفی با باند عبور هموارتر و باند توقف به طور قابل ملاحظهای بدون اعوجاج به دست میدهد که هر دوی این خصوصیات برای به دست آوردن تخمینهای پارامتری متغیر مهم هستند. بیشتر سیستمهای امروزی از یک فریم با اندازهی زمانی ۱۰ میلیثانیه و یک پنجره با اندازهی زمانی ۲۵ میلیثانیه استفاده می کنند.
یک خصیصهی استخراج شده از سیگنال انرژی مطلق سیگنال است. دستهی دیگر، اندازهگیری طیفی انرژی فرکانسهای خاص است. این اندازهها مشابه حالات اولیهی حرکات دستگاه صوتی انسان هستند (سلولهای مو در حلزون گوش برای دستیابی به هدف مشابهی استفاده میشوند). سه راه برای دستیابی به این اندازههای صوتی وجود دارد: اعمال مستقیم یک بانک فیلتر دیجیتال در دامنهی زمان، استفاده از تبدیل فوریه و تحلیل پیشگویانهی خطی. دو روش اخیر به لحاظ کارایی محاسباتی در سیستمهای امروزی رایجترند.
از آنجا که شنوایی انسان در طول یک اندازهی خطی به صورت مساوی حساس نیست، ما طیف را به یک اندازهی فرکانسی قابل درک نقش میکنیم. تجربیات در مورد ادراک انسان نشان دادهاند که فرکانسهایی با یک پهنای باند معینِ یک فرکانس اسمی که به پهنای باند بحرانی معروف است نمیتوانند به صورت جداگانه از هم تشخیص داده شوند. اندازهی مل یک تقریب سادهتر است که پیچ قابل مشاهدهی یک صدا را به اندازهی خطی نقش میکند. استیونز و فولکمن در سال ۱۹۴۰ به صورت تجربی نگاشتی بین اندازهی مل و فرکانسهای واقعی تعیین کردند. تفاوت اندازه به سختی به صورت خطی زیر ۱۰۰۰هرتز و به صورت لگاریتمی بالای ۱۰۰۰هرتز میباشد.
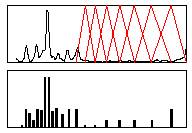
شکل شماره 4-3- بانکهای فیلتر با فضای مثلثی مل
بانکهای فیلتر مبتنی بر تبدیل فوریهی ساده که برای خصیصههای نهایی طراحی شدهاند دقت فرکانسی دلخواه را بر اساس مقیاس مل به دست میدهند. برای پیادهسازی این بانک فیلتر پنجرهی دادههای صحبت با استفاده از تبدیل فوریه به دامنهی فرکانس انتقال مییابد. در دامنهی فرکانس ضرایب دامنهی هر بانک فیلتر با اعمال یک ترکیب خطی از طیف و پاسخ فرکانسی فیلتر دلخواه پیدا میشوند. در عمل بانکهای فیلتر مثلثی دارای برهمنهی استفاده میشوند که در آن از فرکانس مرکزی یک فیلتر به عنوان نقاط انتهایی دو فیلتر مجاور استفاده میشود. بنابراین ضرایب دامنهی هر بانک فیلتر مقدار متوسط طیف در کانال فیلتر را نشان میدهند:
که در آن N(s) تعداد نمونههای استفاده شده برای دستیابی به مقدار متوسط و W(n) تابع وزنیابی (مشابه تابع مثلثی که قبلاً توضیح داده شد) میباشد و S(f) مقدار پاسخ فرکانسی است که با تبدیل فوریه محاسبه میشود.
تحلیل پیشگویانه خطی وسیلهای برای به دست آوردن پوشش طیفی هموار P(w) از یک مدل تمام- قطب طیف توان است. ضرایب خطی پیشگو همبستگی مستقیمی با نسبتهای ناحیهی لگاریتمی که پارامترهای هندسی مدل لولهای نقصان برای تولید صحبت هستند دارد. دامنههای بانک فیلتر با نمونهبرداری از مدل طیفی پیشگویانهی خطی در فرکانسهای بانک فیلتر مناسب به دست میآیند. این کار میتواند با ارزیابی مستقیم مدل ال.پی.سی انجام شود ولی در عمل تبدیل فوریه بر روی ضرایب پیشگو اعمال میشود. چون تعداد ضرایب ال.پی.سی کمتر از نمونههای صوت است این روش از لحاظ محاسباتی کاراست. ضرایب دامنهی بانک فیلتر همان گونه که از طیف حاصل از تبدیل فوریه به دست میآمدند از طیف حاصل از پیشگویانهی خطی به دست میآیند.
یک سیستم همریخت برای پردازش صحبت قابل استفاده است زیرا روشی برای جدا کردن سیگنال آشفتگی از شکل ناحیهی صوتی فراهم میآورد. یک فضای دارای این ویژگی سپستروم است که با محاسبهی عکس تبدیل فوریهی گسستهی لگاریتم انرژی به دست میآید. ضرایب سپسترال با محاسبهی دامنههای بانک فیلتر با استفاده از معادلهی زیر به دست میآیند:
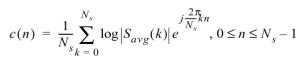
که S(avg) مقدار متوسط سیگنال در کانال kام فیلتر است. در عمل تبدیل کسینوسی گسسته به خاطر کارایی محاسباتی استفاده میشود. ضرایب سپسترال اغلب برای کمینه کردن تغییراتی که منجر به ایجاد اطلاعات نمیشوند وزنیابی میگردند که این پردازه لیفترینگ نامیده میشود. جالب است بدانیم که در ادبیات تشخیص صحبت خصیصههای مربوط به گوینده به عنوان تغییرات غیر دادهزا حذف میگردند ولی سیستمهای تشخیص گفتار نیز از لیفترینگ استفاده میکنند.
هر دو نوع سیستم تشخیص صحبت و تشخیص گفتار اطلاعات موضعی زمان کوتاه را با گرفتن مشتق خصوصیات اولیه نسبت به زمان به دست میدهند. به عنوان مثال یک صوت صدادار میتواند با پیدا شدن فرمانتهای آن در طیف تشخیص داده شود، حال آن که یک صوت بیصدا (سایشی) با استفاده از انتقال طیف مدل میشود. مقادیر مشتق مرتبهی اول خصائص ضرایب دلتا و مقادیر مشتق مرتبهی دوم آن شتاب یا ضرایب دلتا-دلتا نامیده میشوند. مشتق زمانی با استفاده از یک رابطهی رگرسیون که یک مجموعه فریم را پیش و پس از فریم کنونی میکشد تقریب زده میشود.
سیستمهای تشخیص گفتار از یک پیمانهی انتخاب خصیصه نیز در چارچوب تشخیص الگو استفاده میکنند. برای تشخیص صحبت تمامی سیگنال باید به یک نمایش متنی نگاشته شود حال آن که سیستم تشخیص گفتار نیازی به کار تحت این اجبار ندارد. بنابراین پیمانهی انتخاب خصیصه فقط خصیصهها مربوط به اصوات صدادار را ذخیره میکند. اصوات صدادار مستقیماً فرضیات مدلسازی پیشگویانهی خطی را برآورده میسازند و کمتر تحت تأثیر نویز صوتی قرار میگیرند.
فصل پنجم – روشهای طراحی سیستمهای تشخیص گفتار
5-1- مقدمه
همچنان که پیش از این گفته شد سیستمهای تشخیص گفتار در حالت کلی به دو نوع سیستمهای تأیید هویت گوینده و سیستمهای بازشناسی گفتار تقسیم میشوند. تفاوت این دو سیستم در نحوهی پذیرش ورودی است: در سیستمهای نوع اول گوینده با ارائهی یک شناسه ادعای هویت یک کاربر خاص را مینماید حال آن که در سیستمهای نوع دوم گوینده فقط گفتار خود را بیان میکند و سیستم او را از بین تمامی اطلاعات خود تشخیص میدهد.
در فصل قبل در مورد ساختار الگوهای مورد بحث صحبت کردیم و متوجه شدیم که عمل مدلسازی سیگنال یا استخراج خصیصهها با حذف ویژگیهای بدون استفادهی سیگنال صحبت و حفظ ویژگیهای قابل استفاده برای بازشناسی عبارات خاص الگوهایی را با ویژگیهای انتخاب شده در اختیار ما قرار میدهد.
ساختارهایی که برای هر دو نوع سیستم ارائه شد هر دو دارای یک مرحله برای تشخیص میزان شباهت الگوهای متعلق به گویندهی حاضر با گویندهی مورد ادعا (نوع اول) یا همهی گویندگان است که با استفاده از آن معیاری برای تصمیم گیری در اختیار ما قرار داده میشود.
همچنان که برای تشخیص الگو الگوریتمهای متعدد و روشهای گوناگون وجود دارد الگوریتمهای گوناگونی نیز برای یافتن میزان شباهت میان الگوها وجود دارد که انتخاب هر کدام از آنها بستگی به ساختار سیستم مقصد دارد.
انتخاب یک روش به ویژگیهای سیستم هدف بستگی دارد. بعضی از روشهای موجود تنها میتوانند فقط برای سیستمهای وابسته به متن یا فقط برای سیستمهای مستقل از متن مورد استفاده قرار گیرند و بعضی میتوانند برای هر دو نوع مورد استفاده قرار گیرند.
بحث این فصل که سه روش عمدهی یافتن میزان شباهت الگوها را به صورت کلی مورد بحث قرار خواهد داد عملاً پیشزمینههای نظری لازم برای طراحی سیستم هدف را کامل میکند.
5-2- روشهای مبتنی بر چشمپوشی زمانی پویا
این روش کلاسیک برای تشخیص خودکار گفتار در حالت وابسته به متن بر اساس یکسانسازی الگوها با استفاده از الگوهای طیفی یا روش طیفنگاره استوار است. در حالت کلی سیگنال صحبت به صورت یک دنباله از بردارهای خصیصه که رفتار سیگنال صحبت را برای یک گویندهی خاص مشخص میکند نمایش داده میشود. یک الگو میتواند نمایشگر یک عبارت چند کلمهای، یک کلمهی منفرد، یک هجا یا یک صدای ساده باشد.
در روشهای یکسانسازی الگوها مقایسهای بین الگوی عبارت ورودی و الگوی مرجع برای تشخیص هویت گوینده انجام میگیرد. یک جزء مهم در این روشها بهنجارسازی تغییرات زمانی هر آزمون تا آزمون بعدی میباشد. بهنجارسازی میتواند با روش چشمپوشی زمانی پویا صورت گیرد. این روش یک تابع بهینهی توسیع/ فشردهسازی زمانی را برای ایجاد صفبندی زمانی غیرخطی به کار میگیرد. شکل 5-1 الگوها را پیش و پس از اعمال این روش نشان میدهد. به این نکته توجه شود که چگونه چشمپوشی الگوهای نمونهی آزمون میزان نزدیکی دو الگو را افزایش داده است:
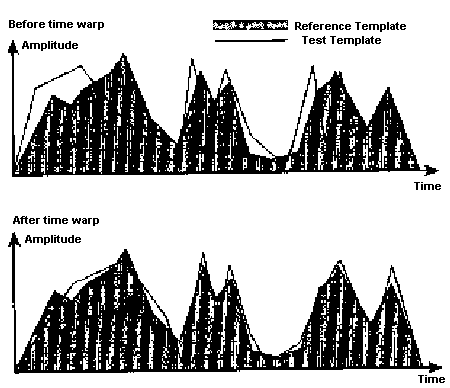
شکل شماره 5-1 – نمونهی یک الگو پیش و پس از اعمال روش چشمپوشی زمانی پویا
در شکل شمارهی 5-۱ فریمهای صحبت که الگوهای آزمون و مرجع را به وجود میآورند به صورت مقادیر دامنهای اسکالر بر روی نموداری که محور افقی آن نشانگر زمان است نشان داده شدهاند. بنابراین یک تابع تصمیمگیری با جمعآوری اندازهگیریها بر حسب زمان میتواند محاسبه شود. در عمل الگوها بردارهای چند بعدی هستند و فاصله بین آنها به صورت فاصلهی اقلیدسی مورد محاسبه قرار میگیرد. نوع دیگر فاصله که برای مقایسهی دو مجموعه از ضرایب پیشگویانهی خطی مورد استفاده قرار میگیرد فاصلهی ایتاکورا میباشد.
5-3- روشهای مبتنی بر مدلهای نهان مارکف
روشهای مبتنی برمدل نهان مارکف جایگزینهایی برای روش یکسانسازی الگوها که توسط روشهای چشمپوشی زمانی پویا ارائه شد میباشند که مدلهای احتمالی از سیگنال صحبت به وجود میآورند که ویژگیهای متغیر با زمان آن را توصیف میکند. یک مدل نهان مارکف یک فرایند اتفاقی دوگانه برای ایجاد یک دنباله از نشانههای مشاهده شده است. معنای دوگانه بودن این فرایند اتفاقی آن است که این فرایند دارای یک زیرفرایند اتفاقی دیگر است که قابل مشاهده نمیباشد (از اینجا مفهوم عبارت نهان مشخص میگردد) ولی میتواند توسط فرایند اتفاقی دیگری که یک دنباله از مشاهدات را ایجاد میکند مشاهده گردد. در سیستمهای تشخیص صحبت یا تشخیص گفتار دنبالهی موقتی طیف صوتی میتواند به صورت یک زنجیرهی مارکف مدلسازی شود تا روشی را که یک صدا به صدای دیگری تبدیل میشود توصیف کند. این عمل سیستم را تا اندازهی یک مدل که قادر است فقط در یکی از یک تعداد متناهی از حالات متفاوت باشد (به عنوان نمونه یک ماشین حالت متناهی کوچک میکند. روشهای مبتنی بر مدل نهان مارکف میتوانند هم در سیستمهای وابسته به متن و هم در سیستمهای مستقل از متن مورد استفاده قرار گیرند.
وقتی که بعد از یک انتقال حالت وارد یک حالت دیگر در ماشین حالت متناهی میشویم یک نشانه از مجموعه نشانههای آن حالت به عنوان خروجی برگزیده میشود. خروجی میتواند یک تعداد متناهی (روش مدل نهان مارکف گسسته) و یا یک مقدار پیوسته از خروجیها (روش توزیع پیوسته) باشد. هر دو مدل به صورت مؤثر اطلاعات موقتی را مدلسازی میکنند. سیستم در بازههای منظم زمانی تغییر حالت میدهد. حالتی که مدل در هر آغاز هر بازهی زمانی به آن میرود به احتمالات بستگی دارد.
تعدادی توپولوژی مدل که برای نمایش ماشین حالت متناهی استفاده میشوند وجود دارند. یک ساختار معمول ساختار چپ به راست است که به آن مدل بکیس هم گفته میشود و مثال آن نمونهای است که در شکل ۲ نشان داده شده است. هر حالت یک انتقال توقف، یک انتقال پیشرونده و یک انتقال جهشی دارد. با وجود آن که دز شکل نشان داده نشده است احتمالهای مختلفی به انتقالهای حالت متناهی وابستهاند و همچنین خروجی هر حالت را کنترل میکنند. نوع دیگر توپولوژی مدل نهان مارکف که در اینجا نشان داده نشده ساختار ارگودیک میباشد که در آن همانند یک شبکهی کاملاُ متصل به هم هر حالت به همهی دیگر حالات دارای انتقال است.
شکل شماره 5-2- مثالی از ساختار مدل نهان مارکف چپ به راست
5-4- روشهای مبتنی بر مقدارگزینی برداری
یک مجموعه از بردارهای خصیصهی بازهی کوتاه زمانی یک گوینده که برای آموزش سیستم به سیستم داده میشوند میتوانند مستقیماً برای نمایش ویژگیهای مهم عبارت ایراد شده توسط وی به کار گرفته شوند. در هر صورت نتیجهی کار آن است که نیازمندیهای حافظه برای ذخیرهی دادهها و پیچیدگی محاسباتی به سرعت با افزایش تعداد بردارهای آموزش دهندهی سیستم افزایش مییابد. بنابراین یک نمایش مستقیم عملی نخواهد بود.
مقدارگزینی برداری اساساً روشی برای فشردهسازی دادههای آموزش دهندهی سیستم تا اندازهای قابل مدیریت و کارا میباشد. با استفاده از یک دفتر کد مقدارگزینی برداری که شامل تعداد کمی بردارهای خصیصه با نمایانگری بالاست میتوان دادههای اولیه را به مجموعهی کوچکی از نقاط نمایانگر کاهش داد. مقدارگزینی برداری هم در سیستمهای وابسته به متن و هم در سیستمهای مستقل از متن قابل استفاده است.
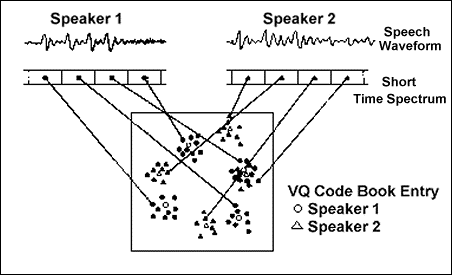
شکل شماره 5-3 – نمودار مفهومی که شکل گیری یک دفتر کد مقدارگزینی برداری را به تصویر میکشد
شکل 5-۳ یک نمودار مفهومی را که مثالی از شکل گیری یک دفتر کد مقدارگزینی برداری را به تصویر میکشد نشان میدهد. یک گوینده میتواند بر اساس مکان مرکز ثقل بردارها از دیگری تشخیص داده شود. در شکل5- ۳ خصیصههای طیفی زمان کوتاه با یک فضای اقلیدسی دوبعدی نشان داده شدهاند. برای ایجاد یک مجموعه از نقاط گامهای زیر اجرا شدهاند:
– از دو گوینده خواسته شده تا چند دنباله عبارت برای آموزش سیستم بیان کنند.
– دنبالههای آموزش دهندهی سیستم تحلیل میشوند و برای آموزش دفتر کد مقدارگزینی برداری استفاده میگردند.
– سپس نقاط به بخشهای جداگانه افراز میگردند و دو دفتر کد تولید میگردد که هر کدام چهار عنصر دارند. عناصر دفتر کد مقدارگزینی برداری به صورت دایره و مثلث نمایش داده میشوند و مرکز ثقل بخشهای مرتبط با فضای خصیصهی هر گوینده را نشان می دهند.
همچنان که در شکل5- ۳ قابل مشاهده است با وجود کمی رویهمافتادگی دو دفتر کد هنوز کاملاُ مجزا هستند و بنابراین هر گوینده میتواند از دیگری تشخیص داده شود. هدف آموزش یک دفتر کد مقدارگزینی برداری یافتن افرازهای مناسب از یک فضای برداری به صورت تعدادی ناحیهی بدون رویهمافتادگی میباشد. هر افراز با یک بردار مرکز ثقل مرتبط نشان داده میشود. روشی معمول برای یافتن یک افرازبندی مناسب استفاده از یک رویهی بهینهسازی مانند الگوریتم تعمیمیافتهی لوید که آشفتگی متوسط در بین بردارهای آموزش سیستم و مرکز ثقلها را کمینه میکند میباشد. سایر روشها عبارتند از معیار کمترین بیشینه (کمینه کردن بیشترین آشفتگی) که الگوریتم پوشش نیز نامیده میشود و استفاده از قانون Kامین همسایهی نزدیک به جای قانون نزدیکترین همسایه در محاسبهی آشفتگی.
5-5- مقایسهی کارایی
آزمایشهای گوناگونی برای تعیین این که کدام روش برای تشخیص گفتار بهترین روش است صورت گرفته است و مهم است که به این نکته توجه شود که چگونه محققان مختلف در وضعیتهای گوناگون به نتایج متفاوتی دست پیدا نمودهاند. به عنوان نمونه اروین در نوشتار خود در ارتباط با آزمایشهایی که وی در زمینهی سیستمهای وابسته به متن برای مقایسهی سه روش برشمرده شده انجام داده است به این نتیجه رسیده است که روش مقدارگزینی برداری بهترین کارایی را ارائه میکند. حال آن که یو، میسن و اگلبی در مقالهی خود اشاره به اجرای آزمایشهایی مشابه نمودهاند که نتایج متفاوتی را احراز نمودهاند. نتیجهی تجربهی آنان که در بردارندهی آزمایشهایی برای سه روش توضیح داده شده برای سیستمهای وابسته به متن و دو روش متأخر برای سیستمهای مستقل از متن است نمودار شکل ۴ برای سیستمهای مستقل از متن و شکل ۵ برای سیستمهای مستقل از متن است. همچنان که در شکل ۴ مشاهده میشود بر اساس تجربیات این گروه روش چشمپوشی زمانی پویا دارای بهترین کارایی است و همچنین روشهای مدل نهان مارکف با چگالی پیوسته و مقدارگزینی برداری هشتعنصری استفاده شده به ازای تعداد بردارهای آموزش سیستم متفاوت کاراییهای متفاوت دارند:
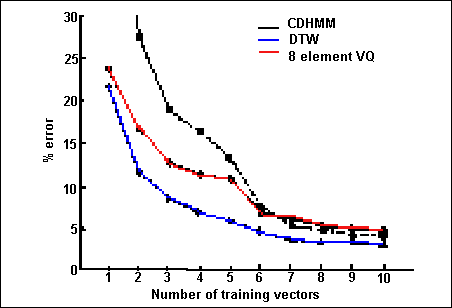
شکل شماره 5-4 – درصد خطا بر اساس تعداد بردارهای آموزش سیستم برای روشهای وابسته به متن چشمپوشی زمانی پویا، مقدارگزینی برداری ۸ عنصری و مدل نهان مارکف با چگالی پیوستهی ۸ حالتهی ۱ ترکیبه
همچنین از روی نمودار میتوان نتیجه گرفت که با وجود آن که برای تعداد بردارهای آموزش کم روش چشمپوشی زمانی پویا عملکرد بهتری دارد با افزایش تعداد بردارها این تفاوت عملکرد دیگر به صورت واضح مشاهده نمیشود.
شکل شمارهی 5-5 نتیجهی تجربیات این گروه را برای سیستمهای مستقل از متن نشان میدهد:
از این شکل این گونه بر میآید که روش مدل نهان مارکف با چگالی پیوسته نیازمند تعداد بردارهای آموزش سیستم بیشتری میباشد.
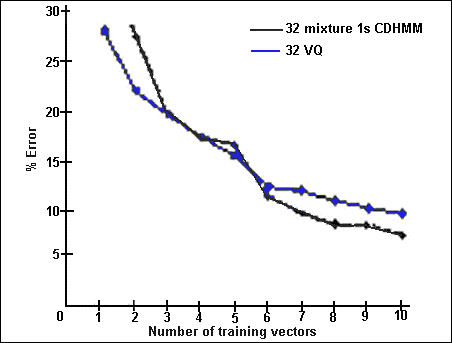
شکل شماره 5-5- درصد خطا بر اساس تعداد بردارهای آموزش سیستم برای روشهای مستقل از متن مقدارگزینی برداری ۳۲ عنصری و مدل نهان مارکف با چگالی پیوستهی تک حالتهی ۳۲ ترکیبه
ماتسوی و فروی نیز سیستمهای مستقل از متن پیادهسازی شده با دو روش متأخر را مقایسه نمودند و اشاره نمودهاند که روش مدل نهان مارکف ارگودیک پیوسته در مقابل تغییرات عبارت پایداری همسانی با روش مقدارگزینی برداری دارد و عملکرد بسیار بهتری نسبت به روش مدل نهان مارکف ارگودیک گسسته دارد. آنها همچنین به نتیجهای مشابه با گروه قبلی دست یافتهاند و آن این است که سیستمهای مبتنی بر روش مقدارگزینی برداری برای مقادیر کم داده پایدارتر از سیستمهای مبتنی بر روش مدل نهان مارکف پیوسته میباشند. شکل ۶ نتیجهی تجربیات آنان را به تصویر میکشد:
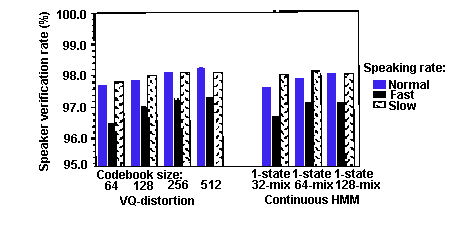
شکل شماره 5-6– مقایسهی سیستمهای مستقل از متن (ماتسوی و فوروی ۱۹۹۲
فصل ششم: نحوهی استفاده از برنامهی Speech Recognition
شکل6-1
برنامهی Speech Recognitionبا اولین اجرای آن جعبهی گفتگویی مانند شکل زیر در صفحه ظاهر خواهد شد:
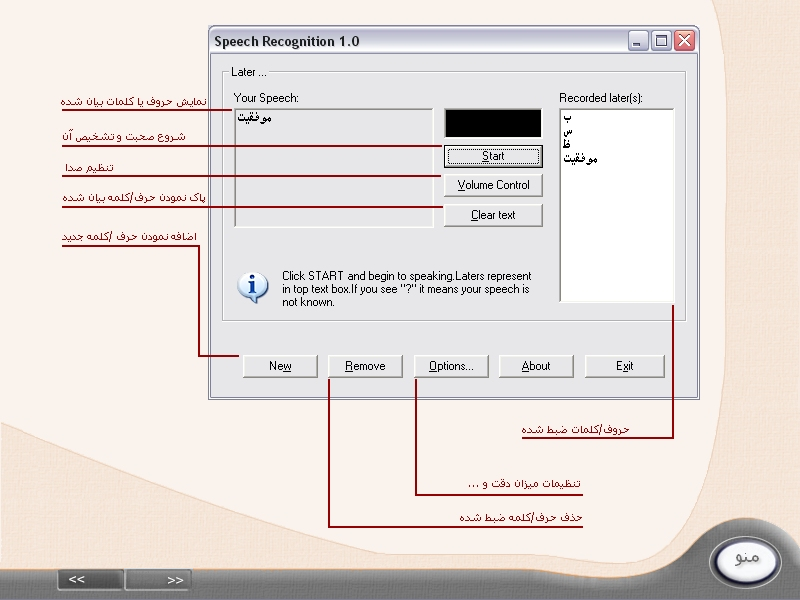
شکل شماره 6-2 – جعبهی گفتگوی آغازین برنامهی ثبت گفتار
با کلیک بر روی دکمهی New میتوان کلمه جدیدی را وارد نمود همچنان که در متن توضیح داده شده است به نظر میرسد تن صدای افراد در ساعات مختلف روز متفاوت است. در قسمت Accuracy Level میتوان میزان سختگیری سیستم را تغییر داد. ممکن است در شرایط متفاوت (میکروفن و شرایط محیطی مختلف) نیاز به چنین تغییری پیدا شود. در محیط آزمایشی ما میزان تعیین شده برای Medium مناسب به نظر میرسید.
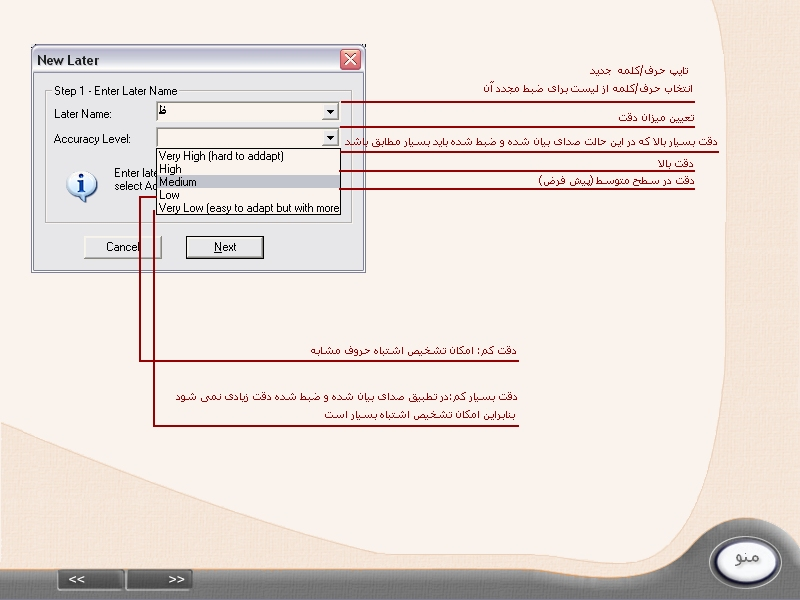
شکل شماره 6-3- ضبط یک عبارت جدید
یک دکمه نیز برای انتخاب ورودی و تنظیم صدای میکروفن گذاشته شده است:
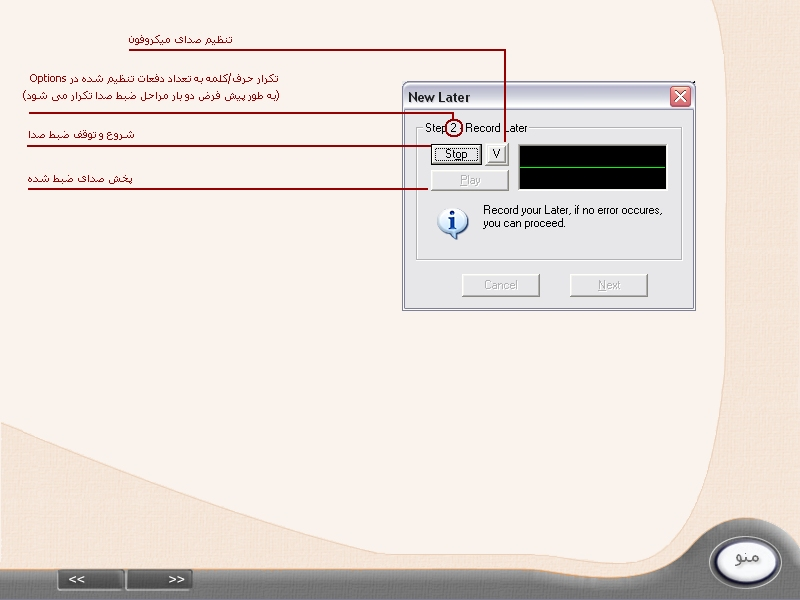
شکل شماره 6-4- ضبط کلمه جدید و تنظیم میکروفن
در صورتی که طول عبارت از مقداری که در انتخابهای برنامه انتخاب شده کمتر نباشد با فعال شدن دکمهی Next میتوانید به مرحلهی بعد بروید. در مرحله یا مراحل بعد (که تعداد آنها توسط کاربر قابل انتخاب است) از کاربر خواسته میشود تا عبارت خود را تکرار کند. در صورت تطابق عبارت با اولین عبارت میتوانید مراحل بعد را که مشابه مرحلهی اول است پشت سر بگذارید و متن تشخیص داده شده نشان داده می شود
– پس از طی مراحل توضیح داده شده کلمه مورد نظر ثبت میشود. (شکل شماره 1پنجره سمت راست)
با کلیک بر روی دکمهی OK کلمه مزبور در فایل پایگاهدادههای کلمات ذخیره میگردد.
در صورت تشخیص کلمه برنامهی یاد شده همان کلمه را نشان خواهد داد و از برنامه خارج خواهد شد و گرنه لازم است بار دیگر عبارت مورد نظر گفته شود.
– برای حذف یک کلمه کافی است در برنامهی Speech Recognition آن کلمه از پایگاه داده انتخاب نموده بر روی دکمهی Remove کلیک کنید.
۵- برنامهی Speech Recognition به وسیلهی دکمهی Options امکان تغییر بعضی پیشفرضهای سیستم را در اختیار میگذارد که این تغییرات در فایل پایگاهدادههای سیستم ذخیره میشوند و با حذف آن فایل از دست خواهند رفت:
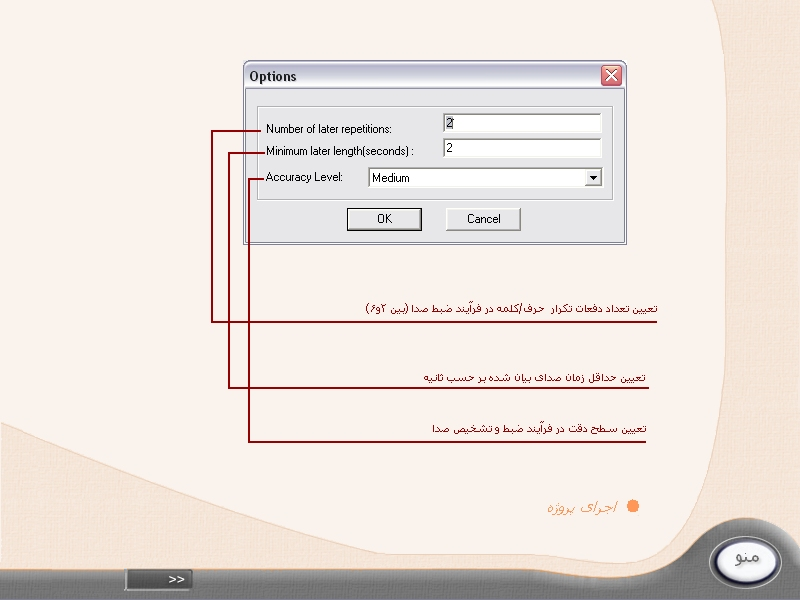
شکل شماره 6-5 – تغییر پیشفرضهای سیستم
همچنان که در شکل نشان داده شده میتوان تعداد تکرارهای لازم برای پذیرش عبارت را تعیین نمود. حداقل این تعداد دو بار میباشد (یکی برای اولین بار و یکی تکرار آن). حداقل طول عبارت نیز قابل تغییر است. در مستندات مختلف مربوط به سیستمهای تشخیص گوینده اشاره شده است که هر چه طول عبارت بیشتر باشد میزان خطای سیستم کاهش مییابد. همچنان که قبلاً نیز اشاره شد اگر طول عبارت گفته شده از حداقل تعیین شده کمتر باشد سیستم آن را نمیپذیرد. عبارات قبلاً ثبتشده که ممکن است طولشان کمتر از میزان تعیین شدهی جدید باشد باز هم مجاز خواهند بود و آنها را باید به صورت دستی حذف نمود. در قسمت آخر میتوان میزان سختگیری سیستم را تغییر داد. ممکن است در شرایط متفاوت (میکروفن و شرایط محیطی مختلف) نیاز به چنین تغییری پیدا شود. در محیط آزمایشی ما میزان تعیین شده برای Medium مناسب به نظر میرسید.
نتیجه گیری
استفاده از گفتار به عنوان درونداد اطلاعاتی علاوه بر سرعت،در نحوه تعامل انسان بر محیط تاثیر بسزایی داشته است. با وجودیکه در حال حاضر سیستم های زیادی برای تشخیص گفتار وجود دارد ولی همه این دستاوردها به گونه ای، دسته ای از محدودیت های ساده کننده را یدک می کشند که حذف این محدودیت ها می تواند به صورت قابل ملاحظه ای بر پیچیدگی این سیستم ها بیفزاید. هدف نهایی درسیستم های ”تشخیص گفتار“ ایجاد سیستمهایی است که بتوانند مانند انسان بشنوند و عکس العمل مناسب نشان دهند(سیستم های مستقل از گوینده وگفتار پیوسته). تا کنون گروهها و حوزه های مختلف فراخور نیازهایشان در انجام فعالیت هایشان از این فناروی استفاده کرده اند. حتی زمانی در آینده دور ممکن است تشخیص گفتار (Speech Recognition) تبدیل به در ک گفتار (Speech Understanding) شود. مدل های آماری که به سیستم ها اجازه می دهند در مورد گفتار یک فرد تصمیم گیری کنند، روزی به آن ها اجازه خواهند داد معنی نهفته در پشت کلمات را نیز درک کنند، اگر چه قطعاً تنها مدل کاملاً موفق از سیستم تشخیص گفتار سیستم شنوایی انسان است که هنوز اسرار آمیز و ناشناخته جلوه می کند.
ضمیمه1:
به خاطر اینکه پردازش سیگنال در تشخیص گفتار از اهمیت ویژه ای برخوردار است لذا در این پیوست در مورد سیگنال و مفاهیم مربوط به آن را بررسی می کنیم.
سیگنال چیست؟

به طور ساده هر کیمیت متغیر در زمان یا مکان که قابل اندازه گیری باشد را سیگنال می گوییم. به عنوان مثال سرعت کمیتی است
که در واحد زمان متغیر بوده و مقدار آن قابل اندازه گیری است. چراکه در بازه های زمانی مشخص می توانید مقدار سرعت را اندازه گیری کرده و ثبت کنید. مجموعه اعدادی که از ثبت سرعت در بازه های زمانی مختلف به وجود می آیند، باهمدیگر تشکیل یک سیگنال می دهند.
سیگنال گسسته
سیگنال پیوسته
کمیت هایی همچون شتاب، دما، رطوبت و… نیز در واحد زمان متغیر بوده و همچنین قابل اندازه گیری هستند. بنابراین با نمونه گیری از این کمیت ها در واحد های زمانی مختلف می توان تشکیل یک سیگنال داد. پردازش سیگنال نیز علمی است که به آنالیز سیگنال ها می پردازد. به علت کاربرد گسترده و همچنین قابل لمس بودن سیگنال های صوتی برای خوانندگان، در ادامه مقالاتی که برای پردازش سیگنال قرار داده ایم، تمرکز خود را بر روی سیگنال های صوتی و گفتار متمرکز کرده ایم. شکل زیر سیگنال صوتی را نشان می دهد که هنگام فشار دادن کلید 1 بر روی تلفن تولید می شود:
شکل 1 سیگنال را به شکل گسسته و شکل 2 سیگنال را به صورت پیوسته نشان می دهند. محور افقی زمان و محور عمودی نیز مقدار شدت سیگنال را نمایش می دهند.
همگام با ورود این سیگنال دیجیتالی به کارت صوتی خروجی آنالوگ (سیگنال پیوسته) در آن تولید می شود که این خروجی نیز وارد سیستم پخش صدا شده و موج تولید شده توسط بلندگو پس از پخش در فضا توسط گوش ما حس می گردد. این کل فرآیندی است که یک سیگنال صوتی دیجیتالی طی می کند تا توسط گوش ما شنیده شود. عکس این فرآیند نیز امکان پذیر است، بدین صورت که همگام با صحبت کردن ما در یک میکروفون، سیگنال آنالوگ تولید شده توسط آن وارد کارت صوتی شده و توسط کارت صوتی نمونه برداری می گردد وهمین نمونه برداری است که موجب تولید یک سیگنال زمانی در سمت کامپیوتر می گردد.
حال فرض کنید می خواهیم نویزی را که در یک فایل صوتی وجود دارد، یا نویزی که هنگام صحبت کردن ما در میکروفون ممکن است تحت تاثیر محیط اطراف به وجود آید را حذف کنیم. برای این منظور نیاز داریم که سیگنال دیجیتالی موجود بر روی سیستم کامپیوتری را پردازش کرده و پس از شناسایی نویز ها با استفاده از روشی به حذف آن ها پبردازیم. یا فرض کنید قصد داریم نرم افزاری را طراحی کنیم که این نرم افزار کلمات بیان شده در میکروفون را تایپ کند. پردازش گفتار علمی است که با بهره گرفتن از روش های پردازش سیگنال به انجام این عمل می پردازد. در ادامه این بخش سعی کرده ایم مفاهیم کلی پردازش سیگنال را مورد بررسی قرار دهیم. توجه داشته باشید که تمام روش های پردازش سیگنال های دیجیتالی برای آنالیز گفتار نیز به کار می روند.
نمونه برداری و چندی کردن سیگنال
فرض کنید میکروفورنی را به کارت صوتی وصل کرده اید و در حال ضبط صدا هستید. خروجی میکروفون یک خروجی آنالوگ می باشد و بنابراین نمی تواند به طور مستقیم وارد سیستم کامپیوتری گردد. چرا که همه سیستم های دیجیتالی اعم از یک کامپیوتر تنها با ورودی های دیجیتال می تواند کار کنند. بنابراین سیگنال آنالوگ تولید شده در خروجی میکروفون قبل از ورود به سیستم کامپیوتری باید به سیگنال دیجیتال تبدیل گردد. دیجیتال کردن سیگنال بر روی سیستم های کامپیوتری امروزی توسط کارت های صوتی انجام می پذیرد. یک سیگنال آنالوگ از لحظه ورود تا دیجیتال شدن مراحل زیر را به ترتیب طی می کند:
• آماده کردن سیگنال ورودی
• فیلتر کردن سیگنال ورودی
• نمونه برداری
• چندی کردن
شماتیک زیر نیز فرآیند تبدیل سیگنال آنالوگ به دیجیتال را نشان می دهد:

آماده کردن سیگنال ورودی :
فرض کنید خروجی سنسوری که موجب تولید سیگنال می شود، ولتاژ باشد. به عنوان مثال زمانی که در میکروفون صحبت می کنید، متناظر با صدای تولید شده توسط شما، خروجی میکرفون نیز در یک بازه مشخص به شکل ولتاژ تغییر می کند. یا به عنوان مثال خروجی سنسوری که برای ضبط نوار قلبی بکار می رود، در بازه های بسیار کوچک ولتاژ (میلی ولت) در حال تغییر است.
در مراحل بعدی عمل دیجیتال کردن زمانی که از مبدل آنالوگ به دیجیتال استفاده می کنیم، عملا نیاز به ولتاژهایی در بازه (5..0)، (5-..5) یا … ولت نیاز داریم. اما همانطور که دیدیم خروجی برخی از سنسورها (همانند سنسور نوار قلبی) در حد میلی ولت است. بنابراین نیاز به روشی داریم که بتوانیم خروجی سنسورها را تقویت کرده و آن ها را برای ورود به مبدل های آنالوگ به دیجیتال آماده کنیم.
این مرحله از عمل دیجیتال کردن ورودی را آماده سازی سیگنال ورودی می گوییم که در آن از تقویت کننده ها (آمپلی فایر) برای افزایش/ کاهش بهره ولتاژ استفاده می کنیم. لازم به ذکر است که امروزه سیستم تقویت کننده سیگنال به شکل توکار بر روی کارت های صوتی وجود دارد و در کارهای معمول خود نیاز به نصب تقویت کننده خارجی به کارت صوتی نداریم.در سیستم عامل ویندوز ضریب بهره آمپلی فایر کارت صوتی توسط Volume Controller خود سیستم عامل تعیین می شود.
فیلتر کردن سیگنال
خطوط تلفن دیجیتال قابلیت حمل سیگنال هایی در بازه 0 تا 3400 هرتز را دارند. از اینرو سیگنال هایی که فرکانسی خارج از این محدوده دارند، باید قبل از دیجیتال شدن فیلتر شوند. این عمل نیز با طراحی فیلترهایی امکان پذیر است. در واقع پس از آنکه سیگنال ورودی آماده شد (تقویت گردید) وارد سیتم فیلترینگ می گردد تا سیگنال های خارج از محدوده فرکانسی آن کاربرد، از سیستم حذف گردند.
طراحی فیلترها
از اهمیت ویژه ای برخوردار است چراکه اگر سیگنال به شکل صحیح فیلتر نشود، دچار اختلال هایی خواهد شد. با توجه به اینکه طراحی فیلترهای آنالوگ خارج از حیطه تخصصی ما می باشد، بنابراین از ذکر مطالب در مورد آن ها خودداری می کنیم. با این حال زمانی که نحوه طراحی فیلترهای دیجیتال را شرح می دهیم، پارمترهایی را که برای طراحی یک فیلتر مناسب باید در نظر گرفت، نشان خواهیم داد.
نمونه برداری کردن
پس از آنکه سیگنال ورودی آماده شد و فیلترکردن آن نیز انجام پذیرفت، دیجیتال کردن سیگنال آنالوگ آغاز می شود. نمونه برداری بدین مفهوم است که در بازه های زمانی مشخص مقدار سیگنال ورودی را خوانده و برای چندی شدن به مرحله بعد انتقال دهیم. به عنوان مثال زمانی که می خواهیم در هر ثانیه 44000 نمونه از سیگنال ورودی برداریم، باید در بازه های زمانی 0.00002 ثانیه مقدار سیگنال آنالوگ را خوانده و به مرحله بعد منتقل کنیم. به عنوان مثال زمانی که در میکروفون صحبت می کنید، با فرض اینکه نرخ نمونه برداری 44000 نمونه در ثانیه باشد، سیستم دیجیتال کننده هر 0.00002 ثانیه یکبار ولتاز خروجی میکروفون را – که تقویت و فیلتر شده است – خوانده و مقدار آن را به چندی کننده ارسال می کند.
چندی کردن سیگنال
در مرحله نمونه برداری دیدیم که یک نمونه از سیگنال به شکل ولتاژ نمونه برداری شد. در این مرحله ولتاز نمونه برداری شده باید به شکل دیجیتالی (عدد باینری) تبدیل شود. برای این منظور نیز از مبدل های آنالوگ به دیجیتال استفاده می کنیم. به عنوان مثال یک مبدل انالوگ به دیجیتال 8 بیتی به ازای ورودی خود عددی بین 0 تا 255 تولید می کند. فرض کنید ورودی مبدل در بازه 0 تا 5 ولت باشد. این بدان معناست که به ازای ورودی 0 ولت، خروجی مبدل عدد باینری 0 و به ازای ورودی 5 ولت خروجی مبدل عدد باینری 255 خواهد بود. بدیهی است که افزایش تعداد بیت های مبدل موجب افزایش دقت چندی شدن خواهد شد.
مفاهیم اولیه در سیگنال
به جرات می توان گفت که مهمترین مفاهیم در پردازش سیگنال مفاهیم کانولوشن و فرکانس می باشد. به طوریکه مباحثی همچون طراحی فیلترهای دیجیتالی به شدت تحت تاثیر این مفاهیم هستند. در این بین مفهوم فرکانس برای اغلب دانشجویانی که در علوم مهندسی به غیراز مهندسی الکترونیک تحصیل کرده اند نامفهوم است. در این بخش سعی می کنیم مفاهیم مرتبط با حوزه فرکانس را به زبانی ساده شرح دهیم. مفهوم فرکانس در پردازش سیگنال ارتباط بسیار قوی با موج سینوسی دارد (در مقاله مربوط به بسط فوریه علت این امر بیان شده است). از اینرو همه مفاهیم مرتبط با حوزه فرکانس را بر روی موج سینوسی شرح می دهیم.
موج سینوسی
یک موج سینوسی که شکل آن در روبرو آمده است، با استفاده از رابطه زیر تعریف می گردد:
![]()
که در این رابطه A، f، t و… به ترتیب نشان دهنده دامنه، فرکانس، زمان و فاز موج سینوسی هستند. شکل بالا نمودار موج سینوسی را نشان می دهد. در یک موج سینوسی دامنه، شدت موج سینوسی را تعیین می کند. همچنین فرکانس نیز نشان دهنده تعداد دفعات تکرار موج سینوسی در واحد زمان است. جناب آقای زوزف فوریه در قرن 18 نشان دادند که همه سیگنال های موجود در جهان را می توان به شکل ترکیبی از امواج سینوسی نشان داد. سیگنال های صوتی نیز از این قائله مستثنی نیستند و هر سیگنال صوتی را می توان به امواج سینوسی تشکیل دهنده آن شکست. در این بخش قصد تفکیک سیگنال های به امواج سینوسی تشکیل دهنده آن را نداریم. بلکه می خواهیم نشان دهیم چگونه می توان با استفاده از امواج سینوسی، به تولید صدا پرداخت.
برای ملموس تر شدن مفهوم موج سینوسی در اینجا به ارائه چند مثال با استفاده از MATLAB می پردازیم. دستورات زیر را به ترتیب در محیط MATLABB وارد کنید:
>> i = 1:44000;
>> w1 = sin(2*pi * 500/44000 * i);
>> w2 = sin(2*pi * 1000/44000 * i);
>> w11 =10* sin(2*pi * 500/44000 * i);
>> w22 =10* sin(2*pi * 1000/44000 * i);
>> wavplay(w1,44000);
>> wavplay(w2,44000);
>> wavplay(w11,44000);
>> wavplay(w22,440000);
دستور اول یک آرایه شامل مقادیر 1 تا 44000 تولید می کند که از این آرایه برای تولید موج سینوسی استفاده می کنیم. دستور دوم یک موج سینوسی با دامنه 1 و فرکانس 500 هرتز تولید می کند. دستور سوم نیز یک موج سینوسی با دامنه 1 و فرکانس 1000 هرتز ایجاد می کند. همانطور که در دستورات نیز مشاهده می کنید، w11 و w22 نیز موج های سینوسی با فرکانس 500 و 1000 هرتز تولید می کنند و تنها تفاوت آن ها با w1 و w2 در مقدار دامنه موج ها است.
زمانی که دستور wavplay را اجرا کنید، هریک از موج های تولید شده به شکل صوت از بلندگوی کامپیوتر شما خارج خواهند شد. از این چهار موج سینوسی می توان چنین نتیجه گرفت که 1) فرکانس موج سینوسی زیر و بم بودن صدا تعیین می کند و 2) دامنه موج سینوسی نیز بلندی صدای تولید شده را نشان می دهد. همانطور که شما نیز حدس می زنید برای ما مقدار فرکانس از اهمیت بیتشری نسبت به دامنه برخوردار است. نکته دیگری که در این تکه کد آن را مشاهده می کنید نحوه تولید موج سینوسی است. در ابتدا رابطه تولید یک موج سینوسی را نشان دادیم. با این حال زمانی که بخواهیم موج سینوسی را برای تولید صدا ایجاد کنیم، پارامتر دیگری نیز به این رابطه افزوده می شود:
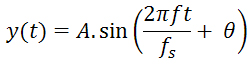
که در این رابطه fs نشان دهنده این واقعیت است که در یک ثانیه چند عدد نمونه برداری باید انجام گیرد. در تکه کد بالا مقدار 44000 نشان می دهد که در یک ثانیه 44000 داده در فایل صوتی وجود دارد. نکته دیگر آن که ماکزیمم فرکانس قابل تولید با fs نمونه، برابر با fs/2 خواهد بود. به عنوان مثال در تکه کد بالا ماکزیمم فرکانس قابل تولید با نرخ نمونه برداری 44000 در ثانیه برابر با 24 کیلوهرتز (آستانه شنوایی انسان) است. حال می توانید حدس یزنید که در نرم افزارهای صوتی، چرا فایل های با بیش از 44000 نرخ نمونه برداری نمی توان پیدا کرد.
هریک از موج های w1، w2، w11 و w22 به مدت 1 ثانیه از کارت صوتی پخش می شوند. این بدان دلیل است که تعداد نمونه هایی که برای هریک از آن ها تولید گردیده دقیقا 44000 نمونه است (مقدار i که از 1 تا 44000 است). در صورتی که بخواهید هریک از امواج فوق به مدت 2 ثانیه از کارت صوتی پخش شوند، دستور اول را به صورت زیر تغییر دهید:
i = 1:88000;
به عنوان مثال می توانید موج های سینوسی مختلف با فرکانس های گوناگون و دامنه ها و مدت زمان های متفاوت تولید کرده و نتایج هریک را با دیگری مقایسه کنید (در صورتی که کارت صوتی سیستم تان به آمپلی فایر متصل نیست، از تولید فرکانس های کمتر از 100 هرتز و موج های با دامنه بالا تا حد ممکن خودداری کنید. چرا که ممکن است به سیستم آسیب برساند).
سیگنال های DTMF
همگی با سیگنال هایی که به هنگام فشردن دکمه های تلفن از گوشی آن می شنویم آشنا هستیم. به این سیگنال های در اصطلاح سیگنال های DTMF گویند.در کل 12 سیگنال DTMF متفاوت بر روی صفحه کلید تلفن وجود دارد (البته با احتساب حروف A، B، C و D تعداد کل سیگنال های DTMF 16 عدد می باشد). هریک از سیگنال های DTMF نیز از ترکیب دو موج سینوسی با فرکانس های مختلف تشکیل شده است. به عنوان مثال فشردن کلید 1 موجب تولید صدایی می شود که از ترکیب دو موج سینوسی با فرکانس های 697 هرتز و 1209 هرتز تشکیل شده است. جدول زیر فرکانس های تشکیل دهنده هر یک از 12 سیگنال DTMF را نشان می دهد:
سیگنال های A، B، C و D نیز با افزودن ستون 1633 هرتزی می توانند تولید شوند. در این فرآیند انتخاب فرکانس ها به گونه ای صورت گرفته است که 1) هیچ فرکانسی مضربی از فرکانس دیگر نیست 2) اختلاف هیچ دو فرکانسی برابر با مقدار فرکانس دیگری در جدول نیست و 3) جمع هیچ دو فرکانسی برابر با مقدار فرکانسی دیگری در جدول نیست (کار مهندسی یعنی این!). شکل موج هریک از این 12 سیگنال نیز در زیر آمده است(به همان ترتیبی که در جدول فوق نشان داده شده است) :
| 1477 | 1336 | 1209 | |
 |
 |
697 | |
 |
 |
 |
770 |
 |
 |
 |
852 |
 |
 |
 |
941 |
تکه کد زیر نیز نحوه تولید سیگنال DTMF مربوط به کلید 1 را در محیط MATLAB نشان می دهد :
>> i= 1:44096;
>> wv1 = (0.5*sin(2*pi* (697/44096) * i)) + (0.5*sin(2*pi* (1209/44096) * i)); >> wavplay(wv1,440966);
دیگر سیگنال های DTMF نیز به همین ترتیب و تنها با تغییر دادن مقادیر فرکانس موج ها تولید می شوند. کار کردن بر روی سیگنال های DTMF می تواند تمرین بسیار خوبی برای افرادی باشد که تازه پا در دنیای سیگنال دیجیتال گذارده اند. به عنوان مثال می توانید سیگنالی را تولید کرده و یک نویز تصادفی به آن اضافه کنید. سپس با پخش صدا تاثیر نویز در خروجی را مشاهده کنید.
ترکیب، تفکیک و انطباق
ماهیت سیستم های خطی به گونه ای است که ترکیب سیگنال در آن ها تنها با تغییر مقیاس و جمع شدن امکان پذیر می باشد. در حقیقت سیگنالی که ما در خروجی یک سیستم خطی مشاهده می کنیم حاصل این عملیات است که به این عمل Synthesis می گوییم. عکس عمل سنتزینگ را نیز تفکیک کردن یا Decomposition می گوییم. تفکیک کردن به این معناست که سیگنال ورودی را به چندین سیگنال تفکیک کنیم، به گونه ای که از ترکیب همه این سیگنال ها سیگنال اصلی به وجود آید.
توجه به این نکته حائز اهمیت است که ترکیب چندین سیگنال همیشه موجب تولید یک سیگنال واحد می شود و این در حالی است که یک سیگنال را می توان به سیگنال های بیشماری تفکیک کرد. برای روشن شدن مطلب به این مثال توجه کنید. حاصل جمع عدد 3 و عدد 4 برابر با عدد 7 است (4+3=7). جمع عدد 3 و 4 را ترکیب کردن دو عدد می گوییم. تفکیک کردن عدد 7 نیز به این معنا است که آن را به چند عدد بشکنیم به گونه ای از ترکیب مجدد آن اعداد، مقدار 7 به دست آید. به عنوان مثال عدد 7 را می توان به اعداد 1، 2 ،4 یا 3،2،2 یا 1،6 و… تفکیک کرد. شکل زیر مفهوم ترکیب و تفکیک را نشان می دهد.
ترکیب و تفکیک سیگنال دیجیتالی
حال که با مفهوم ترکیب و تفکیک آشنا شدیم، به بررسی بنیادی ترین مفهوم پردازش سیگنال یعنی اطباق می پردازیم. مفهوم انطباق به ما کمک می کند که درک صحیحی نسبت به سیگنال ها داشته و با دید بهتری بتوانیم به انالیز سیگنال های دیجیتالی بپردازیم. به عنوان مثال سیگنال نشان داده شده در شکل زیر را در نظر بگیرید.
سیگنال x وارد سیستم خطی شده و در نتیجه آن سیگنال خروجی y تولید می گردد. همانطور که در این شکل نشان داده است، سیگنال ورودی را می توان به تعدادی سیگنال ورودی ساده تر تفکیک کرد (در شکل این سیگنال ها با نام های مشخص گشته اند). سپس هریک از این سیگنال ها منحصرا وارد سیستم خطی شده و مجموعه سیگنال های خروجی را تولید می کنند (در شکل این سیگنال ها با نام های مشخص گشته اند). در نهایت سیگنال های خروجی با هم ترکیب شده وسیگنال خروجی y را تولید می کنند.
مهمترین بخش مفهوم انطباق در اینجا نهفته است. سیگنالی که از تفکیک کردن سیگنال ورودی به سیگنال های ساده تر، گذراندن آن ها از سیستم خطی و درنهایت ترکیب ان ها به وجود می آید، درست همانند سیگنال است که از اعمال مستقیم سیستم خطی بر روی مستقیم سیگنال ورودی به وجود می آید. با وجود چنین نگرشی دیگر نیازی نیست بدانیم که یک سیگنال پیچیده چگونه توسط سیستم خطی تحت تاثیر قرار می گیرد. بلکه کافی است بدانیم که سیگنال های ساده تر چگونه توسط این سیستم خطی تغییر می یابند.
مفهوم انطباق را با یک مثال به پایان می بریم. فرض کنید می خواهید در ذهن خود عدد 2041 را در عدد 4 ضرب کنید. شما این کار را چگونه انجام میی دهید؟ آیا در ذهن خود 2041 تا مداد در نظر می گیرید ،
سپس آن را چهار برابر کرده و شروع به شمردن مدادها در ذهن خود می کنید؟ قطعا چنین عملی را انجام نمی دهیم. بلکه ما نیز در اینجا به طور خودکار از عمل انطباق استفاده می کنیم. بدین معنی که ابتدا عدد 2041 را به سه عدد ساده تر ساده تر 1 + 40 + 2000 تفکیک کرده و سپس هریک از این سه مولفه را در عدد 4 ضرب می کنیم. درنهایت نیز نتایج به دست آمده را باهم جمع می کنیم. به عبارت دیگر 4 + 160 + 8000 = 8164. یک فرد خبره در پردازش سیگنال نیز هنگام کار کردن بر روی سیگنال های دیجیتالی سعی می کند با چنین نگرشی به یک سیگنال پیچیده نگاه کند.
پاسخ ضربه یک سیگنال دیجیتالی
هنگام بررسی مفهوم ترکیب و تفکیک دیدیم که یک سیگنال دیجیتالی را چگونه می توان به سیگنال های ساده تر تفکیک کرد و یا چگونه سیگنال های تفکیک شده را باهم ترکیب کنیم. یکی از مهمترین روش های تفکیک سیگنال های دیجیتالی در حوزه زمانی، تفکیک ضربه ای است (در حوزه زمانی محور افقی نشان دهنده زمان / مکان و محور عمودی برابر با مقدار سیگنال در آن زمان/مکان می باشد).
در یک سیگنال ضربه همه مقادیر به جز یکی از آن ها صفر است. در حقیقت تفکیک ضربه ای، یک سیگنال با N نمونه را به N سیگنال ضربه ای تفکیک می کند. تفکیک ضربه ای از این جهت دارای اهمیت است که با استفاده از آن در هر لحظه می توان تنها به بررسی یک مولفه از سیگنال ورودی پرداخت. دانستن پاسخ سیستم به یک سیگنال ضربه ای موجب می شود که بتوانیم خروجی نهایی سیستم را به ازای هر سیگنال ورودی محاسبه کنیم. برای این منظور نیز از عملگری به نام کانولوشن استفاده می کنیم که در مقاله های بعدی به بررسی آن پرداخته ایم. شکل زیر نحوه تفکیک سیگنال ورودی به سیگنال های ضربه را نشان می دهد:
در مقاله ترکیب و تفکیک نشان دادیم که برای ضرب کردن عدد 2041 در عدد 4 می توانیم ابتدا عدد 2041 را به سه عدد 1+40+2000=2041 تفکیک کنیم، سپس هریک ازاین اعداد را در عدد چهار ضرب کرده و با ترکیب آن ها نتیجه نهایی را به دست آوریم. به عبارت دیگر :
8164 = 1*4 + 40 * 4 + 2000 * 4 = (1 + 40 + 2000) * 4 = 2041 * 4
در اینجا نیز پس از آنکه سیگنال ورودی به سیگنال های ضربه تفکیک شد، می توانیم تک تک آن ها را وارد سیستم کرده و خروجی همه آن ها را به دستت آوریم. سپس با ترکیب همه خروجی ها نتیجه نهایی به دست می آید(منظور از ترکیب سیگنال همان جمع برداری سینگنال ها می باشد). به عبارت دیگر در این روش پس از انکه سیگنال ورودی با N نمونه را به N سیگنال ضربه ای تفکیک کردیم، هریک از این سیگنال های ضربه را وارد سیستم کرده و خروجی سیستم به ازای ورودی ضربه را به دست می آوریم. در نهایت با جمع برداری همه سیگنال ها می توانیم پاسخ نهایی سیستم برای سیگنال ورودی را محاسبه کنیم.
می توان نتیجه گرفت که منظور از پاسخ ضربه یک سیستم، خروجی سیستم به ازای ورودی ضربه می باشد. فرض کنید پاسخ ضربه سیستم به سیگنال ورودی همانند شکل روبرو باشد. این بدان معناست که با ورود یک سیگنال ضربه به سیستم، سیگنال خروجی شکلی
همانند این شکل خواهد داشت. در مقاله پاسخ ضربه این بحث را با جزئیات بیشتری بررسی خواهیم کرد. تکه کد زیر در محیط MATLAB برای تفکیک یک سیگنال به سیگنال های ضربه می تواند بکار رود:
function dec = impulseDecompose(signal)
sz = size(signal);
dec = zeros(sz(2),sz(2));
for i= 1:sz(2)
dec(i,i) = signal(i);
end
end
کانولوشن
در مباحث قبل نشان دادیم که چگونه می توان یک سیگنال دیجیتالی را با استفاده از سیگنال های ضربه تفکیک کرد. سپس مفهوم پاسخ ضربه را بررسی کردیم و دیدیم که هرگونه انتقال و تغییر مقیاس در ورودی موجب همان اندازه انتقال و تغییر مقیاس در خروجی خواهد شد. در این مقاله می خواهیم در عمل نشان دهیم که چگونه می توان با در دست داشتن پاسخ ضربه یک سیستم، خروجی آن سیستم را به ازای هر سیگنال ورودی محاسبه کرد. برای این منظور نیز از عملگری به نام عملگر کانولوشن استفاده خواهیم کرد. همانطور که می دانید هر سیگنال را می توان به شکل یک بردار تصور کرد. با دانستن این نکته می توان حدس زد که منظور از جمع/تفریق دو سیگنال همان جمع/تفریق دو بردار می باشد. به عبارت دیگر عملگر جمع و تفریق با گرفتن دو سیگنال هم اندازه در ورودی خود آن دو را ترکیب کرده و سیگنال خروجی را تولید می کند.
فرض کنید پاسخ ضربه یک سیستم نمونه را داریم و می خواهیم به ازای هر ورودی سیگنال، خروجی سیستم را به دست آوریم. واضح است که پاسخ ضربه می تواند هم اندازه با سیگنال ورودی نباشد (در اکثر موارد نیز چنین است). خروجی نهایی سیستم از کانوالو کردن سیگنال ورودی با پاسخ ضربه سیستم به دست می آید.
شکل زیر نشان می دهد که عملگر کانولوشن چگونه بر روی سیگنال ورودی اعمال می شود. فرض کنید سیگنال ورودی X و سیگنال خروجی Y ثابتت باشند. درمقابل، ماشین کانولوشن (هرچیزی که داخل کادر خط چین است) می تواند به چپ یا راست حرکت کند. پس از آنکه ماشین کانولوشن حرکت کرد، مقادیر آن زیر مقادیر سیگنال ورودی قرار می گیرند. سپس چهار نمونه از سیگنال ورودی وارد ماشین کانولوشن شده و با مقادیر نشان داده شده در ماشین کانولوشن (پاسخ ضربه) یک به یک ضرب می شوند. در نهایت نیزجمع کل حاصلضرب ها در نقطه متناظر از سیگنال خروجی قرار می گیرد. به عنوان مثال در شکل نشان داده شده، مقدار y[6] در خروجی با استفاده از مقادیر x(3..6) از سیگنال ورودی محاسبه شده است.
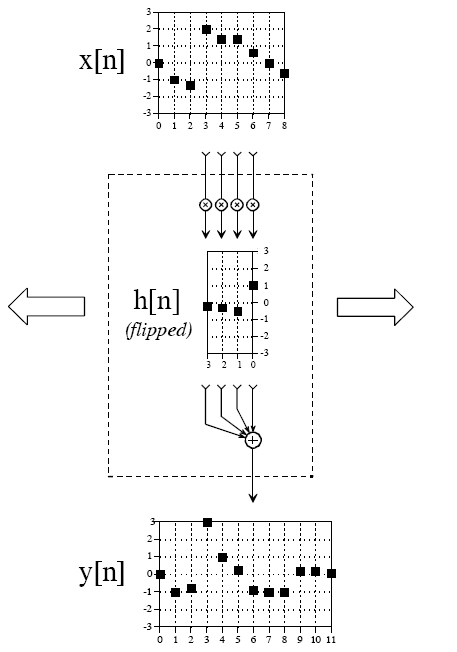
برای محاسبه مقدار y(7) ماشین کانولوشن یک واحد به سمت راست حرکت کرده و مقادیری از سیگنال ورودی که بالای ماشین کانولوشن قرار دارند وارد ماشین شده و با مقادیر پاسخ ضربه ضرب می شوند در نهایت نیز جمع کل آن ها به عنوان مقدار y(7) برگردانده می شود. همین روند برای محاسبه کلیه نمونه های سیگنال خروجی تکرار می شود.
توجه کنید که نحوه چینش مقادیر پاسخ ضربه در داخل ماشین کانولوشن از اهمیت ویژه ای برخوردار است و باید به شکل راست به چپ باشد. راست به چپ کردن مقادیر پاسخ ضربه در داخل ماشین کانولوشن باعث می شود تا مقدار شماره 0 در سمت راست و سایر مقادیر به ترتیب و در سمت چپ آن قرار گیرند. حال که عمگر کانولوشن را توضیح دادیم می توانیم فرموله کردن آن بپردازیم. اگر x[n] سیگنال ورودی با N نمونه از 0 تا N-1 باشد و h[n] نیز سیگنالی M نقطه ای با اندیس 0 تا M-1 باشد کانولوشن این دو، سیگنالی با N+M-1 نمونه است که مقدار آن در هر نقطه به صورت زیر محاسبه می گردد:
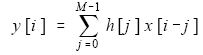
در محیط MATLAB از تابع conv برای کانولوشن دو سیگنال می توانیم استفاده کنیم. به عنوان مثال مجموعه دستورات زیر را وارد کرده و نتایج آن مشاهده کنید.
>> a = 0.5 * sin(2*pi*200/8000*[1:8000]);
>> plot(a(1:300))
>> r = rand(1,8000) ./ 10;
>> plot(r(1:300))
>> b = a + r;
>> plot(a(1:300)), hold on, plot(b(1:300),’r’)
>> i = -50:50;
>>filter = exp((i .* i) ./ (zeros(1,101)- 18)) ./ (ones(1,101) * (sqrt(2*pi)*3));
>> plot(filter)
>> c = conv(b,filter);
>> wavplay(a)
>> wavplay(b)
>> wavplay(c)
>> plot(a(1:300)), hold on, plot(b(1:300),’r’),plot(c(1:300),’kk’)
همانطور که در مقاله مربوط به موج سینوسی نشان دادیم، 2 دستور اول موج سینوسی با فرکانس 200 فرتز و نرخ نمونه برداری 8000 نمونه در ثانیه ایجاد می کند. سپس یک سیگنال تصادفی تولید شده و پس از جمع شدن با موج سینوسی، سیگنال جدیدی به دست می آید. در مرحله بعد یک فیلتر گاوسین (شکل روبرو) به اندازه 101 نمونه ایجاد می شود(این همان پاسخ ضربه سیستم را نشان می دهد). در نهایت سیگنال b با فیلتر گاوسین کانوالو شده و سیگنال c تولید می گردد.
زمانی که این سه سیگنال را پخش می کنید متوجه خواهید شد که سیگنال اول یک صدای ایده آل با فرکانس 200 هرتز در خروجی تولید می کند. اما زمانی که سیگنال دوم را پخش می کنید به دلیل افزودن مقادیر تصادفی به آن نویزهایی در خروجی خواهید شنید. نهایتا در
سیگنال سوم نیز خواهید شنید که نویزهای سیگنال تا حدود بسیار زیادی از سیگنال نویزدار حذف شده است. در حقیقت حذف نویز به دلیل اعمال پاسخ ضربه گاوسین (فیلتر گاوسین) به سیگنال صورت پذیرفته است.
حوزه زمان و حوزه فرکانسی
در مباحث مربوط به موج سینوسی و سیگنال های DTMF نشان دادیم که چگونه می توان با استفاده از ترکیب موج های سینوسی مختلف به تولید صدا پرداخت. دو پارامتر اصلی در موج سینوسی فرکانس و دامنه آن می باشد که هریک از آن ها به ترتیب زیر/بم بودن صدا و بلندی صدا را تعیین می کنند. سیگنال هایی که به این طریق به وجود می آیند را سیگنال های حوزه زمانی می گوییم. وقتی می گوییم سیگنالی در حوزه زمانی است این بدان معناست که محور افقی در نمودار این سیگنال نشان دهنده زمان و محور عمودی نشان دهنده مقدار سیگنال می باشد. به عنوان مثال شکل زیر سیگنال زمانی ضبط شده برای حرف ” آ ” را نشان می دهد.
حال عکس این قضیه را در نظر بگیرید. فرض کنید سیگنالی به ما داده شده است و ما می خواهیم بدانیم در این سیگنال چه فرکانس هایی وجود دارد(فرکانس ها یک سیگنال گفتار از اهمیت بسیار ویژه ای در شناسایی گفتار دارند). همانطور که می دانید سیگنال داده شده در حوزه زمان است و به راحتی نمی توان فرکانس های مختلف را در این حوزه پیدا کرد. اما می توان با تبدیل کردن سیگنال مذکور از حوزه زمان به حوزه فرکانس این کار را انجام داد. بنابراین در اینجا مسئله پبدا کردن روشی است که بتواند سیگنال ورودی را از حوزه زمان به حوزه فرکانس تبدیل کند. شکل زیر سیگنال ضبط برای حرف ” آ ” را در حوزه فرکاس نشان می دهد. محور افقی در حوزه فرکانس نشان دهنده فرکانس و محور عمودی نشان دهنده اندازه فرکانس می باشد.
به نمودار فرکانس سیگنال نمودار طیف سیگنال نیز گفته می شود.
نمودار فرکانسی سیگنال نشان می دهد که سیگنال مورد بحث از چه فرکانس هایی تشکیل شده است. به عنوان مثال هریک از آواهای ” آ “، ” ای ” یا ” او ” از فرکانس های مختلفی تشکیل شده اند که توسط آن ها می توان به شناسایی هریک از حروف در یک گفتار پرداخت.
حال این سوال مطرح می شود که منظور از تبدیل یک سیگنال چیست؟ هرتبدیل تابعی است که ممکن است پارامترهای مختلفی داشته باشد. این تابع ریاضی ورودی را گرفته و پس از اعمال تابع بر روی ورودی، خروجی جدیدی تولید می کند که این خروجی ماهیت های دیگری از سیگنال را برای ما نشان می دهد. به عنوان مثال تبدیل سیگنال از حوزه زمان به حوزه فرکناس موجب مشخص شدن فرکانس های تشکیل دهنده یک سیگنال می شود. دو تبدیل مهمی که برای این منظور به کار می رود، تبدیل فوریه و تبدیل هارتلی است که در این بین تبدیل فوریه از اهمیت بسیار بیشتری برخوردار است. در مقاله بعدی به بررسی تبدیل فوریه خواهیم پرداخت.
تبدیل فوریه
همانطور که می دانید مهمترین ویژگی در ادای هر حرف فرکانس های تشکیل دهنده آن حرف می باشد. به عنوان مثال سه فرکانس اصلی حرف ” آ ” فرکانس های 750، 1150 و 2400 هرتر بوده و همین فرکانس های برای حرف ” او ” 400، 1150 و 2300 هرتز می باشند. بنابراین آنچه باعث تفکیک دو حرف ” آ ” و ” او ” از همدیگر می شود، فرکانس های تشکیل دهنده آن می باشد. از اینرو در کاربردهای پردازش گفتار پیدا کردن فرکانس های تشکیل دهنده یک سیگنال گفتاری از اهیت بسیار زیادی برخوردار می باشد.
همانطور که می دانید سیگنال گفتار به شکل یک سیگنال زمانی در اختیار ما قرار دارد و تشخیص فرکانس های تشکیل دهنده یک سیگنال در حوزه زمانی غیرممکن است. به عنوان مثال شکل زیر را که نشان دهنده سیگنال گفتار زمانی حرف ” آ ” می باشد در نظر بگیرید. بخشی از این سیگنال به شکل زوم شده در شکل نشان داده شده است.
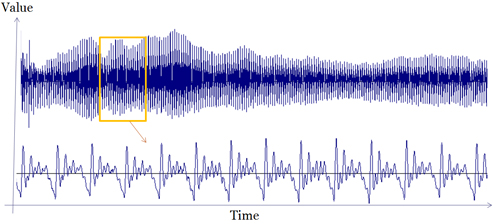
از این شکل پیداست که پیدا کردن فرکانس های تشکیل دهنده این سیگنال از روی سیگنال زمانی غیررممکن می باشد. از اینرو نیاز به ابزار دیگری داریم که بتواند این کار را برای ما انجام دهد. آقای فوریه نشان دادند که هر تابع متناوب را می توان به شکل ترکیبی از موج های سینوسی (یا کوسینوسی) نشان داد که این مطلب را با نام سری های فوریه می شناسیم. از مقاله مربوطه به موج سینوسی به یاد دارید که هر موج سینوسی می تواند به شکل یک صوت در خروجی بلندگو به شنیده شود. در این بین فرکانس موج سینوسی نیز مستقیما زیر و بم بودن صوت تولید شده را تعیین می کند.
با توجه به این دو حقیقت می توان دریافت که با استفاده از آنالیز فوریه یک سیگنال می توان موج های سینوسی تشکیل دهنده آن را استخراج کرد و از روی موج های سینوسی نیز می توان فرکانس های تشکیل دهنده سیگنال گفتار را به دست آورد. با این حال نمی توان مستقیما از سری های فوریه برای این منظور بهره جست. چراکه سری های فوریه بر روی توابع متناوب تعریف شده اند و این در حالی است که ما در اینجا با سیگنال سروکار داریم که هیچ تابعی را نمی توان برای یک سیگنال گفتار تخمین زد. برای رفع این مشکل ابزاری با نام تبدیل فوریه معرفی شده است که بر روی داده های عددی (سیگنال) اعمال می شود. تبدیل فوریه گسسته مختلط سیگنال s به طول N را می توان با استفاده از رابطه زیر تعریف کرد:
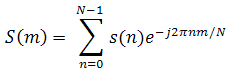
از قانون اویلر نیز به یاد دارید که :
![]()
بنابراین رابطه فوق را می توان به شکل زیر بازنویسی کرد :
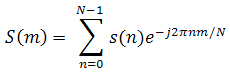
که در این رابطه N اندازه سیگنال ورودی، s(n) مقدار سیگنال ورودی در نقطه n، m اندیس فرکانس، S(m) اندازه فرکانس در اندیس m ام می باشند. همانطور که می دانید S(m) یک عدد مختلط است و بنابراین برای به دست اندازه فرکانس در اندیس mام باید بزرگی این عدد مختلط را محاسبه کرد. بزرگی یک عدد مختلط از رابطه زیر به دست می آید :
![]()
پس از آنکه تبدیل فوریه بر روی سیگنال ورودی اعمال شد، بردار S در فرکانس های تشکیل دهنده سیگنال s دارای مقداری بسیار بزرگتر از 0 و در سایر نقاط بزرگی نزدیک به صفر خواهد داشت. بنابراین می توان برای پیدا کردن فرکانس های تشکیل دهنده یک سیگنال گفتار تبدیل فوریه را بر روی سیگنال ورودی اعالم کرده و پس از محاسبه بزرگی خروجی، فرکانس های تشکیل دهنده آن سیگنال را از روی بزرگی هر فرکانس استخراج کرد. در مقاله بعدی سعی می کنیم این مساله را به همراه سایر پارامترها و خصوصیات سیگنال گفتار مورد بررسی قرار دهیم. برای محاسبه تبدیل فوریه یک سیگنال در محیط MATLAB از تابع fft می توانید استفاده کنید:
>> a = sin(2*pi * 200/1000 * t);
>> b = sin(2*pi * 10/1000 * t);
>> c = sin(2*pi * 500/1000 * t);
>> d = a + b + c;
>> ffd = fft(d);
>> mffd = abs(ffd);
>> plot(mffd(1:5000))
در این تکه کد ابتدا سه موج سینوسی با فرکانس های 20، 10 و 500 هرتز تولید کرده و پس از ترکیب آن ها سیگنال جدیدی با نام d به وجود آوردیم. سپس با استفاده از تابع fft تبدیل فوریه سیگنال d را محاسبه کرده و با استفاده از تابع abs بزرگی سیگنال تبدیل شده را به دست آوردیم. در نهایت نیز به رسم سیگنال تبدیل شده پرداختیم.
در نموداری که بس از فراخوانی دستور plot برای شما نشان داده می شود، در نقاط 10، 200 و 500 نمودار دارای مقدار بزرگ بوده و در سایر نقاط دارای مقدار صفر است. این نشان می دهد که سیگنا ل d شامل فرکانس های 10، 200 و 500 هرتز می باشد.
مراجع و منابع
- ابويي اردكاني، محمد؛ نادر نقشينه، فاطمه شيخ شعاعي، فناوري پردازش گفتار و كاربرد آن در كتابخانه ها، مجله روانشناسي و علوم تربيتي دانشگاه تهران، 1385.
- آیت، سعید، مبانی پردازش سیگنال گفتار، ناشر: دانشگاه پیام نور،1387
- جكسون. تي و بيل. آر، آشنايي با شبكههاي عصبي، ترجمه دكتر محمود البرزي، تهران : موسسة انتشارات علمي دانشگاه صنعتي شريف، چاپ دوم، 1383
- قمي، عليرضا، شبكه هاي عصبي، نشريه دنياي كامپيوتر و ارتباطات، شماره 12، صفحات 66 تا 69
- سعيدي، مسعود، شبكه هاي عصبي (2)، نشريه شبكه، شماره 52، اسفند 1383، صفحه 210 تا 211
- ناتان گوریچ، اوری گوریچ، خودآموز ویژوال سی در 21 روز، مترجم جعفرنژاد قمی
- مماني، حامد و نرگس پور اصغري حقي و ساعد علي ضمير، شبكه هاي عصبي و كاربردهای آن، نشريه صنايع، شماره 30
- سيستم هاي شناسايي صدا، بزرگراه رايانه9 (95) ،1385.
- دستگاههاي مترجم جهاني بزرگراه رايانه 8(77)، 1384.
- بدون محدوديت زبان سفر كنيد .روزنامه جام جم،5 آذر،1385.
- Metaxiotis, Kostas & John Psarras (2004), The Contribution of Neural networks and genetic algoritms to business decision support,Management decision, vol 42,no .2, Emerald group publishing limited , pp. 229.242
- Curry ,B & L. Moutinho (1993), Neural Network in marketing: Modelling consumer Responses to Advertising Stimuli ,European Journal of marketing, vol 27 ,no. 7 , MCB university press , pp 5. 20
- Wray, B, A. palmer & D.Bejou (1994),Using Neural Network Analysis to evaluate Buyer, Seller Relationships, European Journal of Marketing, vol 28 , no. 10 , MCB university press, pp 32.48
- Venugopal.V & W. Beats (1994), Neural networks and Statistical Techniques in marketing research, Marketing intelligence & planning, vol 12 , no. 7 , MCB university press, pp30. 38
- Davies, F,L. Moutinho & B. Curry (1996) ATM user attitudes: a neural network analysis, marketing intelligence & planning,vol14 , no.2,MCB university press,pp26 .32
- Austin Marshall March 3, 2005 neural Network for Speech Recognation
- Jurafsky, Daniel and Martin, James H. (2000) Speech and Language
- Processing:An Introduction to Natural Language Processing,Computational Linguistics, and Speech Recognition (1st ed.). Prentice Hall
- Golden, Richard M. (1996) Mathematical Methods for Neural Network Analysis and Design (1st ed.). MIT Press
- Anderson, James A. 1995) An Introduction to Neural Networks (1st ed.). MIT Press
- Hosom, John-Paul, Cole, Ron, Fanty, Mark, Schalkwyk, Joham, Yan, Yonghong,Wei, Wei (1999,February2). Training Neural Networks for Speech Recognition Center for Spoken Language Understanding, Oregon Graduate Institute of Science and Technology,
- Slaney, Malcolm Auditory Toolbox Interval Research Corporation
- Alan V.Oppenheim,Ronald W.Schafer,John R.Buck.Discrete Time Signal Processing .Prentice Hall International Edition
- Rafael C. Gonzalez,Richard E.Woods.Digital Image Processing. Translated by:M.Khademi (ph.D), D.Jafari. Ferdowsi University of Mashhad
-
- – Speech Recognition Systems ↑
-
- – Text To Speech ↑
-
- – Speech Recognition System ↑
-
- -Hidden Markov Model ↑
-
- – Kurzweil ↑
-
- – Dragon ↑
-
- – James K.Baker ↑
-
- – Dragon Systems ↑
-
- – Dragon Dictate ↑
-
- – Dragon Naturally Speaking ↑
-
- – Scansoft ↑
-
- – Bill Gates ↑
-
- -Office XP ↑
-
- -Word 2002 ↑
-
- – Seton Hall University ↑
-
- – Speech Recognition Systems ↑
-
- – Carpal Tunnel Syndrome ↑
-
- -Global Autonomous Language Exploitation ↑
-
- – board Dialogic ↑
-
- -Analog -to-digital converter ↑
-
- – Plosive Consonant ↑
-
- – phoneme ↑
-
- – Plot ↑
-
- -burn ↑
-
- – Hidden Markov Model ↑
-
- – Neural Netwok Model ↑
-
- -score ↑
-
- – Speech To Text ↑
-
- -Speech To Speech ↑
-
- – Speech To Command ↑
-
- – IBM Voice Dictation for Linux ↑
-
- – Myers Hidden Markov Model Software ↑
-
- -Speech processing Lab ↑
-
- – computer control ↑
-
- – Consol Voice Control ↑
-
- – Game Commander ↑
-
- – PC Pocket ↑
-
- Voice Command ↑
-
- – Microsoft Office ↑
-
- – Pentium ↑
-
- – Notpad ↑
-
- – Client ↑
-
- – Microsoft Word ↑
-
- – Notepad ↑
-
- -Consol Voice Control ↑
-
- -Game Commander ↑
-
- -IBM Voice Dictation for Linux ↑
-
- -Myers Hidden Markov Model Software ↑
-
- – Offline ↑
-
- -Cingular wireless ↑
-
- – DRAGON NATURALLY PEAKIN ↑
-
- – TUNGSTEN ↑
-
- – Tellme networks ↑
-
- – Noise ↑
-
- -noise-canseling ↑
-
- -Homonym ↑
-
- – Digitization ↑
-
- -Phonetic breakdown ↑
-
- -Formant ↑
-
- – Waning , Waxing ↑
-
- – Matching ↑
-
- – Confidence Score ↑
-
- -Finite State ↑
-
- -Quantization ↑
-
- – Sampling ↑
-
- -Coding ↑
-
- -Glottis ↑
-
- -Nasal ↑
-
- – Velum ↑
-
- – Palate ↑
-
- – Epiglottis ↑
-
- -Finite-State Automata & Regular Expresion ↑
-
- -Comutational LINGUISTIC ↑
-
- – Kleen ↑
-
- -Finite-State Transducer ↑
-
- – Weighted Transducer ↑
-
- -Morphological Parsing ↑
-
- – Lexicon ↑
-
- – Morphotactics ↑
-
- – Orthography Rules ↑
-
- -Lexical Level ↑
-
- -Surface Level ↑
-
- -Finite-State Transduser ↑
-
- -Leonard E. Baum ↑
-
- – Deterministic Patterns ↑
-
- – Non-deterministic patterns ↑
-
- -stationarity ↑
-
- – forward ↑
-
- – viterbi ↑
-
- – forward-backward ↑
- –N-gram Model ↑


{kind=link}
بسیار عالی. من یه پایان نامه دارم که آموزش الکترونیکی برای نابینایانه و دقیقا با این مقاله همخوانه. خیلی عالی بود سپاس
درود بر شما
خوشحالیم از اینکه پست های آموزشی ما مورد استفاده شما قرار گرفته است.