توضیحات
Nonlinear control of a boost converter using a robust regression based reinforcement learning algorithm
شبیه سازی در محیط ام فایل و سیمولینک متلب انجام شده است.
دارای گزارش 15 صفحه ای در قالب ورد است.
توضیحات پروژه
طراحی کنترل کننده مبدل بوست با استفاده از یادگیری تقویتی (Reinforcement learning)
در این پروژه مقاله شبیه سازی شده است و مبدل موردنظر مقاله با استفاده از روش PID کنترل ولتاژ انجام شده است.
در گزارش این پروژه نیز به توضیح کد و روش مقاله به صورت همزمان پرداخته شده است.
در پوشه simulation که همراه فایلهای پروژه هست, تعدادی پوشه و کد متلب قرار دارد.
فایل main
شبیه سازی با این فایل اجرا می گردد. پس از اجرای آن یک پنجره جدید باز شده و از شما سوال می کند که کدام شبیه سازی اجرا گردد. این شبیه سازی ها به ترتیب زیر هستند:
- یادگیری تقویتی با تابع پاداش R1
- یادگیری تقویتی با تابع پاداش R2
- یادگیری تقویتی PR با تابع پاداش R1
- یادگیری تقویتی PR با تابع پاداش R1
- یادگیری تقویتی VR با تابع پاداش R1
- یادگیری تقویتی با VR تابع پاداش R1
- کنترل PID
کدهای پوشه utilities
کد inputs
در این کد ورودی های مساله طبق توضیحات بخش شبیه سازی مقاله قرار داده شده اند.
کد results
پس از اجرای هر شبیه سازی، نمودارها از طریق این کد رسم می گردند.
کد reward_function_1
تابع پاداش 1 که طبق معادله 16 نوشته شده است.
کد reward_function_2
تابع پاداش 2 که طبق معادله 17 مقاله نوشته شده است.
کد system_equations
معادلات سیستم در این کد قرار داده شده است. محتویات این کد از معادله 7، 8 و 9 مقاله گرفته شده اند.
کدهای اصلی در پوشه هایی که در ادامه توضیح داده می شوند قرار دارد:
- پوشه Pure rl روش یادگیری تقویتی پایه (خالص) در کد درون این پوشه قرار داده شده است.
- پوشه pr rl شامل یادگیری تقویتی PR (Policy regression) است.
- پوشه vr rl، معادلات روش یادگیری تقویتی VR (Value Regression) در این پوشه قرار دارد.
- در پوشه pid نیز شبیه سازی سیمولینک سیستم با کنترل pid قرار داده شده است( این بخش اضافه تر از کار مقاله هست که به صورت سیمولینک تهیه شده است. ورژن های سیمولینک متلب عبارت است از 2018a تا 2020a). دقت نمایید 5 مدل سیمولینک برای این منظور ساخته شده است. در خطوط 77 تا 81 فایل main خط دستوری مربوط به نسخه متلب خود را از حالت comment خارج کرده و حتما سایر نسخه ها را comment کنید و سپس شبیه سازی را اجرا نمایید.
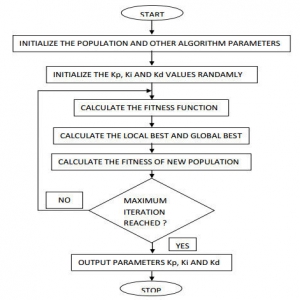
توضیح کد purerl_algorithm
در خطوط 4 تا 8 طبق خواسته کاربر مبنی بر این که شبیه سازی با تابع پاداش 1 انجام شود یا دو تعیین می گردد. روش کار به این صورت است که کاربر از خط 31 به بعد در فایل main، مقادیر ضرایب k1 تا k3 و نیز سایر ورودی هایی که در توابع پاداش استفاده می شود را تعیین می کند. در حالتی که مقادیر k1 و k2 عدد باشند و k3 = [ ] باشد، یعنی تابع پاداش 1 مورد استفاده قرار گیرد و برعکس یعنی در حالتی که k3 عدد باشد و دو ضریب دیگر [ ]، تابع پاداش 2 مورد نظر است. هم چنین ورودی های دیگر مانند ضریب gamma و مقدار مرجع Vo در این خطوط تعیین می گردند.
بقیه توضیحات این بخش با خرید این محصول قابل دریافت است.
توضیح کد prrl_algorithm
تا خط 36 این روش (یعنی از تعیین تابع پاداش تا پایان یافتن متغیر بهینه بیشینه) مانند روش خالص است. اما طبق قسمت 5 جدول 2 مقاله، در خطوط 39 تا 42، متغیر به دست می آید.
ادامه توضیحات این بخش نیز با خرید این پروژه قابل دریافت است.
توضیح کد vrrl_algorithm
در این حالت نیز شرایط تا حد بسیار زیادی مانند روش PR است. تنها تفاوت در این می باشد که دیگر متغیر محاسبه نمی گردد و ضرایب duty cycle به صورت مستقیم از طریق متغیرهای حالت x و متغیر بهینه تعیین می گردند. سایر عملیات قبل و بعد مانند روش PR می باشد.
توضیح شبیه سازی سیمولینک روش PID
این مدل بسیار ساده است. در قسمت 1 نشان داده شده در شکل سیمولینک که در گزارش این پروژه آمده، معادلات سیستم و Vo قرار داده شده است. مقدار Vo مطلوب در شماره 2 قرار دارد. شماره 3 بلوک کنترلر PID است که ضرایب آن با ابزار PID tune متلب تعیین شده اند. قسمت شماره 4 نیز بلوک اشباع کننده است که نمی گذارد مقدار duty cycle از 0.1 کم تر و یا از 0.9 بیشتر شود (طبق مقاله).
نتایج شبیه سازی با متلب
تعداد تکرار محاسبات توسط متغیر iter در فایل inputs تعیین می گردد. این متغیر برابر 10 قرار داده شده تا سریعتر به جواب برسیم (پیشنهاد میشود مقدار را برابر 100 قرار دهید). با افزایش آن می توانید گام زمانی را کاهش داده و در نتیجه دقت را بالا ببرید. نتایج برای حالتهای مختلف در ادامه آورده شده است:
- یادگیری تقویتی با تابع پاداش R1
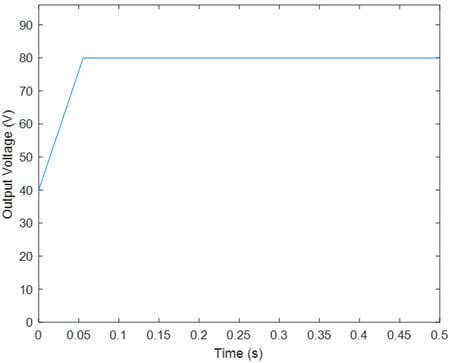
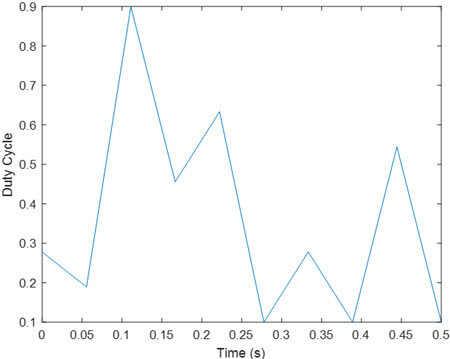
مشاهده مانند مقاله ولتاژ خروجی به مقدار مطلوب رسیده و duty cycle نیز در محدوده مجاز تغییر می نماید.
- یادگیری تقویتی با تابع پاداش R2
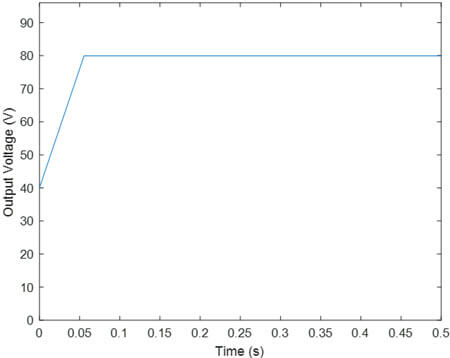
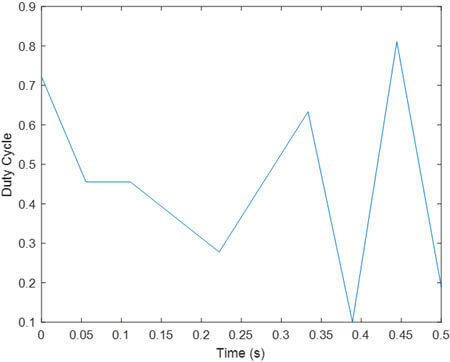
تحلیل نتایج مانند حالت قبل است.
- یادگیری تقویتی PR با تابع پاداش R1
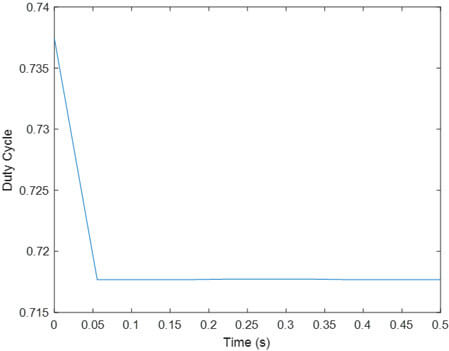
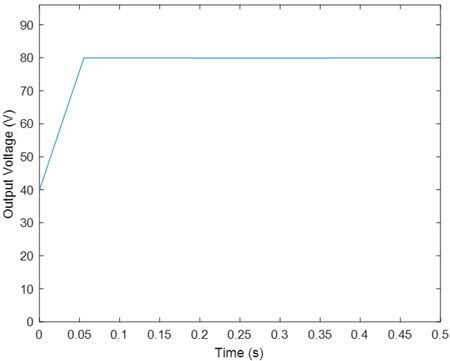
مجددا ملاحظه می شود ولتاژ خروجی به خوبی مقدار مرجع را تعقیب کرده و همچنین مانند مقاله تغییرات duty cycle کمتر است.
- یادگیری تقویتی PR با تابع پاداش R1
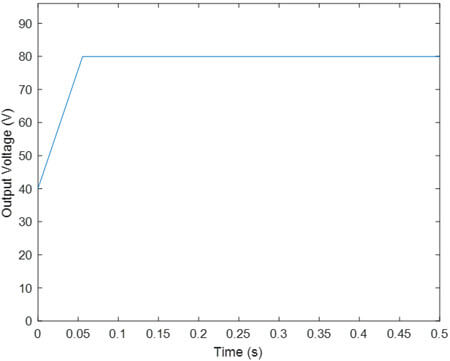
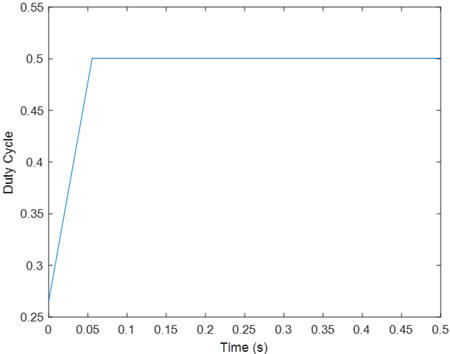
تحلیل نتایج مانند قبل است.
- یادگیری تقویتی VR با تابع پاداش R1
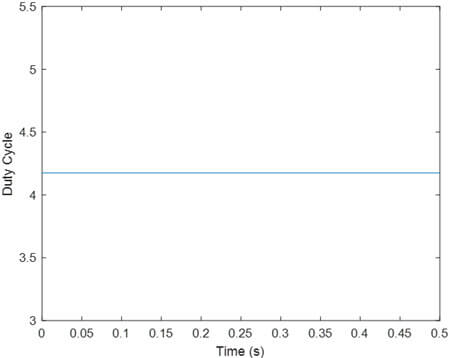
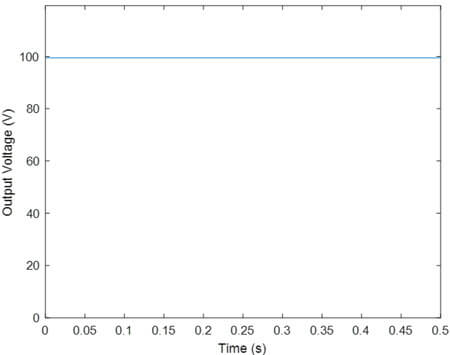
همانند مقاله در این جا نیز سیگنال مرجع تعقیب نشده است و روش PR عملکرد بهتری داشته است.
- یادگیری تقویتی با VR تابع پاداش R1
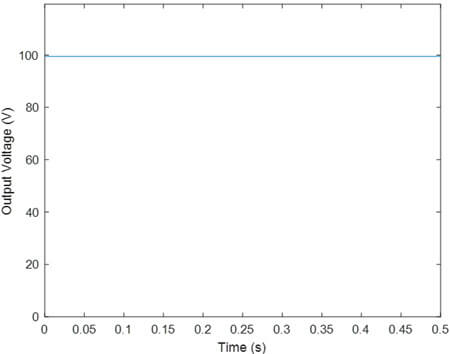
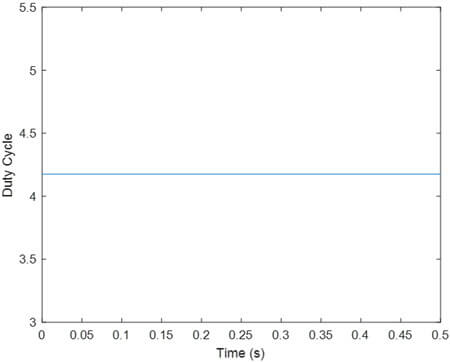
تحلیل نتایج مانند قبل است.
- کنترل PID
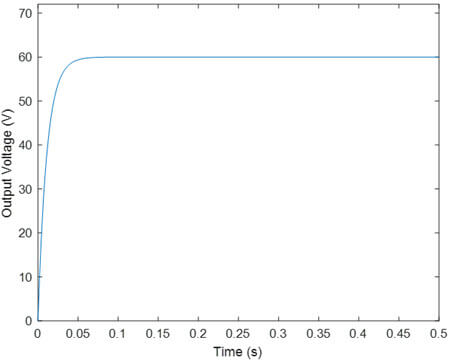
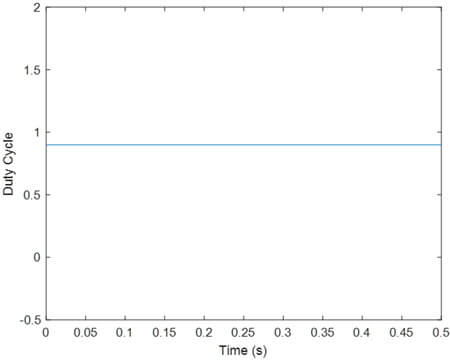
ملاحظه می شود به دلیل اعمال اشباع بر duty cycle، ولتاژ خروجی به مقدار مرجع نرسیده است.
کلیدواژه:
شبیه سازی
Nonlinear control of a boost converter using a robust regression based reinforcement learning algorithm
طبق توضیحات فوق توسط کارشناسان سایت متلبی تهیه شده است و به تعداد محدودی قابل فروش می باشد.
سفارش انجام پروژه مشابه
درصورتیکه این محصول دقیقا مطابق خواسته شما نمی باشد،.
با کلیک بر روی کلید زیر پروژه دلخواه خود را سفارش دهید.


دیدگاهها
هیچ دیدگاهی برای این محصول نوشته نشده است.