توضیحات
Discovering Interesting Rules from Biological Data Using Parallel Genetic Algorithm
گزارش پیاده سازی مقاله
مقدمه
در این مقاله سعی شده است یک روش استخراج قانون از یک مجموعه داده ارائه شود که بر اساس الگوریتم ژنتیک می باشد.
منظور از استخراج قانون بیرون آوردن رابطه بین ویژگی های موجود در یک مجموعه داده می باشد.
این قوانین دارای شکل کلی می باشند که در آنها X و Y دو زیرمجموعه از ویژگی ها می باشند که دارای اشتراک تهی هستند.
یکی از روش های مهم و پایه در این زمینه روش Apriori نام دارد که روش ارائه شده در این مقاله بر پایه این روش می باشد.
این روش دارای دو پارامتر می باشد که باید توسط کاربر مشخص شوند و الگوریتم به این دو پارامتر حساس می باشد.
این دو پارامتر به ترتیب minimum support و minimum confidence نام دارند.
Support یک قانون نشان دهنده این است که قانون مورد نظر چقدر در مجموعه داده گسترده است.
و می تواند موثر واقع شود و minimum support یک مقدار آستانه برای این مقدار می باشد.
میزان confidence یک قانون نیز نشان دهنده این مساله است که قانون مورد نظر در چند درصد مواقع با برقراری طرف اول رابطه طرف دوم را بدرستی پیش بینی می کند.
پارامتر minimum confidence یک مقدار آستانه برای این مقدار می باشد.
همانطور که اشاره شد اشکال روش پایه مجبور بودن کاربر برای تعیین دو پارامتر تعریف شده می باشد.
این مقاله این روش را طوری بهبود داده است که نیازی به این پارامترها نمی باشد.
روش پیشنهادی
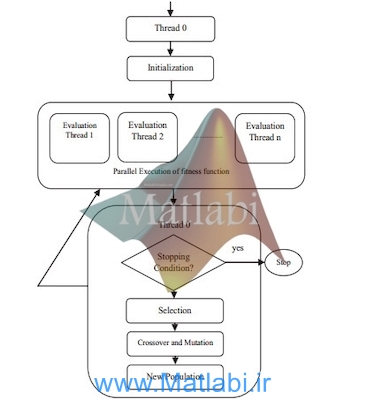
این روش بر اساس الگوریتم ژنتیک است که در عمل بصورت موازی اجرا می شود که در ادامه قسمت های مختلف آن اجرا می شود که شکل شماره 1 فلوچارت این روش را نشان می دهد.
همانطور که در این شکل مشاهده می کنید قسمت محاسبه تابع fitness می تواند بصورت موازی انجام شود زیرا این بخش برای هر فرد موجود در جمعیت مستقل از افراد دیگر می باشد.

شکل 1) فلوچارت الگوریتم
در این روش هر قانون به عنوان یک کروموزوم در نظر گرفته شده است.
مقاله ساختار قانون ها را بصورت سه مولفه ای در نظر گرفته است.
از این رو طول کروموزوم در واقع 3 می باشد که هر مولفه کروموزوم یک ویژگی از دیتاست و مقدار در نظر گرفته شده برای این ویژگی می باشد.
فایل اصلی برنامه با نام GA_RuleMining.m ذخیره شده است که در آن پارامترهای برنامه مشابه با گفته های مقاله مقدارگذاری می شود و سه تابع فراخوانی می شود.
تابع اول my_read_dataset نام دارد که دیتاست مورد استفاده را به داخل برنامه بارگذاری می کند.
تابع دوم my_GA_algorithm نام دارد و قسمت اصلی مقاله که یافتن قانون ها می باشد را انجام می دهد.
تابع سوم نیز my_accuracy_GA نام دارد که میزان کارایی قانون های استخراجی را محاسبه می کند و میزان دقت را نشان می دهد.
دیتاست مورد استفاده
دیتاست مورد استفاده مقاله Post-Operative Patient نام دارد که دارای 90 داده می باشد که متعلق به سه کلاس می باشند.
تعداد ویژگی های مجموعه داده 8 ویژگی می باشد که مقاله ویژگی 8 را حذف کرده است.
زیرا این ویژگی دارای تعدادی missing value بوده است.
بدنه اصلی برنامه متلب
تابع My_GA_algorithm فلوچارت نشان داده شده در شکل 1 را پیاده سازی می کند.
و به ترتیب بلاک های موجود در این فلوچارت را به عنوان تابع فراخوانی می کند.
در این تابع ابتدا تابع my_initialize_GA فراخوانی می شود که کارتولید تصادفی جمعیت اولیه را انجام می دهد و به این صورت کار می کند که از ابتدا یک فرد جامعه را بصورت تصادفی تولید کرده و سپس با اعمالmutatin های پیاپی جمعیت جامعه را تا حد مورد نیاز افزایش می دهد.
نتایج آزمایش ها
آزمایش ها بر روی مجموعه داده معرفی شده به ازای دو مقدار MaxLoop=200 و MaxLoop=5000 انجام شده است.
از آنجا که روش های تکاملی و ژنتیک در اجراهای مختلف جواب های متفاوتی از خود نشان می دهند برنامه برای هر مقدار MaxLoop به تعداد 5 بار اجرا شده و جواب ها در جدول زیر آورده شده است:
| MaxLoop=5000 | MaxLoop=200 | دقت | ||||
| کلاس 3 | کلاس 2 | کلاس 1 | کلاس 3 | کلاس 2 | کلاس 1 | |
| 88 | 82 | 80 | 46 | 45 | 40 | اجرای 1 |
| 85 | 86 | 80 | 47 | 48 | 44 | اجرای 2 |
| 81 | 90 | 78 | 50 | 44 | 42 | اجرای 3 |
| 82 | 88 | 83 | 49 | 46 | 47 | اجرای 4 |
| 82 | 85 | 77 | 44 | 43 | 45 | اجرای 5 |
کلید واژه : الگوریتم ژنتیک موازی,پروژه متلب,شبیه سازی با متلب,matlab project,پروژه های matlab,
شبیه سازی
Discovering Interesting Rules from Biological Data Using Parallel Genetic Algorithm
به تعداد محدودی قابل فروش می باشد.
سفارش انجام پروژه مشابه
درصورتیکه این محصول دقیقا مطابق خواسته شما نمی باشد،.
با کلیک بر روی کلید زیر پروژه دلخواه خود را سفارش دهید.




دیدگاهها
هیچ دیدگاهی برای این محصول نوشته نشده است.