
توضیحات
کنترل ردیابی مسیر بهینه تطبیقی AUV ها بر اساس یادگیری تقویتی
عنوان اصلی مقاله:
Adaptive optimal trajectory tracking control of AUVs based on reinforcement learning
شبیه سازی در محیط ام فایل متلب انجام شده است.
ترجمه مقدمه مقاله:
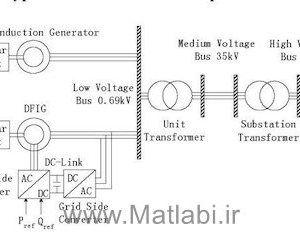
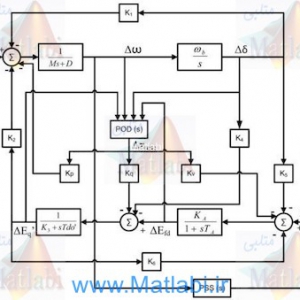
در این مقاله، یک طرح کنترل شبکه عصبی (NN) یادگیری تقویتی بهینه بدون مدل تطبیقی (RL) بر اساس خطای فیلتر برای مشکل کنترل ردیابی مسیر یک وسیله نقلیه زیرآبی خودگردان (AUV)با اشباع ورودی پیشنهاد شده است. به طور کلی، کنترل بهینه با حل معادله همیلتون-جاکوبی-بلمن (HJB) محقق می شود. با این حال، به دلیل غیرخطی بودن و پیچیدگی ذاتی آن، حل معادله HJB دینامیک AUV چالش برانگیز است. برای مقابله با این مشکل، یک استراتژی RL مبتنی بر یک چارچوب بازیگر-نقد برای تقریب حل معادله HJB، که در آن NN های بازیگر و منتقد به ترتیب برای انجام رفتار کنترل و ارزیابی عملکرد کنترل استفاده می شوند، پیشنهاد شده است. علاوه بر این، برای سیستم AUV با مدل دینامیکی فیدبک مرتبه دوم، روش طراحی کنترلکننده بهینه بر اساس خطاهای فیلتر برای اولین بار برای سادهسازی طراحی کنترلکننده و تسریع سرعت پاسخدهی سیستم پیشنهاد شده است. سپس، برای حل مسئله وابسته به مدل، یک ناظر حالت توسعه یافته (ESO) برای تخمین دینامیک غیرخطی مجهول و یک قانون تطبیقی برای تخمین پارامترهای مدل مجهول طراحی شده است. برای مقابله با اشباع ورودی، از یک سیستم متغیر کمکی در قانون کنترل استفاده می شود. تجزیه و تحلیل دقیق لیاپانوف تضمین می کند که تمام سیگنال های سیستم به صورت نیمه جهانی به طور یکنواخت در نهایت محدود می شوند (SGUUB). در نهایت، برتری روش پیشنهادی با آزمایشهای مقایسهای تأیید میشود.
توضیحات پروژه کنترل ردیابی مسیر بهینه تطبیقی زیر دریایی ها
شبیه سازی روش مقاله انجام شده است, همانطور که در مقاله مشخص هست, نتیجه روش مربوطه با سایر روش های دیگر مقایسه شده است. در این پروژه روش های مقایسه ای دیگر انجام نشده است.
این پروژه دارای گزارش نیست و فقط نتایج بدست آمده از شبیه سازی در قالب ورد تهیه شده است.
در زیر نتایج شبیه سازی با متلب را مشاهده می کنید:

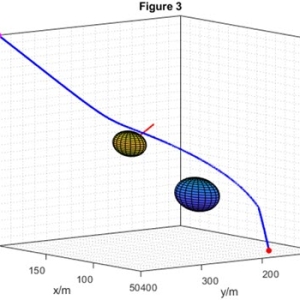
Fig. 2. Desired and actual trajectories of the AUV

Fig. 3. Tracking error of the AUV

Fig. 4. Tracking error derivative of the AUV

Fig. 5. Comprehensive tracking error z

Fig. 6. Desired and actual state in vx, vy and vz

Fig. 7. The control input δ of the proposed method.

Fig. 8. Norms of actor and critic NNs weights

Fig. 9. Approximation cost function Jˆ∗(s˘).

Fig. 10. Bellman error ec or HJB equation H(s˘, δm, Wˆ )

Fig. 11. Comprehensive tracking error z with sensor noise.
شاید به موارد زیر نیز علاقه مند باشید:
- تخمین فیلتر کالمن مقاوم از زیردریایی مستقل در حضور خطاهای حسگر
-
کنترل بهینه مبتنی بر یادگیری تقویتی برای سیستم غیرخطی محدود از طریق یک تبدیل جدید وابسته به حالت
- کنترل مشارکتی بهینه با استفاده از یادگیری تقویتی ساده شده برای دسته ای از سیستم های چند عاملی با دینامیک ناشناخته
- کنترل غیرخطی مبدل تقویت کننده با استفاده از الگوریتم یادگیری تقویتی مبتنی بر رگرسیون قوی
- افزایش دقت ردیابی مسیر برای ربات صنعتی با کنترل تطبیقی مقاوم
کلیدواژه:
Reinforcement learning (RL), Optimal control, Neural networks (NNs), Autonomous underwater vehicle (AUV), Input saturation
یادگیری تقویتی (RL), کنترل بهینه, شبکه های عصبی (NN), زیر دریایی (AUV), اشباع ورودی
کنترل ردیابی مسیر بهینه تطبیقی زیر دریایی ها بر اساس یادگیری تقویتی با متلب
طبق توضیحات فوق توسط کارشناسان سایت متلبی تهیه شده است و به تعداد محدودی قابل فروش می باشد.
سفارش انجام پروژه مشابه
درصورتیکه این محصول دقیقا مطابق خواسته شما نمی باشد،.
با کلیک بر روی کلید زیر پروژه دلخواه خود را سفارش دهید.


دیدگاهها
هیچ دیدگاهی برای این محصول نوشته نشده است.