توضیحات
A Novel Ensemble Method for Classifying Imbalanced Data
یک روش جدید برای طبقه بندی گروهی داده های نامتوازن
3. روش ارائه شده
3.1. بررسی اجمالی از روش
بسیاری از الگوریتم های طبقه بندی سنتی عملکرد ضعیفی برای داده های نا متعادل نشان داده اند. [11،13، 16].
bagging یک نوع روش آموزش گروهی است که می تواند این مشکل را با آموزش گروهی حل کند اگر طبقه بندی بر پایه دقت و تنوع باشد [27].
با این وجود برای هر طبقه بندی پایه در bagging ، در هنگام مواجهه با داده های نامتوازن ، که نمونه های آن مربوط به کلاس های نا متوازن است دارای عملکرد مناسبی نیست.
برای حل این مشکل برخی از روش های نمونه گیری خاص با bagging ترکیب شده اند. از جمله UnderBagging ،OverBagging و [73] SMOTEBagging.
این روش مبنتی بر bagging ابتدا برای تعادل داده ها برای هر طبقه بندی پایه استفاده شد و سپس نتایج طبقه بندی این طبقه پایه با قوانین گروهی خاص ترکیب شد.
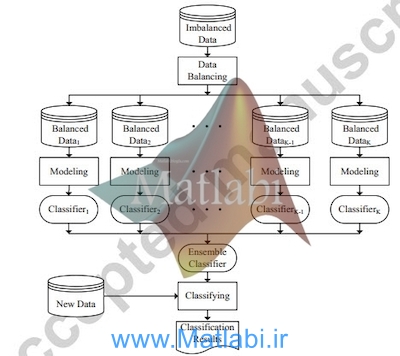
روش پیشنهادی ما برای مقابله با مشکل عدم تعادل کلاس ها،هر کلاس نامتعادل را به چندین کلاس متعادل تبدیل میکند که شامل سه جزء است: تعادل داده ، مدل سازی و طبقه بندی.
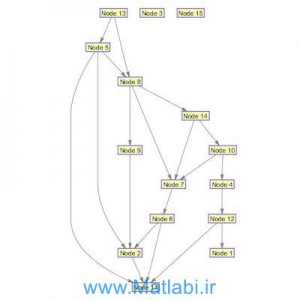
شکل. 1 جزئیات روش را نشان می دهد.

در روش ما، نمونه های کلاس اکثریت ابتدا به چند قسمت تقسیم شده است.
هر قسمت دارای تعداد نمونه برابربا کلاس اقلیت است و با نمونه های کلاس اقلیت ترکیب شده است.
بنابراین چند مجموعه داده متعادلا به دست آمده (داده متعادل).
پس از آن، هر یک از مجموعه داده های متعادل برای ساخت یک طبقه بندی دودویی با یک الگوریتم یادگیری خاص استفاده می شود (مدلسازی).
در نهایت، این طبقه دودویی به یک طبقه بندی گروهی برای طبقه بندی اطلاعات جدید ترکیب می شود (طبقه بندی).
3.2. بالانس داده
داده های باینری نا متعادل الگوریتم های یادگیری طبقه بندی سنتی را به خطر می اندازد ، و طبقه اقلیت معمولا با این الگوریتم ها به صورت نادرست طبقه بندی می شوند.
هنگامی از خوشه بندی به عنوان روش تعادل داده ها استفاده می شود، یک الگوریتم خوشه خاص ابتدا به نمونه های کلاس اکثریت اعمال می شود و خوشه های متعدد به دست می آید.
در نهایت، هر یک از این خوشه با کلاس اقلیت ترکیب شده ، بنابراین داده های جدید و متعادل ساخته می شود.
3.3. طبقه بندی
پس از مدل سازی، طبقه بندی های متعدد می تواند با داده های متعدد متعادل به دست آمده از داده کننده ساخته شده است.
توضیح کد متلب
فایل program.m
clc;
clear all;
close all;
در این قسمت از برنامه تمام پنجره های باز در نرم افزار متلب بسته شده و محیط command window پاک شده و نرم افزار برای نوشتن برنامه جدید آماده می شود.
input_data = importdata(‘input.txt’);
Train = input_data(1:floor(.8*size(input_data,1)) , :) ;
Test = input_data(floor(.8*size(input_data,1))+1 : size(input_data,1) , :) ;
N_class = class(Train);
دیتاست مورد نظر خوانده شده و به دو قست تستی و آموزش تبدیل می شود (80 درصد برای آموزش و 20 درصد برای تست).
هر دیتاستی که به برنامه داده می شود باید ببه فرمت .txt بوده و ستون آخر کلاس هر نمونه را (به صورت عدد) نشان دهد.
سپس تابع class فراخوانی می شود که در ادامه توضیح داده می شود.
balans_data = Balansing_Data(N_class , Train);
بخشی از کد اینجا آمده و برای دریافت پروژه باید این محصول خریداری شود.
تابع class:
…
در این تابع تعداد نمونه های هر کلاس محاسبه شده و در output ذخیره می شود.
تابع balansing_data
…
در این تابع تعداد نمونه های کلاس اقلیت در min_number ذخیره می شود.
سپس داده های کلاس دیگر به گونه ای خوشه بندی می شوند که در هر کلاس min_number خوشه وجود داشته باشد.
در نهایت از هر خوشه یک نمونه انتخاب شده و در خروجی ذخیر می شود.
پس از اجرای این الگوریتم داده ها متعادل شده و از هر کلاس به تعداد min_number نمونه خواهیم داشت.
نتایج به دست آمده از شبیه سازی با متلب
Left column is my result —- Right column is correct
ans =
-1 -1
1 -1
-1 -1
-1 -1
-1 -1
-1 -1
-1 -1
-1 -1
-1 -1
-1 -1
-1 -1
-1 -1
….
قسمتی از جواب اینجا آمده که به صورت فوق است.
کلید واژه : الگوریتم های طبقه بندی, الگوریتم های یادگیری, خوشه بندی ,پروژه متلب,شبیه سازی با متلب,matlab project,پروژه matlab,پروژه های آماده متلب,
Imbalanced data, classification, ensemble learning
شبیه سازی مقاله
A Novel Ensemble Method for Classifying Imbalanced Data
به تعداد محدودی قابل فروش می باشد.
سفارش انجام پروژه مشابه
درصورتیکه این محصول دقیقا مطابق خواسته شما نمی باشد،. با کلیک بر روی کلید زیر پروژه دلخواه خود را سفارش دهید.