
توضیحات
اتوماتای یادگیر
طراحی خودرو هوشمند که از موانع بتواند عبور کند و خود را به مکان خروج برساند.
Maze چیست؟ و تاریخچه آن
کلمه maze کلمه ای مشخص و دارای ریشه نیست و معمولاً به معنی سرگیجه و سردرگمی استفاده می شود.
این کلمه به جای لابیرنت توسط افرادی استفاده می شود که از تاریخچه لابیرنت و از این افسانه یونانی بی خبرند.
پس در واقع تفاوتی بین لابیرنت(Labyrinth) و ماز (maze) نیست و فقط در استفاده از سرگرمی های روز و مدرن کلمه maze و در مورد ریشه این سرگرمی کلمه لابیرنت استفاده می شود.
حتی در مصر باستان نیز از این طرح یعنی طرح لابیرنت برای معماری استفاده می کردند.
امروزه این افسانه و الگوی معماری به سرگرمی فکری تبدیل شده و حتی بازی های رایانه ای با گرافیک قابل توجهی با استفاده از آن ساخته می شود.
البته هنوز هم در معماری از این طرح استفاده های شایانی می شود و همچنین برای ساخت ربات های مختلف با کاربردهای متنوع استفاده میشود.
MAZE یک ساختار پیچیده با مجموعه ای از مسیرهای متصل است.
این اصطلاح همچنین برای اشاره به یک پازل گرافیکی است که پیچ و خم ها بر روی یک رسانه دو بعدی تکرار شده مورد استفاده قرار گیرد و برای حل آن باید راهی از ورود به خروجی، و یا محل دیگری پیدا کنند که می توانند خیلی پیچیده باشند برای همین استفاده از این کلمه به عنوان یک اصطلاح عامیانه برای یک فرایند پیچیده منجر شده است.
عمل ساخت و حل مارپیچها قرنها قدمت دارد و حفریات باستان شناسی در بسیاری از کشورها نشان داده اثری از مارپیچهای ساخته شده توسط مردم در سراسر جهان، از امریکا لاتین تا یونان وجود دارد که در بعضی مواقع به عنوان یک تجربه دینی، و یا آن را عنوان یک چالش هیجان انگیز می ساختند و در طول تاریخ بسیاری از مکان ها مانند باغ هجز و کلیساهای گوتیک اروپا ، hilltops، جزایر سواحل در کشورهای اسکاندیناوی و …. طراحی و ساخته شده است.
همچنین نماد Labyrinth در سراسر هند، سوماترا و جاوا و در جنوب غربی آمریکا، یافت می شود.
نکته ای که باید به آن اشاره کرد امروزه بین لایبرنت و ماز یک تفاوت اندکی بوجود آمده است لایبرنت یک ساختار مشابه است، که یک مسیر روشن و آسان برای دنبال کردن دارد.
هدف لایبرنت وادار کردن به تفکر و اندیشه با هدایت مسیرهای آن می باشد. لایبرنت همچنین دارای سابقه ای طولانی، ودر مراسم های مذهبی مورد استفاده قرارمی گرفت.
پیچش و چرخش از لایبرنت به دقت انتخاب میشدند و گاهی برای ارسال یک پیام مورد استفاده قرار میگرفت وقتی که از بالا به آنها نگاه می کردند به مفهوم پیام پی می بردند.
اما Maze ها سه بعدی و تقریبا از هر چیزی ساخته شده است مثلا در باغ ها از پرچین ها، درختان و گیاهان استفاده شده و حتی مارپیچهای باغ در بسیاری از موارد با ارتفاع کم ساخت شده است که اجازه می دهد مردم آنها را ببینند ونهاآنآ«ها برای ایجاد یک Maze، آجر، سنگ، چوب، و مواد دیگر نیز می توانست مورد استفاده قرار گیرد.
الگوریتم های حل مسئله Maze
الگوریتم های متفاوتی برای حل مسأله مارپیچ وجود دارد که تمامی آنها روش های تمام خودکاری برای حل مساله مارپیچ هستند.
در ادامه این مقاله چند الگوریتم حل این مساله معرفی خواهند شد.
الگوریتم های موشی و دنبال کننده دیوار و الگوریتم تضمین کننده و همچنین الگوریتمی به نام ترماکس برای روبات هایی بدون دانش قبلی از توپولوژی مارپیچ استفاده میشوند.
از طرف دیگر الگوریتم های بن بست و کوتاه ترین مسیر برای استفاده برنامه های رایانه ای و همچنین استفاده انسان ها به کار میروند که به کمک این روش ها میتوان دید کلی از توپولوژی الگوریتم ها بدست آورد.
نکته: مارپیچ استاندارد و یا کامل به مارپیچی گفته میشود که دور نداشته باشد و معادل یک درخت در نظریه گراف ها میباشد.
بسیاری از راه حل های حل مساله مارپیچ به نظریه گراف نزدیکند به طوری که با یک تبدیل مناسب از مسیر ها به یالهای گراف میتوان یک گراف را از یک صفحه مارپیچ استخراج کرد.
چند نوع الگوریتم برای حل ماز وجود دارد از جمله:
1. الگوریتم دنبال کردن دیواره ها (wall follower)
یکی از سادهترین الگوریتمها دنبال کردن دیوار هست.
برای به کار بردن این الگوریتم، ربات احتیاجی به استفاده از حافظه ندارد.
در این الگوریتم کافی است دست راست یا چپ خود را به دیواره بگیرید و بدون این که دست از دیوار جدا شود، به مسیر ادامه دهید.
این الگوریتم بهترین روش پیمودن ماز است، اگر ماز ساده باشد، یعنی همه ی دیواره ها به یکدیگر یا فضای بیرونی ماز متصل باشند، این تضمین وجود دارد که با حفظ تماس یک دست به دیواره ای که از آن شروع به حرکت می کنیم، بتوان از ماز خارج شد. ولی اگر ماز ساده نباشد، این الگوریتم به یافتن خروجی در قسمت های گسسته کمکی نمی کند.
در مازهایی که هدف در وسط قرار دارد و بخشی از دیواره ی هدف را پوشش داده است، کاربردی ندارد.
الگوریتم دنبال کردن دیواره ها در مازهای سه بعدی نیز عملی است. مثلا در یک ماز سه بعدی مسیر های رو به بالا می توانند شمال غرب و مسیرهای رو به پایین جنوب شرق فرض شوند و می توان با روش دنبال کردن دیواره ها به نتیجه رسید.
۲. الگوریتم جستجوی تصادفی
این الگوریتم یک روش ضعیف است که به وسیله ی ربات های غیر هوشمند یا موش قابل اجراست، اما تضمینی برای رسیدن به هدف وجود ندارد.
در این الگوریتم یک مسیر مستقیم طی می شود تا به اولین مانع برسد، سپس یک مسیر تصادفی (چپ یا راست) را برای ادامه انتخاب می کند.
این الگوریتم در صورتی که خروجی به صورت یک سوراخ در میانه ی دیوار باشد، با شکست مواجه می شود.
این روش زمان بر است و ممکن است هیچوقت به نتیجه نرسد.
۳. الگوریتم Pledge
ماز های گسسته را می توان به روش دنبال کردن دیواه ها حل کرد، در صورتی که ورودی و خروجی ماز روی دیواره های خارجی ماز قرار داشته باشد.
چنانچه از درون ماز شروع به حرکت کنیم، ممکن است الگوریتم دنبال کردن دیواره ها در قسمت گسسته ای که شامل خروجی نیست دائما یک حلقه را طی کند. الگوریتم Pledge می تواند این گونه مسائل را حل کند.
این الگوریتم برای رفع موانع، به طی یک مسیر اختیاری نیاز دارد.
هنگام مواجهه با مانع، یک دست (مثلا دست راست) را در امتداد مانع نگه می داریم در حالیکه زوایای چرخش شمرده می شود.
وقتی دوباره در راستای مسیر اصلی قرار گرفتیم و جمع زاویه ای چرخش ها برابر صفر شد، می توان مانع را ترک کرد و در راستای مسیر اصلی حرکت نمود.
این الگوریتم به شخص اجازه ی جهت یابی در شروع از هر نقطه برای خروج از مازهای دوبعدی را می دهد.
4. الگوریتم Tremaux
الگوریتم ترماکس توسط چارلز پیر ترماکس به عنوان یک الگوریتم کار آمد برای تشخیص راه حل یک مارپیچ با استفاده از نشانه گذاری مسیر پیموده شده درون یک صفحه مارپیچ میباشد.
در این روش یک مسیر یا علامت نخورده است یا یک بار علامت خورده و یا دو بار علامت زده شده است.
در ابتدای کار یک مسیر دلخواه انتخاب شده و هنگامی که به یک انشعاب که در گذشته علامت نخورده است میرسیم آن را علامت میزنیم و یک مسیر دلخواه دیگر را انتخاب میکنیم اما اگر به یک انشعاب علامت خورده رسیدیم مسیر آمده را در صورتی که تنها یک بار علامت خورده باشد بر میگیردیم و آن را دوباره علامت میزنیم.
در حقیقت همواره مسیری که کمترین علامت را خورده باشد انتخاب میکنیم.هنگامی که نقطه مقصد علامت میخورد جواب مساله مسیری است که تنها یک بار علامت خورده باشد.
این الگوریتم در حقیقت یک نتیجه از الگوریتم جستجوی عمق اول میباشد.
۵. الگوریتم recursive back tracker
یک الگوریتم بازگشتی است و یکی از معروفترین الگوریتم های حل ماز است، در این الگوریتم هر مسیری که طی میشود علامتگذاری شده و وقتی روبات از مسیرهای علامت گذاری شده عبور میکند علامت ها را پاک می کند.
در نهایت پس از طی مسیرهای مختلف و رفت و برگشت ها، یک مسیر باقی می ماند که همان مسیر اصلی است و به حل ماز می انجامد.
6. روش maping
در حقیقت یه جور نقشه برداری از محیط هست. روش کار اینطوری است که مثلاً ماز را به شکل مجموعهای از دایرهها در نظر می گیریم و موقعیت دیوارها و مکانهایی که ربات طی کرده را ثبت می کنیم.
7. الگوریتم shortest path finder
این الگوریتم، کوتاهترین مسیر را انتخاب می کند و دارای برخی محدودیت ها برای مسیریابی است.
برای استفاده از این الگوریتم، یا باید یک نمونه از نقشه ی مسیر ماز در حافظه ی ربات وجود داشته باشد و یا باید از سیستم علامت گذاری در آن استفاده کرد.
8. الگوریتم daed end filler
در این الگوریتم، به جز تقاطع های ماز، مسیرهای اشتباه حذف میشود و در نهایت مسیر صحیح باقی می ماند که باید طی شود.
9- الگوریتم Bellman Flooding
خلاصه اي از طرز کار الگوریتم مرکز یابی Bellman Flooding بدین شکل است که در لحظه شروع یک جدول مقدار دهی اولیه می شود، سپس طی یک سري محاسبات جهت حرکت روبوت تعیین می شود و روبوت به آن سمت حرکت می کند و پس از کشف هدف (یعنی مرکز زمین) خود را براي برگشتن آماده می کندو پس از این که چند بار زمین را جستجو می کند کوتاه ترین مسیر ممکن را پیدا می کند و به طور مداوم از آن مسیر، خود را از مبدا به مقصد می رساند تا به بهترین زمان اجراي ممکن دست یابد.
10- الگوریتم تضمین کننده
برای صفحه مارپیچ های نا پیوسته نیز میتوان از الگوریتم دنبال کننده دیوار استفاده کرد به شرط اینکه اگر درگاه های ورود و خروج به مارپیچ در دیواره بیرونی یک حلقه قرار داشته باشند.
اما اگر به طور مثال نقطه شروع در داخل صفحه باشد و دیوار های صفحه مارپیچ دارای ناپیوستگی بوده و به چند بخش تقسیم شده باشند.
در این صورت به طور دایمی به دور خود خواهیم گشت.الگوریتم تضمینی این مشکل را حل خواهد کرد.
الگوریتم تضمینی به طوری طراحی شده است که موانع احتمالی را پیش بینی میکند.
انجام پروژه متلب با مجریان حرفه ای سایت متلبی
این الگوریتم یک جهت دلخواه حرکت را انتخاب میکند سپس به صورت مستقیم به جهت انتخاب شده حرکت میکند.
هنگامی که به یک مانع رسید یک دست را به طور ثابت به دیواره مانع گرفته و حرکت میکنیم و به ازای تمام چرخش ها زاویه ای که چرخیده ایم به مجموع زوایای چرخش اضافه میکنیم و هنگامی که به زاویه حرکت اولیه بازگشتیم یعنی مجموع چرخش ها به صفر رسید یعنی به مسیر اصلی برگشته و مانع را دور زده ایم و به جهت دلخواه انتخابی ادامه مسیر میدهیم.
در این الگوریتم هنگامی دست را از دیوار بر میداریم که زاویه چرخش برابر صفر شده باشد
(مجموع زوایای چرخش برای گرفتن دیوار و مجوع زوایای چرخش در حین دنبال کردن دیوار).
این شگرد این امکان را به الگوریتم میدهد که در مسیر هایی مانند “G” گیر نکند. اگر الگوریتم ۳۶۰ درجه با دست چسبیده به دیوار حرکت کند یعنی این که در یک دایره افتاده است که اگر در پیاده سازی الگوریتم این حالت در نظر گرفته نشده باشد در دور بی نهات خواهد افتاد و باید الگوریتم بعد از اتفاق افتادن چرخش ۳۶۰ درجه با عوض کردن دست اجرا شود.
این الگوریتم قابلیت اجرا از هر نقطه درونی داخل صفحه مارپیچ را داراست.
اما قابلیت اجرا برای حالاتی که نقطه شروع خارج صفحه باشد اما نقطه پایان داخل صفحه را دارا نیست.
11- الگوریتم بن بست

مثالی از یک مارپیچ با تعداد زیادی جواب که الگوریتم بن بست برای آن جواب خوبی نمیدهد و بهتر است از الگوریتم کوتاه ترین مسیر استفاده کنیم.
این الگوریتم برای مواقعی که میتوان تمام صفحه مارپیچ را یکجا دید مناسب است بنابراین برای مواقعی که مارپیچ بر روی کاغذ است و یا توسط رایانه قصد حل آن را داریم مناسب است.
روش کلی کار این روش این است که بن بست ها را پیدا کرده و از یک بن بست تا اولین انشعاب را پر میکند.
این الگوریتم به صورت مرحله به مرحله مسیر را به ما نمیدهد و باید برای تمام بن بست ها اجرا شود و مسیر هایی که در نهایت پر نشده اند نشان دهنده جواب هستند.
در صورتی که مارپیچ ما دور نداشته باشد جواب یکتا به ما داده اما در صورت وجود دور مسیر هایی که جزو حداقل یک جواب هستند نشان میدهد.
12- الگوریتم کوتاه ترین مسیر
هنگامی که یک مارپیچ دارای تعداد زیادی جواب باشد انتخاب مناسب انتخابی است که کوتاهترین مسیر میان ابتدا تا انتها را به کاربر بدهد.
این الگوریتم از جستجوی اول سطح استفاده میکند ولی الگوریتم جستجو A* از روش های اکتشافی استفاده میکنند.
الگوریتم جستجوی سطح اول از یک صف برای ملاقات خانه ها به ترتیب افزایشی استفاده میکند.
به طوری که به هر خانه ای که میرسد کوتاه ترین فاصله تا مبدا را در خود نگه میدارد و این کوتاه ترین فاصله از فاصله خانه های کناری به دست می آید.
هنگامی که به خانه مقصد رسیدیم مسیر مناسب برابر بازگشت از مسیر طی شده به مقصد است.
البته الگوریتم های دیگری نیز برای حل این مسائل وجود دارد.
یادگیری در Maze
یادگیری ماشینی:
به عنوان یکی از شاخههای وسیع و پرکاربرد هوش مصنوعی، یادگیری ماشینی (Machine learning) به تنظیم و اکتشاف شیوهها و الگوریتمهایی میپردازد که بر اساس آنها رایانهها و سامانهها توانایی تعلٌم و یادگیری پیدا میکنند.
اهداف و انگیزهها
هدف یادگیری ماشینی این است که کامپیوتر (در کلیترین مفهوم آن) بتواند به تدریج و با افزایش دادهها بازدهی بالاتری در وظیفهی مورد نظر پیدا کند.
گستردهی این وظیفه میتواند از تشخیص خودکار چهره با دیدن چند نمونه از چهرهی مورد نظر تا فراگیری شیوهی گامبرداری برای روباتهای دوپا با دریافت سیگنال پاداش و تنبیه باشد.
طیف پژوهشهایی که در یادگیری ماشینی میشود گستردهاست.
و از سویی پژوهشگران بر آناند که روشهای یادگیری تازهای به وجود بیاورند و امکانپذیری و کیفیت یادگیری را برای روشهایشان مطالعه کنند و در سوی دیگر عدهای از پژوهشگران سعی میکنند روشهای یادگیری ماشینی را بر مسایل تازهای اعمال کنند. البته این طیف گسسته نیست و پژوهشهای انجامشده دارای مولفههایی از هر دو رویکرد هست.
انواع روش های یادگیری ماشین
یکی از تقسیمبندیهای متداول در یادگیری ماشینی، تقسیمبندی بر اساس نوع دادههای در اختیار عامل هوشمند است.
به سناریوی زیر توجه کنید:فرض کنید به تازگی رباتای سگنما خریدهاید که میتواند توسط دوربین هاای دنیای خارج را مشاهده کند، به کمک میکروفنهایاش صداها را بشنود، با بلندگوهایی با شما سخن بگوید (گیریم محدود) و چهارپایااش را حرکت دهد.
همچنین در جعبهی این ربات دستگاه کنترل از راه دوری وجود دارد که میتوانید انواع مختلف دستورها را به ربات بدهید.
یادگیری بانظارت
اولین کاری که میخواهید بکنید این است که اگر ربات شما را دید خرناسه بکشد اما اگر غریبهای را مشاهده کرد با صدای بلند عوعو کند.
فعلاً فرض میکنیم که ربات توانایی تولید آن صداها را دارد اما هنوز چهرهی شما را یاد نگرفتهاست.
پس کاری که میکنید این است که جلوی چشمهایاش قرار میگیرید و به کمک کنترل از راه دورتان به او دستور میدهید که چهرهای که جلویاش میبیند را با خرناسهکشیدن مربوط کند.
اینکار را برای چند زاویهی مختلف از صورتتان انجام میدهید تا مطمئن باشید که ربات در صورتی که شما را از مثلاً نیمرخ ببیند به شما عوعو نکند.
همچنین شما چند چهرهی غریبه نیز به او نشان میدهید و چهرهی غریبه را با دستور عوعوکردن مشخص میکنید.
در این حالت شما به کامپیوتر ربات گفتهاید که چه ورودیای را به چه خروجیای مربوط کند. دقت کنید که هم ورودی و هم خروجی مشخص است و در اصطلاح خروجی برچسبدار است.
به این شیوهی یادگیری، یادگیری بانظارت میگویند.
یادگیری تقویتی
اینک حالت دیگری را فرض کنید.
برخلاف دفعهی پیشین که به رباتتان میگفتید چه محرکای را به چه خروجیای ربط دهد، اینبار میخواهید ربات خودش چنین چیزی را یاد بگیرد.
به این صورت که اگر شما را دید و خرناسه کشید به نحوی به او پاداش دهید (مثلاً به کمک همان کنترل از راه دورتان) و اگر به اشتباه به شما عوعو کرد، او را تنبیه کنید (باز هم با همان کنترل از راه دورتان).
در این حالت به ربات نمیگویید به ازای هر شرایطی چه کاری مناسب است، بلکه اجازه میدهید ربات خود کاوش کند و تنها شما نتیجهی نهایی را تشویق یا تنبیه میکنید.
به این شیوهی یادگیری، یادگیری تقویتی میگویند.
یادگیری بی نظارت
در دو حالت پیش قرار بود ربات ورودیای را به خروجیای مرتبط کند.
اما گاهی وقتها تنها میخواهیم ربات بتواند تشخیص دهد که آنچه میبیند (یا میشنود و…) را به نوعی به آنچه پیشتر دیدهاست ربط دهد بدون اینکه به طور مشخص بداند آنچیزی که دیده شدهاست چه چیزی است یا اینکه چه کاری در موقع دیدناش باید انجام دهد.
ربات هوشمند شما باید بتواند بین صندلی و انسان تفاوت قایل شود بیآنکه به او بگوییم این نمونهها صندلیاند و آن نمونههای دیگر انسان.
در اینجا برخلاف یادگیری بانظارت هدف ارتباط ورودی و خروجی نیست، بلکه تنها دستهبندیی آنها است. شبیه سازی با متلب
این نوع یادگیری که به آن یادگیری بی نظارت می گویند بسیار مهم است چون دنیای ربات پر از ورودیهایی است که کسای برچسبای به آنها اختصاص نداده اما به وضوح جزیی از یک دسته هستند.
یادگیری بینظارت را میتوان به صورت عمل کاهش بعد در نظر گرفت.
یادگیری نیمه نظارتی
از آنجا که شما سرتان شلوغ است، در نتیجه در روز فقط میتوانید مدت محدودی با رباتتان بازی کنید و به او چیزها را نشان دهید و نامشان را بگویید (برچسبگذاری کنید).
اما ربات در طول روز روشن است و دادههای بسیاری را دریافت میکند.
در اینجا ربات میتواند هم به خودیی خود و بدون نظارت یاد بگیرد و هم اینکه هنگامی که شما او را راهنمایی میکنید، سعی کند از آن تجارب شخصیاش استفاده کند و از آموزش شما بهرهی بیشتری ببرد.
ترکیباتی که عامل هوشمند هم از دادههای بدون برچسب و هم از دادههای با برچسب استفاده میکند یادگیری نیمه نظارتی میگویند.
تفاوت روش ها
یادگیری تحت نظارت، یک روش عمومی در یادگیری ماشین است که در آن به یک سیستم، مجموعه ای از جفتهای ورودی – خروجی ارائه شده و سیستم تلاش میکند تا تابعی از ورودی به خروجی را فرا گیرد.
یادگیری تحت نظارت نیازمند تعدادی داده ورودی به منظور آموزش سیستم است.
با این حال ردهای از مسائل وجود دارند که خروجی مناسب که یک سیستم یادگیری تحت نظارت نیازمند آن است، برای آنها موجود نیست.
این نوع از مسائل چندان قابل جوابگویی با استفاده از یادگیری تحت نظارت نیستند. یادگیری تقویتی مدلی برای مسائلی از این قبیل فراهم میآورد.
در یادگیری تقویتی، سیستم تلاش میکند تا تقابلات خود با یک محیط پویا را از طریق آزمون و خطا بهینه نماید.
یادگیری تقویتی مسئلهای است که یک عامل که میبایست رفتار خود را از طریق تعاملات آزمون و خطا با یک محیط پویا فرا گیرد، با آن مواجه است.
در یادگیری تقویتی هیچ نوع زوج ورودی- خروجی ارائه نمیشود.
به جای آن، پس از اتخاذ یک عمل، حالت بعدی و پاداش بلافصل به عامل ارائه میشود.
هدف اولیه برنامهریزی عاملها با استفاده از تنبیه و تشویق است بدون آنکه ذکری از چگونگی انجام وظیفه آنها شود.
يادگيری تحت سرپرستی، يک روش عمومی در يادگيری ماشين است که در آن به يک سيستم، مجموعه جفتهای ورودی – خروجی ارائه شده و سيستم تلاش میکند تا تابعی از ورودی به خروجی را فرا گيرد. يادگيری تحت سرپرستی نيازمند تعدادی داده ورودی به منظور آموزش سيستم است.
با اين حال ردهای از مسائل وجود دارند که خروجی مناسب که يک سيستم يادگيری تحت سرپرستی نيازمند آن است، برای آنها موجود نيست.
اين نوع از مسائل چندان قابل جوابگويی با استفاده از يادگيری تحت سرپرستی نيستند.
يادگيری تقويتی مدلی برای مسائلی از اين قبيل فراهم میآورد.
در يادگيری تقويتی(Reinforcement Learning)، سيستم تلاش میکند تا تقابلات خود با يک محيط پويا را از طريق خطا و آزمايش بهينه نمايد.
يادگيری تقويتی مسئلهای است که يک عامل که میبايست رفتار خود را از طريق تعاملات آزمايش و خطا با يک محيط پويا فرا گيرد، با آن مواجه است.
در يادگيری تقويتی هيچ نوع زوج ورودی- خروجی ارائه نمیشود. به جای آن، پس از اتخاذ يك عمل، حالت بعدی و پاداش بلافصل به عامل ارائه میشود.
هدف اوليه برنامهريزی عاملها با استفاده از تنبيه و تشويق است بدون آنکه ذکری از چگونگی انجام وظيفه آنها شود.
چرا یادگیری تقویتی برای Maze ها و ربات ها مناسب هست ؟
یکی از راههای یاد دادن و آموزش ربات استفاده از یادگیری تقویتی است در این روش حالتهای مختلفی برای ربات تعریف می شود و در هر حالت یک یا چند عمل ربات می تواند انجام دهد، به ازای اینکه ربات از یک حالت به کدام حالت بعدی برود یا کدام عمل بعدی را انتخاب کند مقداری پاداش یا تنبیه می گیرد.
در نهایت جدولی با استفاده از تمامی حالات بدست می آید ، پس از چندین سناریو اجرای ربات در محیطش نوبت به عمل می رسد این بار ربات با توجه به یادگیرهای قبلی و بر اساس جدولی که تهیه کرده اقدام به حرکت می کند. و در هر حالت عملی را انجام می دهد که بیشترین پاداش را در جدول داشته باشد .
یکی از زیرمجموعه های یادگیری تقویتی، Q-learning است .یادگیری تقویتی در یك بیان كلی یعنی با توجه به شناختی كه از محیط داریم و بر اساس نتایجِ تعاملاتی كه با محیط داشته ایم و سودها و زیانهایی كه در نتیجه انجامِ عملهای مختلف بدست آورده ایم، استراتژی را پیدا كنیم كه با عمل به آن در بلندمدت مطلوبیت خود را بیشینه كنیم .
یادگیری تقویتی (Reinforcement Learning) یکی از روش های یادگیری در سیستم های هوشمند است که براساس رابطه ی علت و معلولی عمل می کند.
در این روش یادگیری عامل هوشمند (Agent) با توجه به وضعیتی که در محیط دارد، عملی را بر روی محیط انجام می دهد و منتظر نتیجه ی عملش می ماند. این نتیجه می تواند در قالب یک پاداش یا تنبیه باشد.
اگر نتیجه در قالب پاداش باشد، عمل انجام شده مطلوب بوده و عامل به هدفی که در آن محیط دارد نزدیک شده است.
ولی اگر نتیجه در قالب تنبیه باشد، عمل انجام شده نامطلوب بوده و عامل از هدفش دور شده است. عامل باید یاد بگیرید که چه اعمالی را انجام دهد تا پاداش بیش تری را کسب کند و در نهایت به هدفش برسد.
همه ی ما در کودکی با الگویی مشابه یادگیری تقویتی راه رفتن را آموختیم.
زمانی که پس از چندین گام برداشتن به زمین می خوردیم (تنبیه)، سعی می کردیم اعمال حرکتی خود را به گونه ای اصلاح کنیم تا تعادل خود را به هنگام راه رفتن حفظ کنیم (پاداش).
در نهایت هم به هدف خود که راه رفتن بود رسیدیم.
در واقع هدف اصلي از يادگيري، يافتن شيو هاي براي عملكرد در حالات مختلف است كه اين شيوه در مقايسه با سايرين، با در نظر گرفتن معيارهايي، بهتر است. هنگامي ميتوان گفت يادگيري اتفاق افتاده است كه، عاملي بر اساس تجربياتي كه كسب مي كند به نحوي ديگر، و به احتمال زياد بهتر، عمل كند.
در اين صورت مي بايست نحوه ي عملكرد عامل در اثر كسب اطلاعات جديد، متفاوت از نحوه ي عملكرد در زمان هاي قبل از كسب اين اطلاعات و تجارب باشد. در يادگيري تقويتي، هدف اصلي از يادگيري، انجام دادن كاري و يا رسيدن به هدفي است، بدون آنكه عامل يادگيرنده، با اطلاعات مستقيم بيروني تغذيه شود.
در اين روش، تنها مسير اطلاع رساني به عامل، از طريق يك سيگنال پاداش يا جريمه مي باشد. تنها چيزي كه از طريق سيگنال پاداش به عامل فهمانده مي شود، اين است كه آيا تصميم مناسبي گرفته است يا نه؟ در بسياري از حيوانات، يادگيري تقويتي، تنها شيوه ي يادگيري مورد استفاده است.
همچنين يادگيري تقويتي، بخشي اساسي از رفتار انسا نها را تشكيل م يدهد. هنگامي كه دست ما در مواجهه با حرارت مي سوزد، ما به سرعت ياد مي گيريم كه اين كار را بار ديگر تكرار نكنيم.
لذت و درد مثالهاي خوبي از پاداش ها و جرايمي هستند كه الگوهاي رفتاري ما و بسياري از حيوانات را تشكيل مي دهند.
در يادگيري تقويتي، هيچ گاه به عامل گفته نميشود كه عمل صحيح در هر وضعيت چيست، و فقط به وسيله ي معياري، به عامل گفته مي شود كه يك عمل چقدر خوب يا چقدر بد است.
عامل موظف است، با در دست داشتن اين اطلاعات، ياد بگيرد كه بهترين عمل كدام است.
اين موضوع، بخشي از نقاط قوت خاص يادگيري تقويتي است.
از اين طريق، مسائل پيچيده ي تصميم گيري در اغلب اوقات مي توانند با فراهم كردن كمترين ميزان اطلاعات مورد نياز براي حل مسأله، حل شوند.
در اين شيوه از يادگيري، حتي در برخي موارد، ماهيت مسأله و هدف از حل آن نيز به طور كامل و مستقيم به عامل تفهيم نمي شود.
سيگنال پاداش، به طور ضمني نحو ه ي عملكرد مناسب را به عامل نشان مي دهد و هدف از حل مسأله را مشخص ميكند.
در اين حالت، هدف عامل از يادگيري به بيشينه كردن ميزان پاداش دريافتي در بازه اي از زمان، تغيير ميكند. اين دو هدف با هم مترادف هستند و برآورده شدن هركدام، ديگري را نيز برآورده خواهد كرد.
به اين طريق، عامل نحوه ي عملكرد مناسب را با تمركز بر پادا شهاي دريافتي، ياد ميگيرد.
اين امر به اين صورت محقق مي شود كه، نگاشتي ميان حالات و اعمالِ قابل انجام توسط عامل، پيدا ميشود.
اين نگاشت كه به نام سياست شناخته مي شود، به عامل مي گويد كه در مواجهه با حالات مختلف، چه عمل يا اعمالي را انجام دهد.
تبعيت از يك سياست خوب، قطعا عامل را به نتايج هاي مناسب خواهد رساند.
حالت های (States) یادگیری تقویتی : حالت بیان گر شرایط موثر بر تصمیم گیری عامل در محیط است مانند موقعیت مکانی عامل در محیط.
پاداش و تنبیه (Reward and Punishment): پاداش و تنبیه پس خوری (Feedback) است که عامل از محیط می گیرد و درواقع واکنش محیط نسبت به کنش ربات روی آن است.
تابع کیفیت(Quality Function) : تابع کیفیت نشان دهنده ی میزان بهینگی یک عمل در یک حالت نسبت به سایر اعمال در سایر حالات است.
در نتیجه این تابع هم به حالت وابسته است و هم به عمل Q(s, a). به عنوان مثال Q(s1, a2) میزان بهینگی عمل a2 را در حالت s1 بیان می کند.
تابع کیفیت به ما کمک می کند که در حالت فعلی عمل بهینه تر را انتخاب کنیم.
در طول فرآیند یادگیری، اعمال بهینه تر کیفیت بالا تری نسبت به سایر اعمال پیدا خواهند کرد که در ادامه با نحوه ی این کار آشنا می شویم.
سیاست های انتخاب عمل (Action Selection Policies):مسلما ما تمایل داریم سیاستی داشته باشیم که اعمال بهینه تر(با توجه به مقدار تابع کیفیت) همواره روی میحط اجرا شوند.
چنین سیاستی را استعمارگرانه (Exploiting) گویند.
اما در شروع فرآیند یادگیری که مقدار تابع کیفیت هنوز به مقدار بهینه اش نرسیده است، اخذ چنین سیاستی مشکل ساز خواهد بود.
زیرا ممکن است عمل بهینه ی نهایی ما در ابتدای یادگیری کیفیت کمی داشته باشد که طبق سیاست استعمارگرانه شانس زیادی برای انتخاب شدن ندارد.
همین امر سبب می شود این عمل بهینه منزوی بماند و تا آخر فرآیند یادگیری کشف نشود.
در نتیجه در ابتدای یادگیری باید سیاست کاوشگرانه (Exploring) داشته باشیم که در آن تمام اعمال با هر کیفیتی به یک اندازه شانس انتخاب شدن دارند.
سیاست کاوشگرانه تا آن جا ادامه می یابد که تشخیص دهیم تابع کیفیت به مقدار بهینه ی خود نزدیک شده است و اعمال بهینه کشف گردیده اند.
از آن پس می توانیم سیاست استعمارگرانه را پیش گیریم.
الگوریتم های متداول انتخاب عمل عبارت اند از:
- ε-greedy
- ε-soft
- softmax
الگوریتم ε-greedy : در این الگوریتم یک عدد کوچک ε بین صفر و یک تعیین می شود که میزان احتمال انتخاب شدن یک عمل به شکل تصادفی را بیان می کند.
فرضا” اگر مقدار ε را برابر 0.2 در نظر بگیریم، 0.2 احتمال دارد که عمل به شکل تصادفی انتخاب شود و 0.8 احتمال دارد که عملی انتخاب شود که بیش ترین کیفیت را نسبت با سایر اعمال دارد.
همچنین می توان ε را به شکل پویا تغییر داد.
بدین شکل که در شروع یادگیری مقدار آن زیاد باشد که سبب می شود احتمال انتخاب تصادفی نیز زیاد باشد و با جلو رفتن یادگیری مقدار آن کاهش یابد که باعث می شود احتمال انتخاب براساس کیفیت افزایش یابد.
روش softmax : احتمال انتخاب عمل a در tامين آزمايش برابر است با (توزيع احتمال بولتزمان):
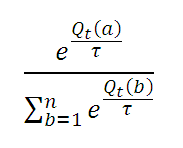
الگوریتم های یادگیری Temporal Difference (TD-Learning Algorithms)
حال وقت آن است که با نحوه ی نزدیک کردن تابع کیفیت به مقدار بهینه اش که اساس یادگیری ما را شکل می دهد آشنا شویم.
برای این کار از الگوریتم های یادگیری Temporal Difference استفاده می کنیم که طبق اختلاف بین پس خور و تابع ارزش (Value Function)، اعمال بهینه را در حالات مختلف حین یادگیری کشف می کنند. دو روش متداول جهت پیاده سازی این الگوریتم وجود دارد:
- الگوریتم Q-Learning
- الگوریتم SARSA
الگوریتم Q-Learning غالبا” تصمیم گیری بهینه تری نسبت به SARSA دارد در حالی که الگوریتم SARSA از تصمیم گیری پایدار تری برخواردار است و می تواند پاداش بیش تری را نیز کسب کند.
الگوریتم Q-Learning
ابتدا مقدار Q(s, a) را به ازای تمام حالات و اعمال برابر صفر در نظر می گیریم.
- حالت فعلی سیستم (s) را به دست می آوریم.
- براساس الگوریتم ε-greedy، یک عمل (a) را انتخاب می کنیم.
- عمل a را روی محیط انجام می دهیم و منتظر امتیاز عمل خود (r) می شویم.
- حالت جدید سیستم را که پس انجام عمل سیستم به آن می رود (s’) به دست می آوریم.
- براساس رابطه ی زیر مقدار Q(s, a) را به روز می کنیم:
Q(s, a) = Q(s, a) + α [r + γ.Qmax(s’, a’) – Q(s, a)]
- α عددی بین صفر تا یک است که نرخ یادگیری (Learning Rate) نام دارد و سرعت یادگیری را تعیین می کند.
- بدیهی است که هرچه مقدار α بیش تر باشد، سرعت یادگیری هم بالا تر می رود ولی باید توجه داشت که مقادیر بزرگ α یادگیری را ناپایدار می کند.
- در اکثر کاربرد ها معمولا” مقدار 0.1 برای نرخ یادگیری پیشنهاد می شود. γ عددی بین صفر تا یک است که نرخ تنزیل (Discount Factor) نام دارد و مانع از واگرایی تابع کیفیت حین یادگیری می شود. مقدار γ را معمولا” برابر 0.9 در نظر می گیرند.
- Qmax(s’, a’) کیفیت بهینه ترین عمل در موقعیت جدید سیستم یعنی s’ است. به عبارتی این مقدار بیشینه ی کیفیت در موقعیت s’ به شمار می آید.
در آخر بررسی می کنیم که عامل به هدف خود دست یافته است یا خیر.
اگر پاسخ منفی بود، الگوریتم از مرحله ی سوم براساس موقعیت s’ دوباره تکرار می شود. در غیر این صورت الگوریتم خاتمه می یابد.
الگوریتم SARSA (State-Action-Reward-State’-Action’)
ابتدا مقدار Q(s, a) را به ازای تمام حالات و اعمال برابر صفر در نظر می گیریم.
- حالت فعلی سیستم (s) را به دست می آوریم.
- براساس الگوریتم ε-greedy، یک عمل (a) را انتخاب می کنیم.
- عمل a را روی محیط انجام می دهیم و منتظر امتیاز عمل خود (r) می شویم.
- حالت جدید سیستمرا که پس انجام عمل سیستم به آن می رود (s’) به دست می آوریم.
- در موقعیت جدید (s’) براساس الگوریتم ε-greedy، یک عمل جدید (a’) را انتخاب می کنیم.
- براساس رابطه ی زیر مقدار Q(s, a) را به روز می کنیم:
Q(s, a) = Q(s, a) + α [r + γ.Q(s’, a’) – Q(s, a)]
در آخر بررسی می کنیم که عامل به هدف خود دست یافته است یا خیر.
اگر پاسخ منفی بود، الگوریتم از مرحله ی سوم براساس موقعیت s’ و عمل a’ دوباره تکرار می شود. در غیر این صورت الگوریتم خاتمه می یابد.
یادگیری تقویتی
یادگیری تقویتی از اینرو مورد توجه است که راهی برای آموزش عاملها برای انجام یک عمل از طریق دادن پاداش و تنبیه است بدون اینکه لازم باشد نحوه انجام عمل را برای عامل مشخص نمائیم.
- دو استراتژی اصلی برای اینکار وجود دارد:
-
- یکی استفاده از الگوریتم های ژنتیکی و دیگری استفاده از روشهای آماری و dynamic programming
-
- در RL روش دوم مد نظر است.
- محیط مجموعه ای از S حالت ممکن است.
- در هر لحظه t عامل میتواند یکی از A عمل ممکن را انجام دهد.
- عامل ممکن است در مقابل عمل و یا مجموعه ای از اعمالی که انجام میدهد پاداش r را دریافت کند.
- این پاداش ممکن است مثبت و یا منفی )تنبیه(باشد
![robot_665[1]](https://www.matlabi.ir/wp-content/uploads/2017/10/robot_6651.png)
- عامل در محیط حرکت کرده و حالتها و پاداشهای مربوطه را به خاطر می سپارد.
- عامل سعی میکند طوری رفتار کند که تابع پاداش را ماکزیمم نماید.
- پاداش Rt مجموع پاداشی است که عامل با گذشت زمانt جمع کرده است.
المانهاي اصلي در يادگيري تقويتي
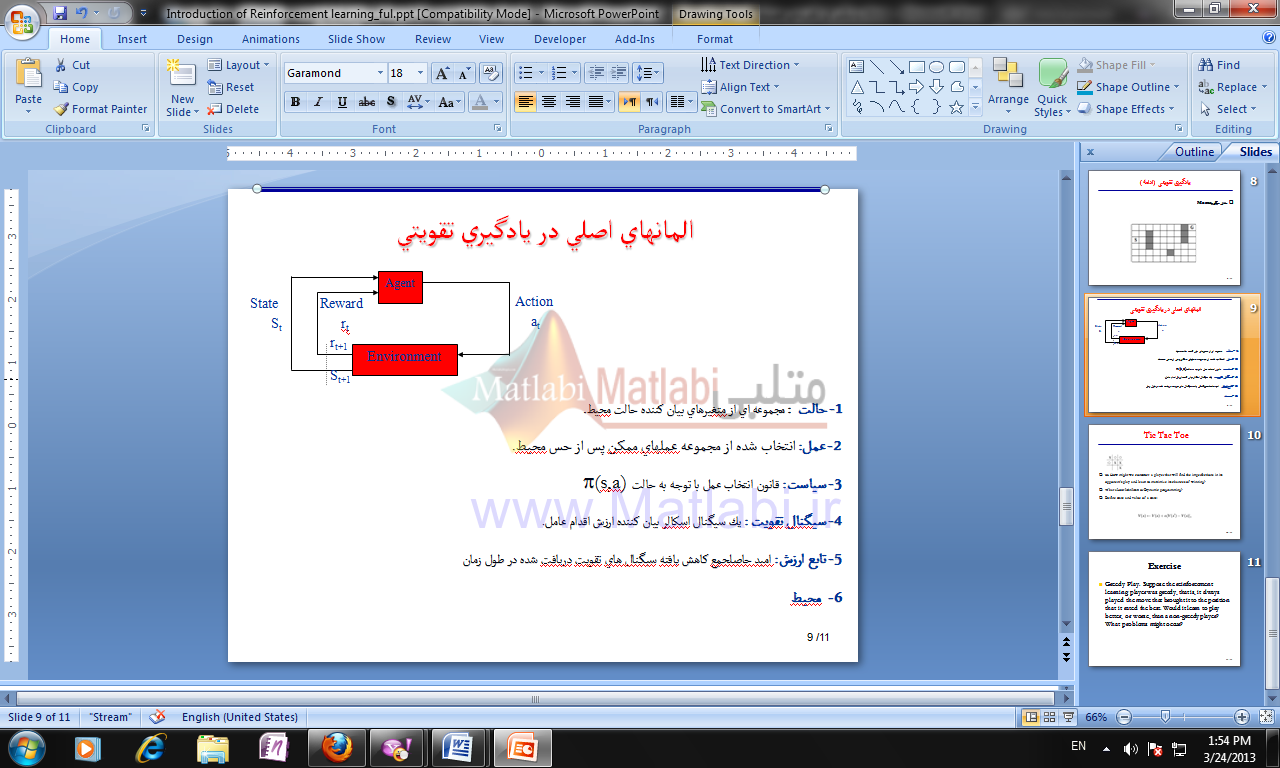
1- حالت : مجموعه اي از متغيرهاي بيان کننده حالت محيط.
2- عمل: انتخاب شده از مجموعه عملهاي ممكن پس از حس محيط.
3- سياست: قانون انتخاب عمل با توجه به حالت (s,a)
4- سيگنال تقويت : يك سيگنال اسکالر بيان کننده ارزش اقدام عامل.
5- تابع ارزش: اميد حاصلجمع کاهش يافته سيگنال هاي تقويت دريافت شده در طول زمان
- محيط : در RLعامل یادگیر بطور سعی و خطا با یک محیط پویا درگیر شده و یاد می گیرد که برای هر موقعیت چه عملی را انجام دهد. این محیط باید قابل مشاهده ویا حداقل تا قسمتی قابل مشاهده برای عامل باشد(partially observable). مشاهده محیط ممکن است از طریق خواندن اطلاعات یک سنسور، توضیح سمبلیک و غیره باشد. در حالت ایده ال عامل باید بطور کامل قادر به مشاهده محیط باشد زیرا اغلب تئوریهای مربوطه بر اساس این فرض بنا شده اند
روش های حل با کد:
قبل از اجرای کدها برای نمایش بزرگ نقشه لطفا تنظیم زیر انجام شود
Fileperefernce–>Image Processing Fit to Window
روش اول: روش تصادفی
این الگوریتم یک روش ضعیف است که به وسیله ی ربات های غیر هوشمند یا موش قابل اجراست، اما تضمینی برای رسیدن به هدف وجود ندارد.
در این الگوریتم یک مسیر مستقیم طی می شود تا به اولین مانع برسد، سپس یک مسیر تصادفی (چپ یا راست) را برای ادامه انتخاب می کند.
این الگوریتم در صورتی که خروجی به صورت یک سوراخ در میانه ی دیوار باشد، با شکست مواجه می شود.
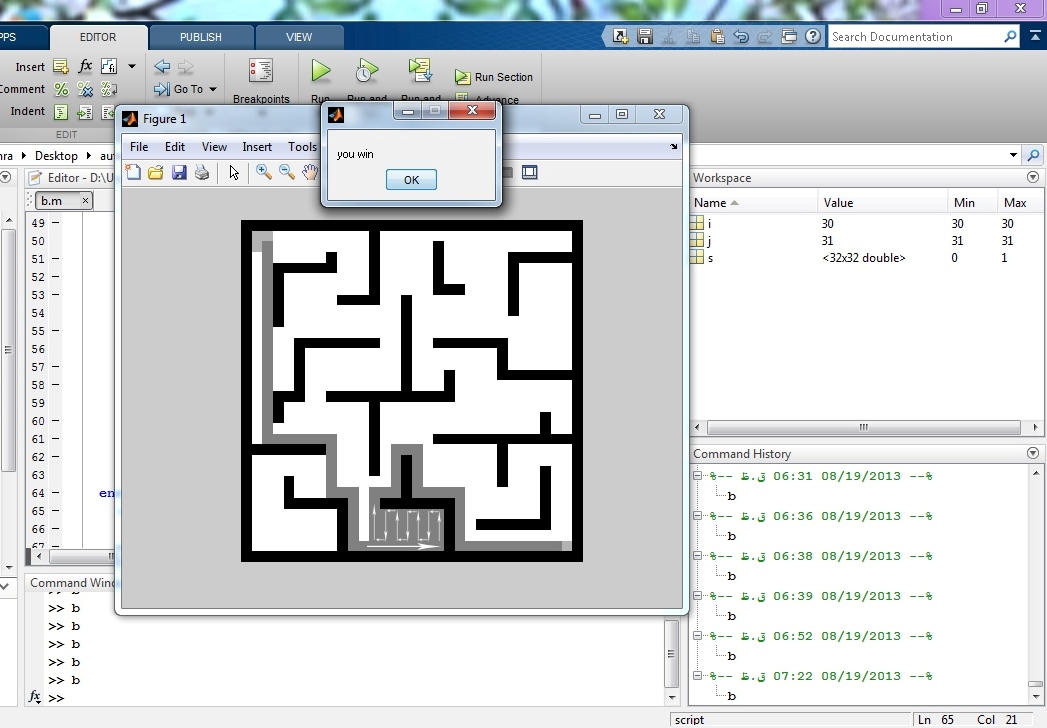
این روش زمان بر است و ممکن است هیچوقت به نتیجه نرسد. البته در این ماز مسیر را پیدا کرده و به خروجی می رسد.
| کد روش تصادفی |
| … |
نتیجه کار:
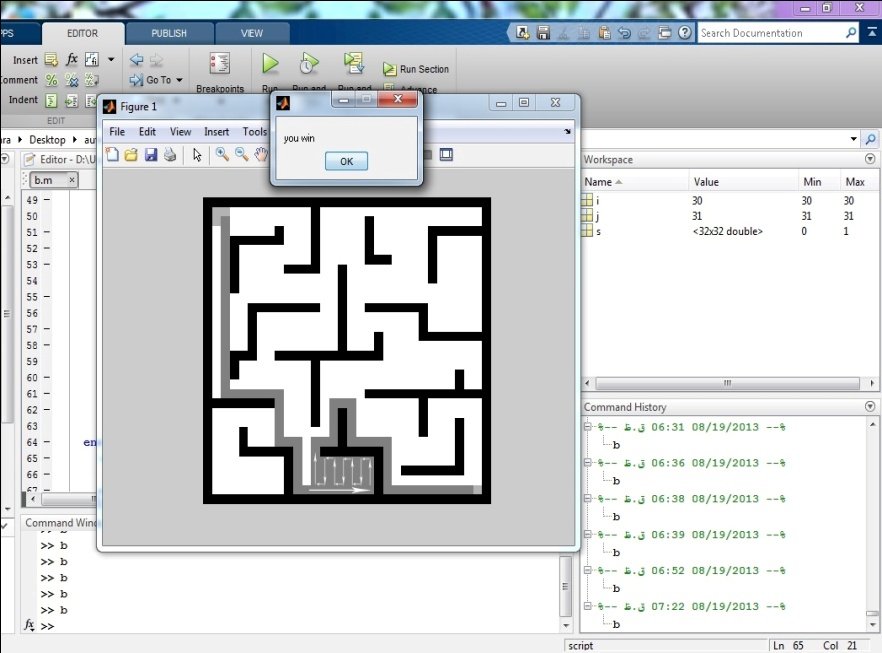
روش دوم:روش الگوریتم دنبال کردن دیواره ها (wall follower)
در این الگوریتم کافی است دست راست یا چپ خود را به دیواره بگیرید و بدون این که دست از دیوار جدا شود، به مسیر ادامه دهید.
این الگوریتم بهترین روش پیمودن ماز است، اگر ماز ساده باشد، یعنی همه ی دیواره ها به یکدیگر یا فضای بیرونی ماز متصل باشند، این تضمین وجود دارد که با حفظ تماس یک دست به دیواره ای که از آن شروع به حرکت می کنیم، بتوان از ماز خارج شد.
ولی اگر ماز ساده نباشد، این الگوریتم به یافتن خروجی در قسمت های گسسته کمکی نمی کند.
در مازهایی که هدف در وسط قرار دارد و بخشی از دیواره ی هدف را پوشش داده است، کاربردی ندارد.
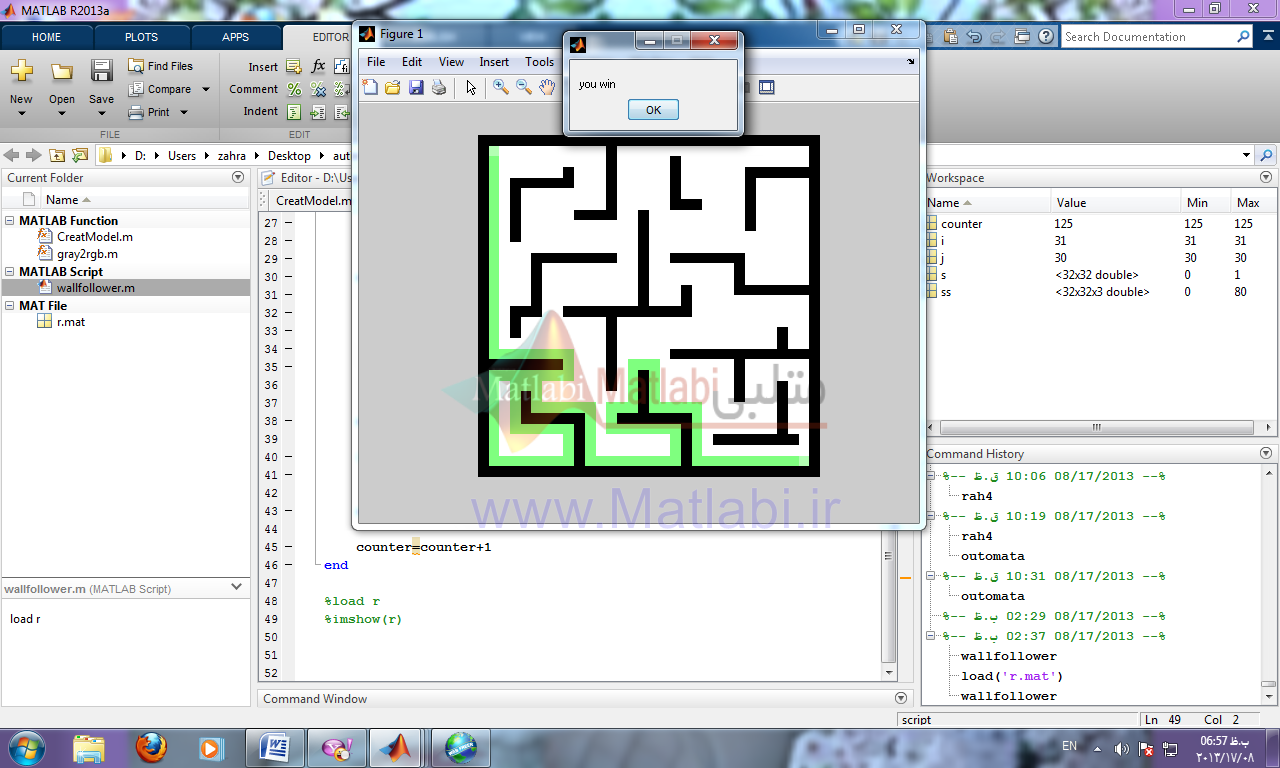
در این روش از قانون دست راست استفاده کرده و کد آن را برای ماز داده شده نوشتم.
| کد الگوریتم (wall follower) |
| …
|
| توضیحات کد و کد متلب در گزارش آمده است. |
نتیجه راه حل:
راه حل سوم: وزندهی دستی
روش سوم به این صورت که خودمان دستی همسایگان را ارزش گذاری کنیم و مسئله به صورت انتخاب بزرگترین همسایه دارای ارزش بالاتر انتخاب و به جلو حرکت می کند .
| کد الگوریتم |
| … |
نتیجه کار:
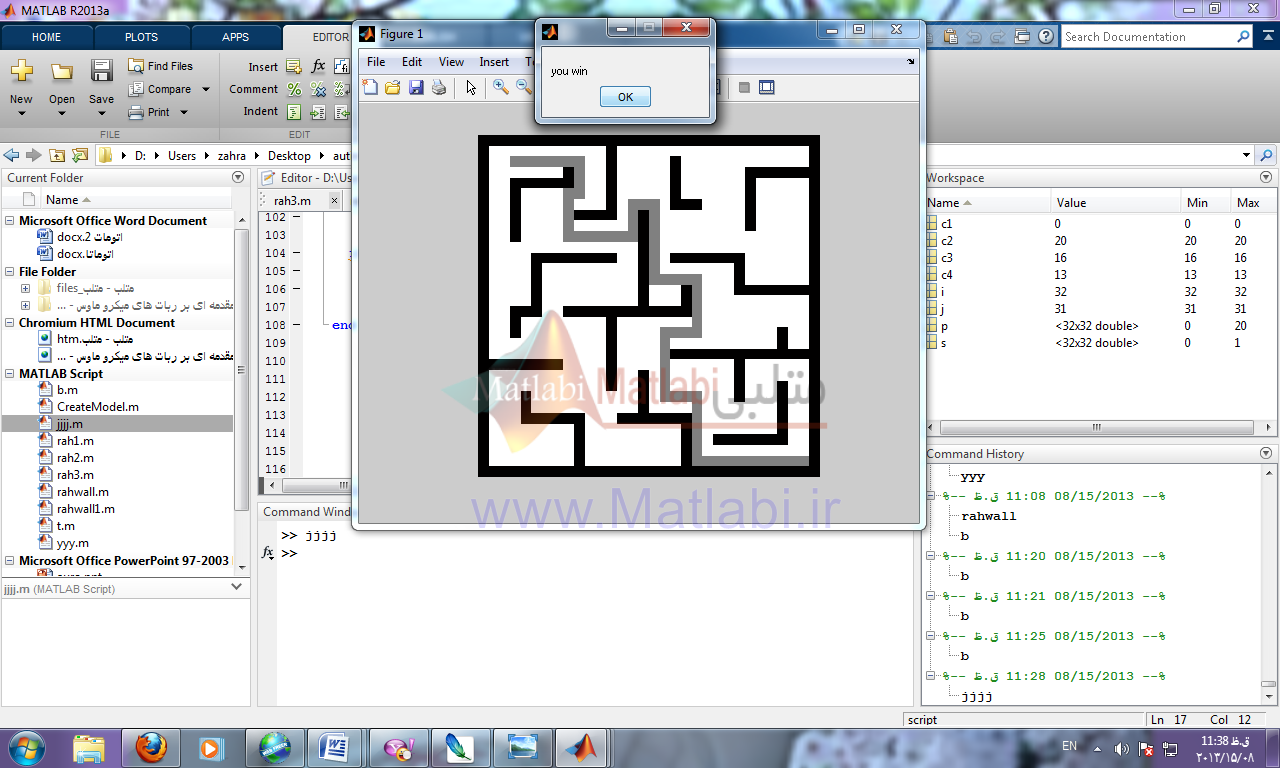
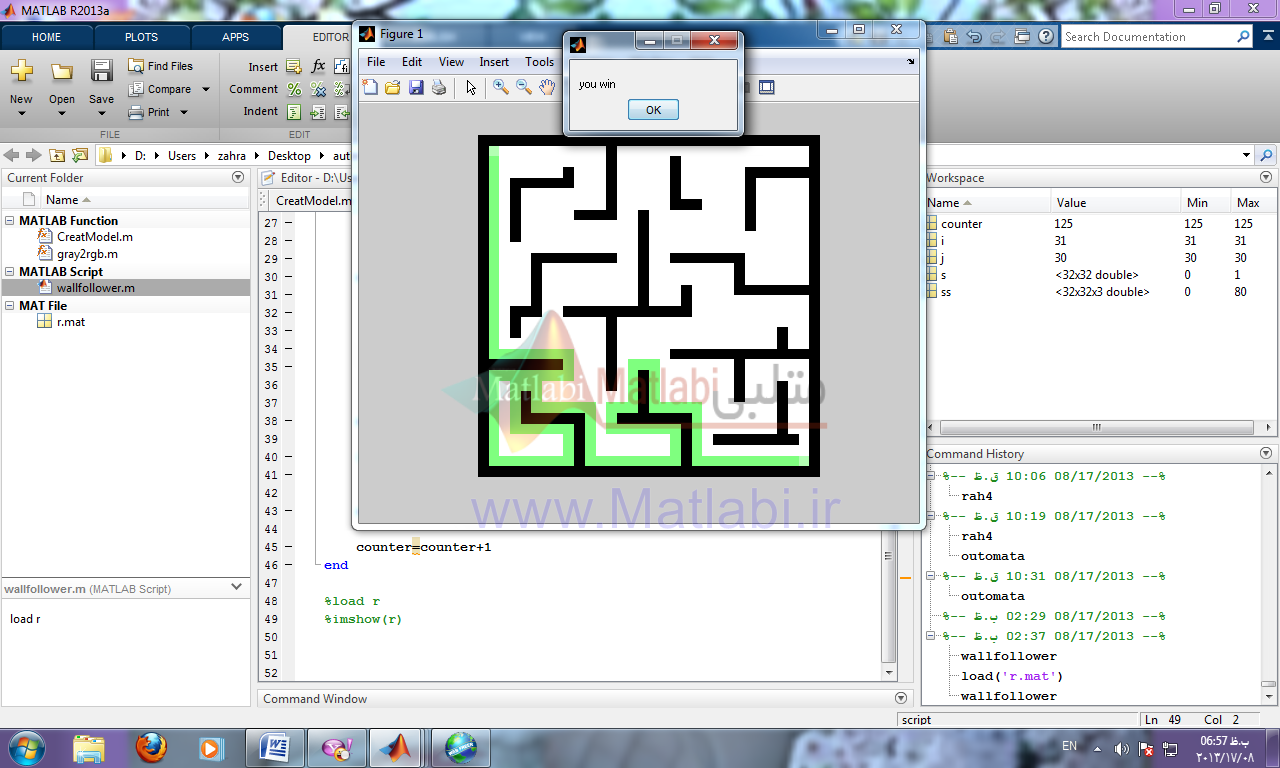
راه حل چهارم:حل با اتوماتاها
…
دارای یک همسایه :ابتدا وزن هر سلول از maze با توجه به تصاویر زیر برایش در نظر میگیرد هر خانه ای با توجه به تعداد همسایگان در یک ماتریس امتیاز دهی می شود.
…
و…
دارای دو همسایه :
…
دارای سه همسایه :
و…
دارای چهار همسایه :
و…
دارای پنج همسایه :
و…
دارای شش همسایه :
و…
دارای هفت همسایه :
و…
دارای هشت همسایه :
…
همسایه ای که بیشترین مقدار وزن را دارد به عنوان وضعیتی یا State ای که موقعیت خود را به آن تغییر دهیم.
اگر بین همسایه ها مقدار وزنها برابر بود همسایه ای که از مبدأ بیشتر دور شده است به عنوان وضعیت موردنظر انتخاب می شود و جریمه و پاداش به این صورت هست که همسایه ای که بیشترین وزن دارد و بیشترین فاصله دور شدن از مبدا دارد به احتمال انتخاب آن اضافه شده مقداری به عنوان پاداش اضافه (در اینجا 0.2+) و از احتمال انتخاب شدنش همسایگانش مقداری به عنوان جریمه (در اینجا 0.1-) کم می شود.
فرمول فاصله موقعیت الان با موقعیت مبدأ :
(2و2)= موقعیت مبدا
(I,j)= موقعیت کنونی
L(I,j)=sqrt((i-2)^2+(j-2)^2)
احتمال انتخاب هر خانه= احتمال قبلی +نرخ پاداش یا جریمه ای که در موقعیت فعلی کسب می کند (وزن آن خانه با توجه به وضعیت هماسایگانش و فاصله اش از مبدأ)
که بعد از چند مرحله اجرا ربات با توجه با ماتریس احتمالات یاد میگرد که کدام مسیر مناسب هست برای پیمودن تا رسیدن به مقصد.
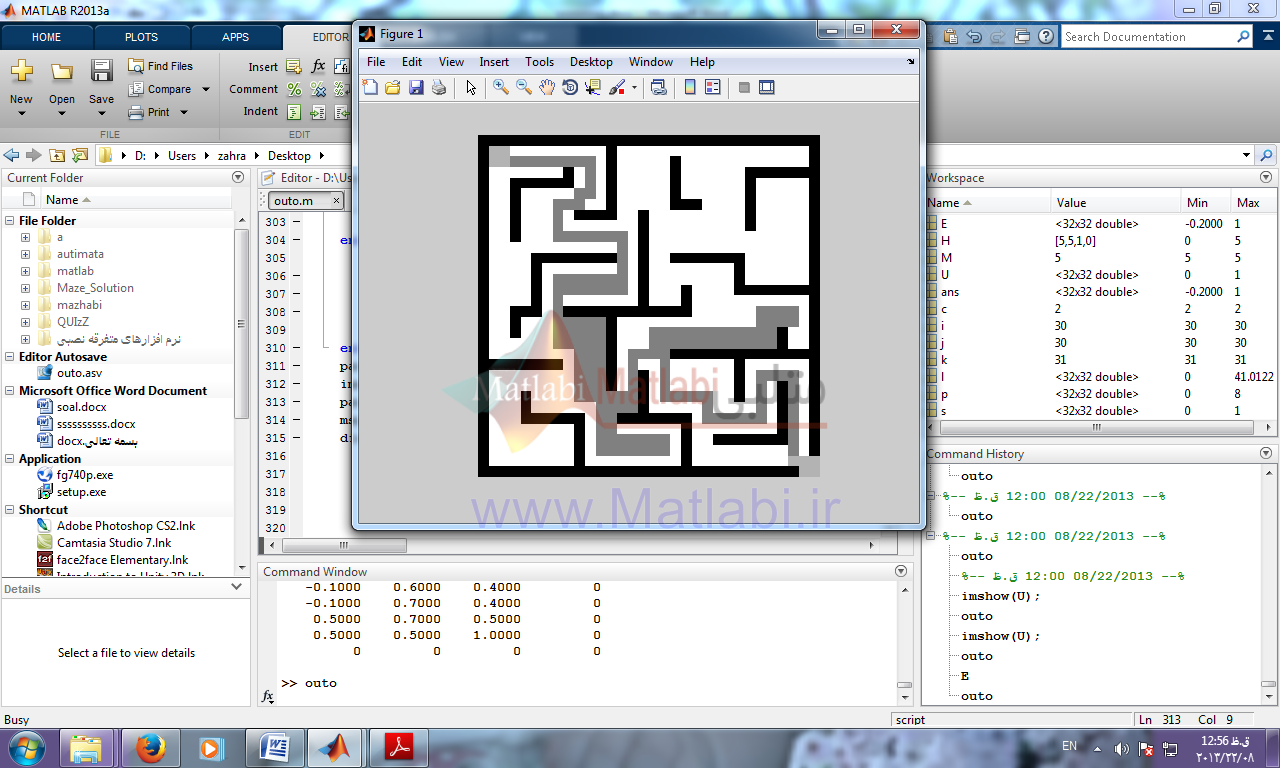
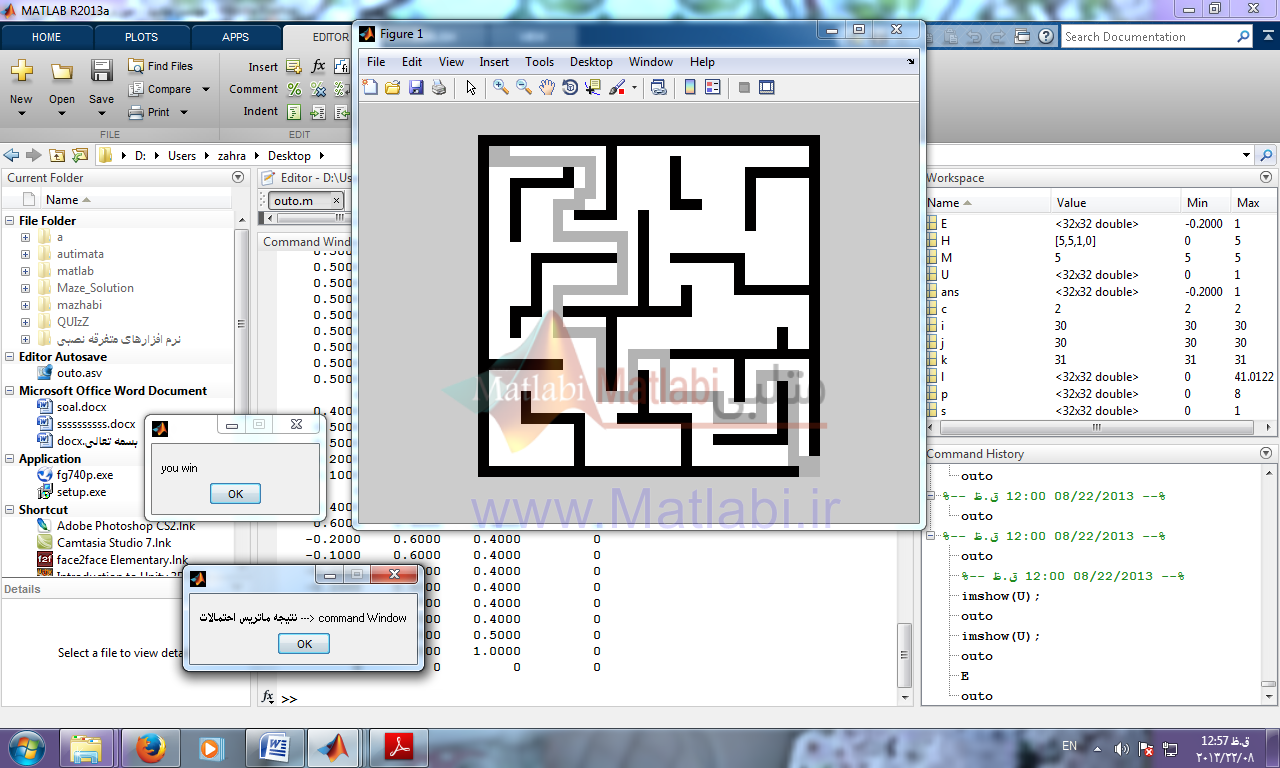
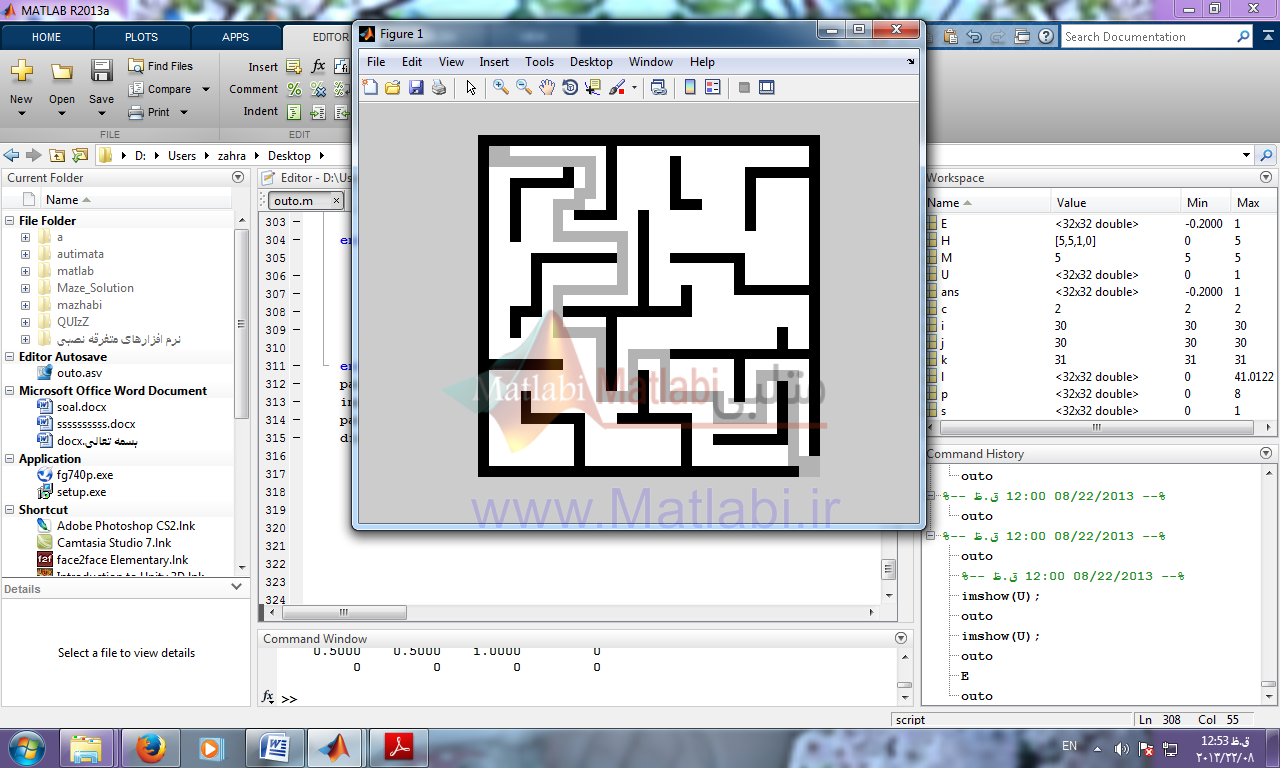
| کد الگوریتم حل Maze با اتوماتا |
| …
|
نتیجه کار:
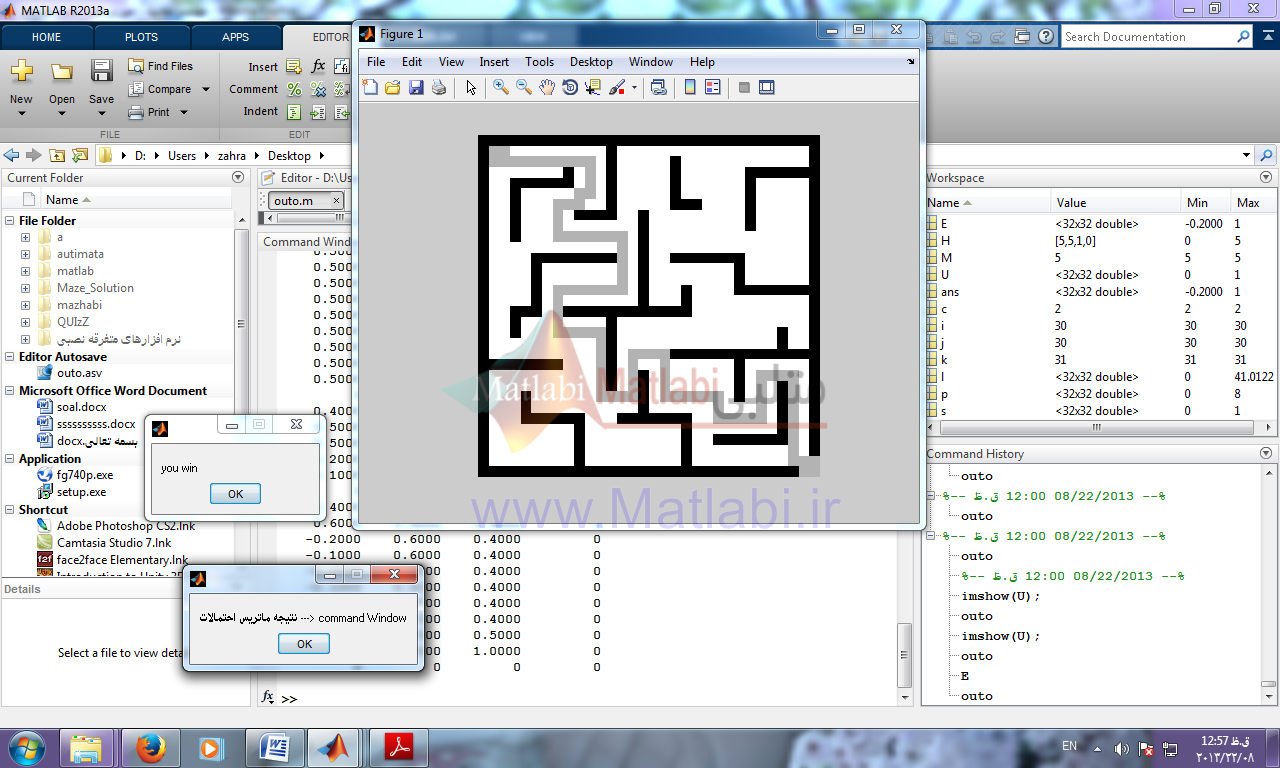
مقایسه سه روش: تصادفی- دنبال کننده دیوار – حل با اتوماتا
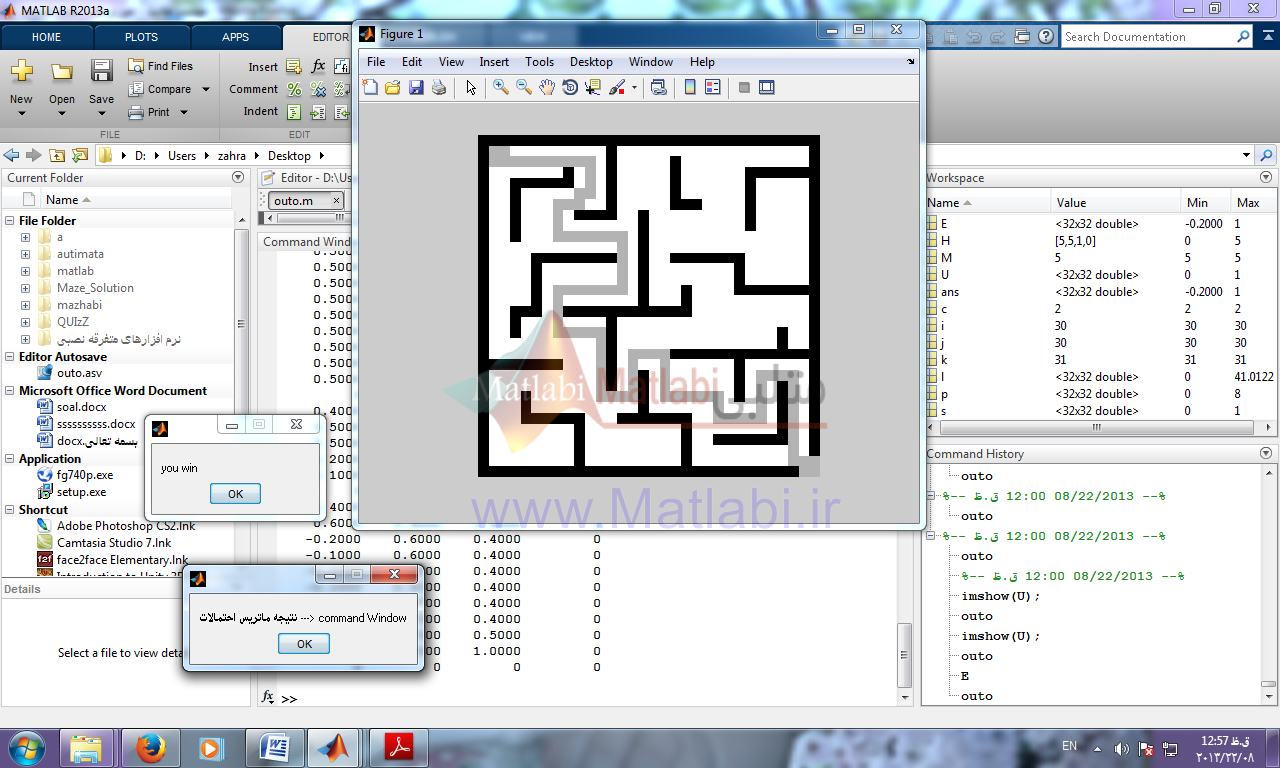
روش تصادفی روش دنبال کننده دیوار روش اتوماتاها
روش تصادفی یک روش ضعیف است که به وسیله ی ربات های غیر هوشمند یا موش قابل اجراست، اما تضمینی برای رسیدن به هدف وجود ندارد.
همانطور که گفته شد در این الگوریتم یک مسیر مستقیم طی می شود تا به اولین مانع برسد، سپس یک مسیر تصادفی (چپ یا راست) را برای ادامه انتخاب می کند.
این الگوریتم ممکن با توجه اینکه هدف کجا قرار گرفته در مواقع زیادی با شکست مواجه می شود و این روش زمان بر است و ممکن است هیچوقت به نتیجه نرسد.
البته در این ماز مسیر را پیدا کرده و به خروجی می رسد.
رو ش دنبال کننده دیوار کافی دست راست یا چپ خود را به دیواره می گیریم و بدون این که دست از دیوار جدا شود، به مسیر ادامه دهید.
اگر ماز ساده باشد، یعنی همه ی دیواره ها به یکدیگر یا فضای بیرونی ماز متصل باشند، این تضمین وجود دارد که با حفظ تماس یک دست به دیواره ای که از آن شروع به حرکت می کنیم، بتوان از ماز خارج شد.
ولی اگر ماز ساده نباشد، این الگوریتم به یافتن خروجی در قسمت های گسسته کمکی نمی کند.
در مازهایی که هدف در وسط قرار دارد و بخشی از دیواره ی هدف را پوشش داده است، کاربردی ندارد.
در این روش از قانون دست راست استفاده کرده و به هدف رسیده ایم.
روش حل مسئله با اتوماتا در این روش ابتدا وزن هر سلول از maze با توجه به تعداد و موقعیت همسایگان محاسبه شده و هر سلول به عنوان وضعیت جدید بالقوه در یک ماتریس امتیاز دهی و ارزش گذاری می شود.
وضعیت ها یکی از همسایگان بالا، پایین، چپ، راست می باشد و اکشن ها حرکت به یکی از این وضعیت ها می باشد همسایه ای که بیشترین مقدار وزن را دارد به عنوان وضعیتی یا State ای که موقعیت خود را به آن تغییر دهیم و اگر بین همسایه ها مقدار وزنها برابر بود همسایه ای که از مبدأ بیشتر دور شده است به عنوان وضعیت موردنظر انتخاب می شود و جریمه و پاداش به این صورت هست که همسایه ای که بیشترین وزن دارد و بیشترین فاصله دور شدن از مبدا دارد به احتمال انتخاب آن اضافه شده مقداری به عنوان پاداش اضافه (در اینجا 0.2+) و از احتمال انتخاب شدنش همسایگانش مقداری به عنوان جریمه (در اینجا 0.1-) کم می شود.
و فاصله هر سلول با موقعیت مبدا و دور شدن از مبدا محاسبه شده با فرمول گفته شده.
احتمال انتخاب هر خانه= احتمال قبلی +نرخ پاداش یا جریمه ای که در موقعیت فعلی کسب می کند (وزن آن خانه با توجه به وضعیت هماسایگانش و فاصله اش از مبدأ) که بعد از چند مرحله اجرا ربات با توجه با ماتریس احتمالات یاد میگرد که کدام مسیر مناسب هست برای پیمودن تا رسیدن به مقصد.
با توجه به اینکه به هرحال یا ارزش یکی از همسایه ها و یا موقعیت و فاصله شان از مبدا بزرگتر خواهد بود تضمینی برای پیدا کردن مقصد در این حالت داریم و هرچقدر الگوریتم به جلو پیش برود احتمال و ارزش خانه های درستتر با توجه به پاداش و جریمه بیشتر خواهد شد.
و خانه های کم ارزش موقعیتی برای انتخاب به عنوان مسیر نخواهند داشت.
کلید واژه:wall follower, random maze,,maze ,Tremaux, recursive back tracker, Pledge
شبیه سازی
اتوماتای یادگیر
طراحی خودرو هوشمند که از موانع بتواند عبور کند و خود را به مکان خروج برساند
توسط کارشناسان سایت متلبی انجام شده است و به تعداد محدودی قابل فروش می باشد.
سفارش انجام پروژه مشابه
درصورتیکه این محصول دقیقا مطابق خواسته شما نمی باشد،. با کلیک بر روی کلید زیر پروژه دلخواه خود را سفارش دهید.



دیدگاهها
هیچ دیدگاهی برای این محصول نوشته نشده است.